Highlights of NeurIPS 2023 from Reading All 3584 Abstracts
Just me reading through every paper abstract...
Introduction
To celebrate the end of my graduate school application deadlines and finals week disaster, I decided to spend my winter break going through and reading every single abstract of the accepted papers in the NeurIPS 2023 (which I unfortunately couldn’t attend). It was a long and sometimes mind-numbing process (especially since the TeX wasn’t rendering on the neurips.cc website), but it was really cool to see all these works and ideas that I had no idea were being done. Luckily, I am somewhat familiar with quite a number of these papers because they popped off on arXiv or Twitter when they were first announced, so I wasn’t discovering every single paper for the first time. Here is just a highlight of what I found interesting and the general vibes I had while reading over the last two weeks, but keep in mind that I am an undergraduate student that has not worked with or spent a lot of time with a variety of popular topics (e.g. federated learning, differential privacy, causal inference). I’ve structured this post into a high-level overview for each topic of what I observed, followed by short discussions on papers I found interesting. Each discussion is loaded with references to the relevant NeurIPS papers, and I’ve tried to ensure that almost every citations in this post are from NeurIPS 2023. If you want to read the abstracts on your own, they’re available publicly at https://neurips.cc/virtual/2023/papers.html. Finally, I ended up searching up so many terms, I eventually started keeping track of them in case the curious reader wants to know at the bottom of this post.
The Overall Vibes
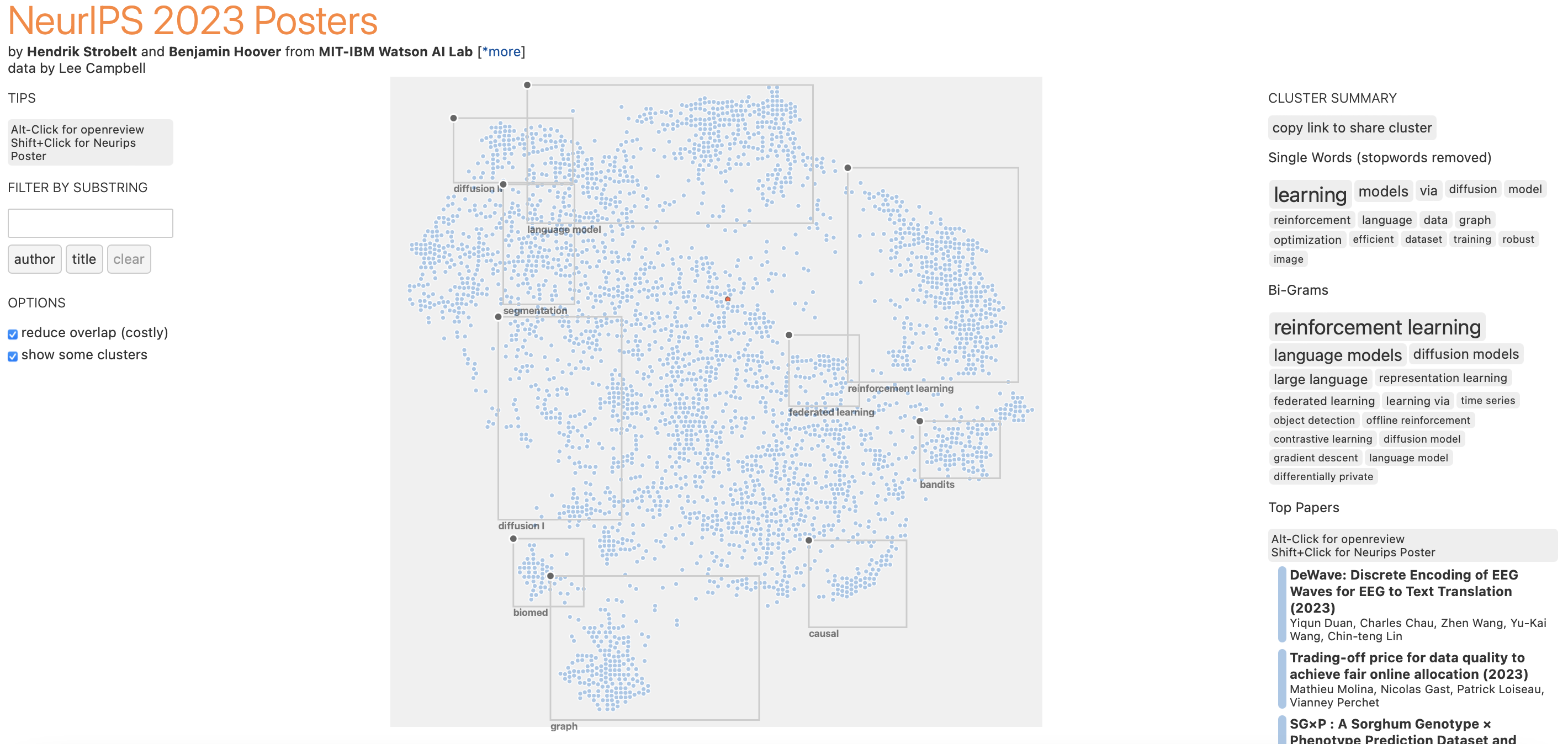
2023 was a great year for AI (generative models especially), and the number of submissions to NeurIPS 2023 reflects that. This year, there were 3584 accepted papers out of an astonishing 12345 submissions. Honestly, I expected to go into this process marking only my top 10 or 20 favorite papers, but I discovered so many absolutely fascinating works on the most random things like applying 3D neural rendering methods to Unreal Engine. By the end of this process, I ended up reading or skimming probably 50 or so of the papers (excluding the ones that I had seen before). Of course, from the abstract alone, it is not possible to grasp the quality or impact of a work, and in an ideal world I would have read each paper in their entirety and tried their code as well. Regardless, after reading through, these are some things that stuck out to me this year:
-
Multimodal is the new “thing”. Rather unsurprisingly, combining vision and language is a hot topic
. With LLMs demonstrating impressive performance in the past few years, leveraging these models to reason over visual data is a natural progression of the technology. -
In-context Learning (ICL) belongs everywhere. Anything that even resembles a transformer should exhibit in-context learning, whether its a diffusion model
, for RL , or even for generic regression . I wonder what’ll happen when more gradient-free learning methods like hyperdimensional computing https://arxiv.org/abs/2111.06077 take off… -
Diffusion models are really good at generating things. Diffusion models are getting so good at generating stuff, it seems like people are confident that they can be used for synthetic data
. There is a lot of exploration into using diffusion for more than just de-noising and text-to-image generation . -
Leveraging model priors. Foundation models are a blessing because they contain so much information about a specific domain. Leveraging these models beyond just in-domain downstream tasks is going to be extremely important to understand for the next few years, especially concerning data multiple modalities
. We also want to understand how to use the information present in these models in an interpretable way. - Model robustness. We want to be able to trust our models, and this means that our models behave according to our expectations. These models should also be robust to malicious actors and data, and should not leak our information, especially if we continue to feed them with our data. There are many tradeoffs and metrics for model robustness, so identifying the upper bounds both theoretically and empirically are important.
-
What does it mean to be similar? How do we measure similarity being two “concepts”? Or even just semantics? An intuitive way is to use similarity metrics like inner products over an embedding space, but how do we know that this embedding space is truly representative of the data
? Do we measure similarity in terms of probability distributions, or do we use mutual information ? -
When are inductive biases useful? We don’t necessarily always have the luxury of being able to scale our models and datasets for every domain, and we don’t know whether or not our models should not use inductive biases
. We want to understand whether we can leverage our own understanding of problems to introduce effective inductive biases like symmetry to solve problems .
Large Language Models
This is the section of papers I was most familiar with before reading through the abstracts. Generally, there have been a lot of works exploring the reasoning capabilities of LLMs through prompting or fine-tuning. I think the LLM papers at this conference reflect the interests of the NLP community for the past year even though a lot of these works can be considered at least a year old at this point (which in this field is old!). One general gripe I have with these works is that they often like to make claims about general LLM behavior, but often evaluate on an arbitrary LLM of their choosing. It would be nicer if there was some consistency here, but it’s probably because the field is so fast-moving combined with the fact that many models are just inaccessible to 95% of labs. There is also this interesting interplay of whether data purity or extra machinery is the driving factor towards improving performance. These are the general themes that I’ve noticed:
-
Reasoning. How can we apply algorithms or intuitions to fine-tune
LLMs to be better planners, reasoners, etc. like in
? Furthermore, how can we explicitly improve their reasoning capabilities without gradient updates like in ? -
Logical Reasoning. Can LLMs be used for logical tasks like mathematics
and coding ? What are the pitfalls and potential solutions? We are interested in analyzing the limits of their abilities, as well as understand why and when they fail . -
Agents. Can LLMs be considered cognitive agents? That is, can we
equip them with capabilities (tools, externals APIs
, etc.) such that they can interact with environments through text generation? Furthermore, can they interact, think, and reflect in an anthropomorphic way? -
Efficiency. A key bottleneck in autoregressive LLM inference on GPUs is data movement, so research into circumventing this issue by exploiting parallelism and cached data is key (e.g. speculative decoding)
. Furthermore, can we improve the speed and cost of both training and inference on LLMs at both a systems-level (e.g. take advantage of properties of GPU memory footprints and throughput speeds) and model-level (low-rank fine-tuning, adaptors, sparsity, etc.) ? -
Scaling and Fine-tuning Models. What advances can we make to push the capabilities of foundation models (e.g. MoE)
? What procedures can we use to efficiently fine-tune these models for downstream tasks or direct their generations towards user-aligned behavior (also can we do this without reinforcement learning (RL) ) ? Or, what techniques can we use to bridge the gap between smaller models and huge models? Also, what kind of scaling laws can we identify between model parameters and data ? -
Memory and Context Windows. The context window of an LLM is inherently limited by memory constraints and the quadratic runtime of the standard attention mechanism. How do we increase the size of the input context window without degrading performance? The primary methods that are being investigated are external memory stores in LLMs to process huge chunks of texts like a book
and summarization tokens . -
Emergent Capabilities. It has been observed that LLMs seem to be suddenly able to perform tasks after scaling up to a certain point. Can we characterize these emergent abilities of LLMs effectively and why we observe them
? -
Controlling Generation. Can we 1) hard constrain the outputs and 2) steer LLM generations to be what we want? Typically (2) has been done with instruction-tuning and RLHF
Reinforcement Learning with Human Feedback, an application of reinforcement learning to further fine-tune language models to better reflect our human preferences. Recommend reading this source: https://huggingface.co/blog/rlhf , but methods likelearns a smaller auxiliary model to edit the prompt of the larger model, which we can effectively treat as a set of parameters. Furthermore, what methods can we come up with to ensure preference-based alignment is accurate and robust -
LLMs can do [insert task]. How far can we go with zero-shot, few-shot, and in-context
learning (ICL) to mimic known algorithmic procedures
entirely through prompting? For example, policy iteration from RL -
Evaluating Language Models. What kind of metrics and
benchmarks are needed to effectively evaluate the abilities of different LMs? Is it by using a strong LLM as a judge
? Also, we generally just want more benchmarks for evaluating abilities like factuality , coding , and domain-specific information .
[LLM] Interesting Papers
Below is a list of papers I particularly liked and think are worth reading in their entirety. Of course, there were plenty of other extremely interesting and useful works at this conference, so please do not take this as some kind of definitive ranking of papers. Also, I’m mainly going to be giving a brief sentence about why I think each paper is cool/important and not a tldr, as I think you can get a lot more out of just reading it yourself. I have included this type of subsection at the end of every topic, so enjoy!
-
Tree-of-Thoughts
: A simple yet highly useful idea, tree-of-thoughts (ToT) is simply an extension of chain-of-thoughts where a model can now traverse through its own “thought” chains as a tree. This simple application of graph traversal to CoT (which also gives beam search vibes) has been used extensively for prompting in the last year. This paper actually came from my PI’s lab :) -
Toolformer
: Another well-known and simple approach, Toolformer is an extremely general framework for fine-tuning a model to be able to use user-specified APIs like a calculator or a search engine. It’s really practical and their experiments use GPT-J https://huggingface.co/docs/transformers/model_doc/gptj , so it’s quite easy to replicate for your own use cases. -
Are Emergent Abilities of Large Language Models a Mirage?
: I remember this paper being widely debated when it came out, with many arguing that the author’s conclusion was not indicative of anything useful. I think this paper makes a great point, in that emergent capabilities are a consequence of the evaluation metrics we choose to measure abilities, even if these evaluation metrics are natural (e.g. % of math questions answered). The problem with relying on intuitive of pre-existing metrics is that they don’t tell the full picture about scale vs. performance. I’ll put it like this. Suppose our LLM has never been able to solve task A. No matter how we have scaled it so far, it can never solve A. Scaling is expensive, so an important question is whether scaling will lead to emergent capabilities on A. Instead, if we have an auxiliary task B that is indicative of solving A, we can measure the relationship between scale and performance on A by looking at performance on B. The usefulness of reframing is to hopefully find metrics that show linear relationships between things like scale and downstream task performance, but this is still hard to do. -
SPRING: Studying Papers and Reasoning to Play Games
: This paper is exciting to me because I am very interested in models that can utilize external sources of information in an intuitive way. Outside of their reasoning module, they read information using an LLM from a game manual (honestly I don’t really get why they use the LaTeX source though, maybe for equations?) and store it as context for their agent (also an LLM). The point is that an LLM can act as a retriever and can intuit about what information is relevant. I think that this work is in a very preliminary stage though, and there is a lot of future research to be done in generalizing this type of framework. -
RapidBERT: Pretraining BERT from Scratch for $20
: This paper is kind of crazy… With lots of modern tricks (FlashAttention , ALiBi , low-precision layernorm, etc.) they can pre-train a BERT with the same performance as the original in just 9 hours on an A100. I think it goes to show far how we’ve gone in optimizing our language models. It is also important to note that they use a more modern scraped dataset in this paper (C4 https://github.com/allenai/allennlp/discussions/5056 ) for pre-training. -
Scaling Data-Constrained Language Models
: Understanding the relationship between model scale and data scale is important, and this paper looks into scaling laws under limited amounts of unique data. In their experiments, they found that repeating data during training works but diminishes in performance compared to using completely unique data. As an aside, their results focus on cross-entropy loss, but with any work that focuses on CE loss, it is important to distinguish inherent entropy in the data and the actual performance gap you want to mitigate https://arxiv.org/abs/2307.15936 . -
Collaborative Alignment of NLP Models
: We have been conditioned to use single, huge foundation models because they work well in practice, but this paper looks into whether the learning of several, concept-aligned models with some meta-chooser on top actually works just as well. The primary benefit is the ability to modularize and parallelize LLMs, making them more flexible and also potentially faster. -
Hard Prompts Made Easy: Gradient-Based Discrete Optimization for Prompt Tuning and Discovery.
: You can sort of think of (hard) prompts as parameters to an LLM that transferrable to other LLMs (e.g. If I prompt GPT-4 with “Explain Newton’s laws like I’m 5”, I expect LLAMA 2 to answer similarly). In the case of text-to-image models, the images we get are often not exactly what we want (there are various reasons for this we discuss in the multi-modal section!). This work is basically a way to steer text prompts with gradient-based optimization so they generate the images you want. -
OpenAssistant Conversations - Democratizing Large Language Model Alignment
: So I actually followed this project on YouTube through Yannic Kilcher’s channel https://youtube.com/yannickilcher , and the central idea is to open-source the data required for RLHF because its extremely expensive to curate 60k+ human preference samples. I believe that open-source communities are extremely important for AI, and it’s exciting to see them produce extremely useful projects like this one. Because it is open-source, a large chunk of the paper discusses quality control and reducing “bad” or “toxic” data. -
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
: For a while, the standard preference-alignment approach was to learn a reward model over preference data and fine-tune an LLM with RL on this reward model (RLHF). The issue with this approach is that RL is generally quite unstable and hard to work with, so this paper first motivates re-parameterizing the RLHF objective into a new objective that we can directly minimize. I’m not actually sure how well this works relative to RLHF in practice because I’ve never had access to these tools, but it is an RL-free alternative to preference-based alignment.
Multi-modal Learning
This year had a heavy focus on multimodal (mostly vision + language) models, with many companies/labs introducing their own shiny foundation models and associated datasets to compete with GPT-4. A lot of the desirable features in large multimodal models parallel that of large language models, so many of the research questions and themes are quite similar. In my mind, a core difference is the combinatorially larger amount of paired or associated data required to build a model that can interchangebly handle two different modalities. The obvious direction is to continue to scale the size of visual-language datasets with the size of new models, but I suspect that fundamentally answering how to “ground” two different modalities from a representation learning perspective may be able to reduce the necessary scale. At the end of the day though, this is still an open research question which I don’t know the answer to. The general themes I observed were
-
New Foundation Models. Large multimodal models, specifically vision-language, are the logical next progression to LLMs. Thus, it’s rather unsurprising that many research groups are racing to build the next big model
with the same capabilities of LLMs like being instruction-tuned and in-context learning. However, it looks like the training mechanisms for making these models robust are still pretty elementary. For example, , they simply treat everything as a token, but use a special embedding token for images and attentive pooling to reduce the complexity of these embeddings, then use the interleaved text and image data for standard log-likelihood optimization. At this conference, I didn’t see many actual models being showcased (although I’ve seen them over time on Twitter), but the large number of datasets seem to indicate that this is a growing direction. -
Datasets and Benchmarks. We’ve observed several instances of “good” data being key to getting LLMs to work better. The same logic applies to multi-modal models, except because there generally is no 1-1 mapping between tokens in each modality, this is quite hard. Regardless, there are lots of multi-modal datasets and benchmarks being curated, either by scraping and filtering data on the internet
or by curating the data . -
The Shared Representation. As far as I’m aware, the two main ways of building a multi-modal learning model are to tokenize each modality and train it as a decoder model on negative-log-likelihood loss
or train it CLIP-style CLIP or Contrastive Language-Image Pre-Training is an contrastive learning-based encoding method for embedding images and language into the same embedding space. The benefit is that we can query into this embedding space using text or images, and query from this embedding space to generate either text or images. The idea was popularized from its used in DALL-E, and is the standard for text-to-image models. Read more here: https://openai.com/research/clip as an encoder model.In both cases, we want to understand this latent representation embedded either in the model layers or in the embedding space to see if we can exploit its properties . -
Complex text prompts. It is known that text-to-image models often exhibit bag-of-words behavior, which means it lacks a strong understanding of syntax and logical quantifiers in a sentence. If you’ve ever played with Midjourney
A popular text-to-image generator: https://www.midjourney.com/home?callbackUrl=%2Fexplore or DALL-E2A popular text-to-image generator by OpenAI: https://openai.com/dall-e-2 . Several works attempt to inject compositional reasoning in these models to solve this. -
Multi-modal video understanding. Processing videos adds a temporal dimension to these models that is quite difficult. Even standard video understanding models have been difficult to get right for a while now. The naive approach is to concatenate frames and pass them into a image-language model, so there has been some interest in making the language component temporally aware
. -
All the same questions for LLMs. Fundamentally, these models are just huge transformers. Even the vision components are basically just LLMs where the vocabulary is image patches (although the vocabulary is much bigger and not fixed I suppose). Regardless, any open problem for an LLM (efficiency
, robustness , fine-tuning algorithms ) is essentially also a problem for multi-modal models. The difference though, is that we can assume that we are given a model that is good at each modality, so “bridging” the modalities is what we need to actually solve.
[Multimodal] Interesting Papers
There are a lot of what I like to call low-hanging fruit in multi-modal models that have been solved, and while they are still interesting and definitely more applicable to most problems, I wanted to focus on some works that I thought were cool.
-
4M: Massively Multimodal Masked Modeling
: Apple doesn’t usually publish in machine learning conferences (e.g. they didn’t let me publish or extensively discuss my work when I was there), but I have to say, I thought this paper was pretty cool. I mentioned in point (3) that a lot multi-modal models are either decoder-based (token-style) or encoder-based (embedding-style), but the authors of this work discretize the shared embedding space and embed using tokens instead of a continuous embedding. -
Connecting Multi-modal Contrastive Representations
: The idea here is that as we continue adding modalities to a shared representation space, we ideally want to use as little paired data as possible (for $N$ modalities, you would need $\binom{N}{2}$ sets of paired data). So we want to leverage pre-existing multimodal models, say a visual-language and a language-audio, and combine their representations without the need for visual-audio data. They effectively learn the projection function from both pre-trained models to the shared representation space, and motivate the loss required to align semantically similar embeddings. -
A Theory of Multimodal Learning
: This is an interesting paper on trying to formalize multimodal learning, although I don’t exactly understand how this differs from standard unimodal training. My understanding is that the primary limitation is data, and we can basically treat two modalities as distinct subspaces in some larger “unimodal” space. But regardless, they provide a formal differentiation between multimodal and unimodal learning and prove some standard ML theory bounds for an empirical risk minimization (ERM) algorithm. -
VLAttack: Multimodal Adversarial Attacks on Vision-Language Tasks via Pre-trained Models
: They use some cute tricks for developing black-box adversarial attacks on vision-language models by considering perturbations for both modalities in isolation, as well as for image-text pairs. Similar to above, it’s not clear exactly why we need a distinct “multimodal” strategy for this kind of stuff, but perhaps more works into this area will provide more insight. -
Geodesic Multi-Modal Mixup for Robust Fine-Tuning
: We want to understand the landscape of multi-modal embeddings and see if we can impose nice properties of this space like making it isotropic. In this paper, they first propose that CLIP embeddings (ZS) and naively fine-tuned embeddings (FT) have an inherent uniformity issue that distinctly separates “text” and “images” into different subspaces. Ideally though, they argue that we want the distribution over the space (they constrain it to be a hypersphere) to be based on the semantics. Their method proposes to mold this space by generating “mixed” hard-negative samples to use with the standard contrastive loss during fine-tuning.
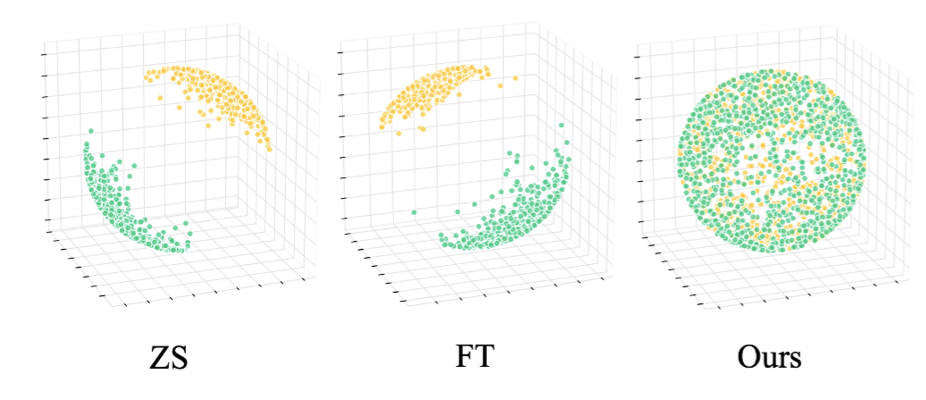
I’m curious because in the past, isotropic properties of “word embeddings” was thought to be a necessary thing, but it turns out we don’t really care, and a lot of methods that try to constrain this didn’t turn out to be that useful. I wonder how that applies here.
Transformers
With the Transformer module being the standard building block for scalable models, it is important that progress is made on improving their usage as a whole. Just as a side note, I think generally the term “transformer” is now overloaded to mean any structure using positional encodings plus an attention-mechanism, feedforward layers, and normalization in some repeated fashion, and does not necessarily refer to the original Transformer architecture. Interestingly, one thing I didn’t really find at this conference was investigating the enforcement of constraints or inductive biases like equivariance to Transformers, which may be an indicator of Sutton’s Bitter Lesson
-
Studying Transformer Models. Are there provable or empirically well-understood limitations of Transformers that may be severely limiting for future research directions? We know that Transformers seem to excel at reasoning but also frequently fail in simple cases, so
argue through a series of compositional tasks that these models (GPT-3,4) tend to pattern match reasoning chains. Furthermore, in , they try to examine the function classes that Transformers can efficiently approximate, which is especially important for upper bounding the representational capacity of models as they scale. Finally, there are works that examine/ablate features of the Transformer to study their impact. -
Efficiency. How do we modify parts of the transformer to be more efficient to 1) scale them for bigger models and 2) use them on low-compute devices? In
, they selectively act on a fixed block of the embeddings at any layer to increase model capacity while keeping inference latency fixed. In , they train layers to selectively drop tokens by imposing a sparsity constraint that affects their modified attention mechanism. Meanwhile, works like focus on preserving performance for quantized transformers and focus on deploying transformers on microcontrollers. -
Modifications to Attention. Can we make attention mechanisms more efficient
? As in sub-quadratic runtime ? Sparse ? Or can we even replace attention ? -
Memory. Can we increase context-window lengths or add external memory for transformers? This question is tied heavily to LLMs, and hence the methods (external memory source or summarization) are similar. Other than the works tied to LLMs, I only really found
, which basically learns to compress token sequences into “VIP”-tokens that represent what’s most important. My only concern is whether these tokens are domain-specific and how a fully-trained model fairs for transfer learning to other modalities.
[Transformers] Interesting Papers
-
Faith and Fate: Limits of Transformers on Compositionality
-
Geometric Algebra Transformer
https://en.wikipedia.org/wiki/Euclidean_group , which is all linear combinations of translations, rotations, and reflections of 3D Euclidean space. This is particularly useful for learning representations of geometric data, and they apply their Transformer to a downstream planning task and demonstrate that it still works even when we don’t want to enforce this constraint. -
Pretraining Task Diversity and The Emergence of Non-Bayesian In-context Learning for Regression
-
Fast Attention Requires Bounded Entries
-
When Do Transformers Shine in RL? Decoupling Memory from Credit Assignment
-
MotionGPT: Human Motion as a Foreign Language
Reinforcement Learning
Reinforcement Learning was a huge topic this year, with many papers discussing RL in the context of other works like diffusion models
-
Robustness. I’m specifically referring to the robustness of RL training algorithms and preventing failure modes. It is fairly well-known that RL is quite delicate and requires a lot of tricks
- Balancing the ratio of updates to timesteps is important for trading off convergence and sample efficiency. To prevent primacy bias (favoring early explorations), deep RL methods often perform a “reset” of their weights while storing the transition data in a replay buffer. Doing this can cause the model to diverge on reset, so
attempt to circumvent this issue by using an ensemble of agents and perform random resets so at least one agent is not reset. - We often want RL agents to act conservatively, so when they reach an unseen state, they do not act wild. In
, they add penalties to out-of-distribution states and prove that in an offline RL setting, they achieve a conservative estimation of the expected value function. - Deploying RL in realistic settings often implies the need for safety constraints to avoid exploring unsafe states. Works like
look into imposing these constraints with high probability. - There are many tricks involved in RL training, many of which are problem-dependent. For example, importance weighting over the training dataset in offline RL to prevent being influenced by low-reward trajectories
. Or reducing variance in the learning process with multi-step surrogate rewards . In , they analyze why augmenting visual observations leads to better sample efficiency. Some works even investigate tricks from other models like reward scaling and regularization schemes and apply them more generally .
- Balancing the ratio of updates to timesteps is important for trading off convergence and sample efficiency. To prevent primacy bias (favoring early explorations), deep RL methods often perform a “reset” of their weights while storing the transition data in a replay buffer. Doing this can cause the model to diverge on reset, so
-
Improving Exploration by Leveraging Priors. Reward functions play a huge role in the convergence of RL training. In most settings, the only “true” reward is a sparse reward given for achieving a goal (e.g. winning a chess game). However, propagating this sparse reward through a combinatorially large state and transition function space is fundamentally difficult, so people often design intrinsic reward functions to better guide an agent towards maximizing the true reward. Some methods attempt to generally identify good transitions and states to explore
by looking for state diversity and orthogonality, while other methods focus on automating a reward designer’s intent by conditioning on images, videos, or language through some pre-trained embedding space and push exploration in a certain direction using these exploration “hints” . Meanwhile, propose that even with sufficient exploration, a model may not learn a good policy, so dynamically modifying the model during training may fix that! -
Learning World Models for Model-based RL (MBRL). If you’re familiar with the basic formulation for the dynamic programming update functions used in RL, you’ll know that knowing the transition function, or the model of the environment dynamics, is an extremely powerful guarantee that you generally do not have. However, it is possible to try and “learn” this model to apply MBRL methods. One of my research interests as of late is learning and editing world models using language, so it is pretty exciting to see these works. A central theme in the use of world models is learning and acting “in imagination”, which means treating the world model itself as an environment that the agent can interact in, which is especially useful for environments where interacting is costly or dangerous. In
, they use the world model as a way for the model to “think” before it generates an action. In , they learn strictly formatted world models in a standardized language https://en.wikipedia.org/wiki/Planning_Domain_Definition_Language that models can interact with. Furthermore, many world models use an recurrent neural network (RNN) as the backbone for historical reason, so in, they experiment with different models for the world model backbone and propose their own with better empirical performance. -
Multi-agent RL. Multi-agent RL (MARL) involves multiple learning agents in the same environment, with most papers I’ve found generally focusing on cooperative or mixed-sum games. A lot of similar research themes in RL apply here as well, but there is also room for game-theoretic analysis. A core limitation in prior MARL work is the assumption of a fixed task and fixed environment, so works like
which is not obvious and directly influences the learned policy of each agent. Finally, because MARL is inherently expensive (you’re launching several agents at once!), creating environments that are compute-friendly is a topic of interest . -
Goal-conditioned RL. Goal-conditioned RL (GCRL) is a class of algorithms or problems where decisions are conditioned on both a state and a goal. There were only a few GCRL papers at this conference with an emphasis on offline RL strategies such as using sequence modeling over trajectories as a goal
, but I did find an interesting work on using the distance (they define their own metric) between the goal distribution and state visitation distribution as an extra reward signal for exploration . -
Theoretical Analysis. There were a lot of papers on bandit problems (especially adversarial or contextual bandits)
and provable regret/convergence bounds , most of which I was not really able to understand. While I think following the math itself and reading through it is quite fun, I’m just not familiar with what problems people are interested in and what is unsolved, so it’s hard to gather from the abstracts or even a quick skim of the papers what the immediate impact is. That’s not to say that these works are not interesting or useful, but I am going to be careful not to say something false about their results. However, I did find two works that prove convergence guarantees for deep RL!. In , they prove convergence guarantees for deep Q learning using $\epsilon$-greedy exploration under accelerated gradient descent (momentum) under some pretty minimal assumptions. In , they limit their analysis to linear MDPs and simplified neural networks, but show convergence guarantees for actor-critic and proximal policy optimization (PPO) methods respectively.
[RL] Interesting Papers
-
Conditional Mutual Information for Disentangled Representations in Reinforcement Learning
-
Creating Multi-Level Skill Hierarchies in Reinforcement Learning
: When I was playing around with PySC2 (Starcraft II RL environment), I used to always be confused how an RL agent would feasibly learn these complex chains of actions (turns out the answer was tons of data). Another approach outlined in this paper is to explicitly map out hierarchical skill trees, where the lowest levels are explicit actions and higher levels are more abstract, learnable skills. I’ve seen a similar idea applied to LLMs where you can explicitly query the LLM to reason about what it should do, but in RL its more robust but less interpretable. -
Efficient RL with Impaired Observability: Learning to Act with Delayed and Missing State Observations
: An interesting question in RL is how much “error” is induced by a partial loss in observability. They bound the worst-case performance on control systems depending on the expected percentage of missing states and show that RL is still applicable to this class of problems in an efficient way (which generally means poly() any environment parameters). -
Learning to Influence Human Behavior with Offline Reinforcement Learning
: I feel like in any multi-agent or game theoretic setup, we always assume other players are playing optimally. This paper is unique in that they try to learn a policy in a cooperative multi-agent setup that assists the other agent towards a certain desirable behavior. The environment is a grid-world version of Overcooked https://www.team17.com/games/overcooked/ which I find really funny, as this is the perfect environment for this kind of model. -
Is RLHF More Difficult Than Standard RL?
: They reduce RLHF and general preference-based reward signals to different classes of known problems in RL, motivating how RLHF is not inherently more difficult than standard RL problems. The paper goes into quite a few instances of preferenced-based RL, and is fully theoretically motivated. -
A Theoretical Analysis of Optimistic Proximal Policy Optimization in Linear Markov Decision Processes
: I’ve understood PPO as a series of empirical tricks and approximations to the theoretically motivated Trust Region Policy Optimization (TRPO), so I always thought that studying its theoretical properties to provably converge has been lacking. Even if this study is applied to a simple RL setting, it’s an important first step towards theoretically motivating PPO.
Generative AI
Generative AI as a whole has also been booming through 2023, especially as a marketable product. Given how accessible and easy to customize they have gotten, I think that the common layperson should understand at a high-level what kind of generative AI is out there. I should note that I structured this section to mostly exclude large language models or language as a modality altogether. These papers have mostly been targeted towards diffusion models, although there were still a few works at NeurIPS 2023 that focused on GANs like
-
Pre-trained Foundation Models. Generative models rely on a large backbone model that encodes the knowledge base of the domain that it acts on
-
2D to 3D View Synthesis. 2D generative models are at a pretty decent state, so extending their abilities to create 3D generative models is an open research question. Prior work on novel view synthesis encode scenes in the weights of the model, but recent work has looked models that can generalize to different scenes. For example, in
they train a signed-distance function (SDF) based reconstruction model to generate 3D meshes from generic 2D image views at inference time. In this field, spatial hash encodings have proven to be effective on GPU hardware for drastically speeding up 3D generative models, so enables dynamic scenes (basically add time) to be encoded by learning to selectively employ different hash encodings for static and dynamic parts of the scene. Finally, with Segment Anything (SAM) https://segment-anything.com being an extremely powerful 2D vision-language foundation model capable of accurate semantic image segmentation,presents a way to extend this to 3D. This process involves generating view-conditioned prompts to generate views of an image and properly inverse projecting these 2D masks back to a 3D voxelized space. This work is exciting and the results are very noisy and not great, but it’s definitely an open research problem that will make significant progress soon! -
Single-image 3D Reconstruction. An alternative to novel view synthesis is take a single image and try to extrapolate using domain knowledge what the 3D model looks like. Most of these methods leverage some kind of pre-trained 2D diffusion model to generate the alternate views, but they are distinct in how they choose to do this. Some do it by inferring 3D projective geometry
and others try optimizing directly with generations from a multi-view 3D diffusion model . -
Generating on new Modalities. Generative AI is not limited to language and vision. Audio and speech generative models
have found that tokenized representations of other modalities can be used in Transformers. Of course, the details are not that simple, and from my understanding encoding the tokens requires working over a spectrogram representation that is non-trivial. -
Text-to-video. I’m sure you may have seen some clips of text-to-video AI on social media, and while it is impressive, it is far from being as robust as the text-to-image models. A lot of work goes into ensuring causal and cross-frame temporal consistency in these generations
. While these models have an obvious use case for generating videos, I did find an interesting use-case of these models as a form of planning for policy generalization .
Diffusion Models
I decided to add a separate subsection on diffusion models with a focus on techniques that improve the base diffusion model process
-
Inference-speed. There have been strides by labs to make the training and fine-tuning process of diffusion models cheaper
https://www.mosaicml.com/blog/stable-diffusion-1 , but inference remains quite expensive. In, they motivate a training-free sampling method for performing an extremely low number of sampling steps (<10) while maintaining generation quality (for comparison, the standard amount is ~1000 steps and ~20 is considered low from prior works), while in they motivate stochastic sampling solvers and relate them to other popular solvers like the previously mentioned one. -
Interpreting the Latent feature representation. Can we understand the features that are learned by a diffusion model? This is generally done by probing the embedding space and clustering or checking if classes are linearly separable
, where they find Stable Diffusion features exhibit good spatial information but worse semantic understanding compared to another popular embedding method. Another step is to investigate and probe the latent seed space used to condition the generator, as done in . -
Multi-input. Similar theme to multi-modal models in general since they are so closely related, but can we develop diffusion models that take both text and visual data as input
and produce any desired output ? Can we also make it robust to composition and more complicated prompting ? -
Filling missing information. Can we leverage diffusion models to fill in the missing gaps of information in an image or a dataset label
? This is actually really cool, because the implication is that unlabelled or noisy images contain enough structure to reconstruct the unknown parts without the model just making things up.
[Gen AI + Diffusion] Interesting Papers
-
Tree-Rings Watermarks: Invisible Fingerprints for Diffusion Images
: Copyright and generative AI identification is going to become increasingly more important as the technology gets more accurate. This technique slowly applies an invisible watermark during the diffusion sampling process that is easy to recover when inverting the diffusion process. I have a feeling that similar to works on adversarial attacks, there is going to be a constant chase between watermark and watermark removal works in the near future. -
Generator Born from Classifier
: Can you take a trained image classifier and use it to generate images with minimal extra learning? We have seem class-conditional works like in diffusion models, but this work is trying to do something much stronger. This work is a first-step into leveraging a classifier for image generation, and they use the theory of Maximum-Margin Bias to extract training data information from the parameters of a classifier. -
CL-NeRF: Continual Learning of Neural Radiance Fields for Evolving Scene Representation
: NeRFs implicitly store the scene they are rendering in their weights, but they are generally fixed. But what if we want to capture an ever-changing scene? It seems natural to imply concepts in continual learning, as we mainly want to 1) not forget important static elements of the scene during weight updates and 2) dynamically add components to the scene through weight updates, and this work is a first step into solving this problem. -
UE4-NeRF:Neural Radiant Field for Real-Time Rendering of Large-Scale Scene
: As an avid fan of Unreal Engine and the games that have been produced by it, this is a really exciting work to me. There are companies like Luma and Volinga.ai that have a closed-source proprietary software for NeRF rendering in Unreal Engine, but this is the first work that open-sources it. I should note that their rendering process involves rendering sub-NeRFs in a partionined volume for efficiency purposes, but otherwise it follows a ray-marching procedure (ish).
Computer Vision
Computer vision (CV) was the field that introduced me to the world of machine learning, and I had a glimpse when I was a little boy building robots with my Arduino of what it looked like pre-AlexNet. Perhaps because NeurIPS itself is not focused on CV, I was rather surprised by the themes I noticed. There seems to be a much larger emphasis on video understanding and human-centric perception, although fairness and bias still remains an issue that has yet to be addressed.
-
Open vocabulary methods for segmentation and understanding of semantics in images involves being able to adapt to labels unseen during training. In essence, we want to be able to generalize our models past fixed class labels so they don’t have to be re-trained every few months. My understanding is that with vision-language models being a thing now, these methods only need to generate suitable embeddings use with these methods
. A lot of works now focus on extending to 3D models as well . I’m curious though how these methods handle language ambiguity and different abstractions of describing something, and whether or not this limitation is bottlenecked by the model’s language capabilities. I did find that tries to address this in a hierarchical way. -
Video understanding. I worked on a video understanding benchmark so I’m somewhat aware of the limitations in the field. Generally, video labels are quite difficult to procure, as they’re far more compositional and free-form, and they just take longer. At the same time, having models that can reason over videos is extremely useful because videos are the primary form of media consumed on the internet these days.Compared to language, videos take up much more memory, and finding associated labels through online scraping is hard. So an important work is to build up datasets and benchmarks
. Additionally, even with multi-modal models, they have not been sufficiently trained to understand temporal aspects of a video like actions and long-term causal reasoning, which works like make first steps towards addressing. -
Human Data and Perception. I noticed some interest in human-centric perception, as we ideally want vision models to understand similarity the way we intuitively perceive it. In
, they propose a margin loss that shapes the embedding space based on human similarity judgement data. Meanwhile, in , they focus on ego-centric data (video footage from the perspective of a human). We also want models to be more accurate when perceiving humans, which argues starts at the pre-training level. Lastly, there were a few papers on human-pose estimation, mainly for robustness on expressive poses and for improving accuracy on reconstructing the poses in 3D . -
Fairness. Fairness and bias is a long-standing issue in computer vision that is primarily rooted in dataset selection. A key research question is understanding which factors like human appearance
or geographical location are biased in our data. A further question is how to augment our data in the short term to mitigate these biases .
[Computer Vision] Interesting Papers
-
Segment Everything Everywhere All at Once
: This is Microsoft’s alternative to Meta’s Segment Anything (SAM) model, with a focus on semantic-oriented text prompting for segmentation. I haven’t had the opportunity to compare the two, but they claim that their method captures semantics more accurately. -
Diversifying Spatial-Temporal Perception for Video Domain Generalization
: When you build a video understanding model, you of course want it to generalize to unseen domains. For video domains, however, which are high-dimensional and contain a lot of complicated structure, unless the data is perfectly diverse (requiring a lot of video data), you want to be able to filter out domain-specific cues from your training data and identify domain-invariant cues that will help as a prior for generalization. This work attempts to motivate how to identify these cues at a spatial and temporal level, and I think ideas from this work can be extended to other fields as well. -
DropPos: Pre-Training Vision Transformers by Reconstructing Dropped Positions
: Empirically, we have found that Vision Transformers (ViT) kind of suck at understanding positional encodings, i.e. they are sort of position invariant. In some cases this is a desirable property, but we do want these Vision Transformers to be spatially aware, so this paper offers a simple fix: in addition to standard ViT training, add a secondary objective to predict the position of the token/patch. -
Patch N’ Pack: NaViT, A Vision Transformer for Any Aspect Ratio and Resolution
: They train with token packing strategies used for language models, which involves feeding in multiple images (in tokenized patches) with varying resolutions during train time. They claim it works for arbitrary image resolutions, but I’m pretty sure it’s the resolution change they used during training. Regardless, it is an extremely useful work that applies to a wide range of visual tasks. -
Color Equivariant Convolutional Networks
: I’m a big fan of equivariance as an inductive bias, and this paper is no exception. We generally want to separate geometry and color in visual models, and this work builds a plug-in block for common convolutional neural network architectures to add color equivariant convolution operations. These layers are not insensitive to color variation; rather, they allow for sharing information about visual geometry across different colors.
Adversarial Attacks and Model Poisoning
Generally, adversarial attacks can be partitioned into two main classes: white box, where an attacker has access to the model weights (e.g. for any open-source models), and black-box, where an attacker can only use model outputs (e.g. attacking GPT4). I still think that most attacks are pretty domain-specific, so I’ve decided to generally separate the themes based on domain (e.g. language, vision, RL) rather than the type of attack (e.g. red-teaming, gradient-based, etc.) Lastly, this section is primarily dedicated to attacks that alter or manipulate the outputs of a model to be harmful or incorrect. There is another class of attacks that try to reconstruct training data using model outputs, but I decided to move that to the section on Privacy and Federated Learning.
-
Robustness vs. Performance & Speed is an important tradeoff when developing models and considering defense mechanisms against attacks. Adversarial defenses have extra overhead, especially those with certification (provable robustness within $\epsilon$-ball), so it is important to understand this tradeoff. I was only able to recall
in this conference that tackles this issue. -
Model Poisoning. Distinct from the other attacks, model poisoning involves slightly editing the training data to plant exploits or backdoor triggers into a model
. It is possible that poisoned models are deployed in the wild, so you may not even have access to modify its internals. So essentially, you can either fine-tune the model or directly augment its outputs with noise to remove the poisoning. -
Attacks on LLMs. Given the theme of multi-modal models, there has been a few works examining defenses for vision-language models against known attacks for language or vision models
. However, given the discrete nature of token representations, simple black-box attacks using seemingly harmless tokens like an exclamation point are possible . Lastly, attacks and defenses against model poisoning were discussed . -
Attacks on Images. Unlike language, raw image representations are high-dimensional and therefore easily susceptible to noise and perturbation effects. In
, they propose a noise generator that transfers black-box attacks from one image model to another. These attacks and defenses have evolved over the years, but it’s still an open research question even on older datasets like ImageNet .
As an aside, there were lots of adversarial attack papers this year using specific attacks, targetting specific models (e.g. MARL
[Adversarial Attacks and Model Poisoning] Interesting Papers
-
Setting the Trap: Capturing and Defeating Backdoors in Pretrained Language Models through Honeypot
: The strategy in this paper is really cool: basically, they first notice that backdoor triggers in poisoned models are “obvious”, in the sense that they appear in lower layers of the model in an obviously linearly separable way. Intuitively, this makes sense, as poisoned outputs are structurally out-of-distribution from “human language”. From here, they basically add these small “honeypot” layers (just a 1-layer transformer) with a classification head that purposefully get “poisoned” early on, and they use this auxiliary loss to weight the actual cross entropy loss. I think that is a really neat example of exploiting structure and abstract representations of data to achieve an effect. -
Neural Polarizer: A Lightweight and Effective Backdoor Defense via Purifying Poisoned Features
: Poisoned data generally looks like a regular image with some small perturbations or tiny trigger features, so this work looks into inserting learnable filters into a trained model that reverses and removes these features while acting as an identity map for everything else. The main issue I see with this approach is that you have to know the type of adversarial attacks against the model a priori, so a fixed filter needs to be updated when new attacks arise, i.e. there are no provable guarantees against general adversarial perturbations.
Knowledge Distillation and Memory Reduction Schemes
As much as we like scaling models, building smaller models that can run on accessible hardware is extremely important for the growth of our community. This section is mostly referring to scaling down models so they can run on inference time on smaller hardware, which is a matter of memory efficiency. TinyML
-
Memory Reduction Techniques. We generally are intered in tradeoffs for different memory reduction schemes such as pruning and quantization. In
, they claim that quantization is almost always better unless you care about extreme compression. Similar to older work doing weight quantization for MLPs and CNNs, newer works at this conference do it for transformers . -
Lottery Ticket Hypothesis (LTH)
The lottery ticket hypothesis is the notion that dense neural networks contain a much smaller subnetwork that accounts for most of the performance. Finding these subnetworks through pruning would, in theory, preserve performance while significantly reducing memory. Read more from the original paper: https://arxiv.org/abs/1803.03635 . Following the original LTH, we want to understand what metrics (e.g. weight magnitude, gradient flow) and structure are useful for pruning modern architectures like LLMs, but this also depends on what we are pruning for. Inthey prune LLMs based on run-time bottlenecks for inference speed-ups, while in they focus on shrinking the model. Meanwhile, in convolutional neural networks, pruning based on empirics has been widely studied, so provide some theoretical motivation into better pruning based on the structure of the model. -
Knowledge Distillation. Knowledge distillation (KD) is an approach for trying to force a small student model to mimic the output probabilities of a larger teacher model. KD has seen a wide array of techniques being used to preserve functionality of the teacher in the student, and many empirical experiments have been done in the past to evaluate the lower-bound capacity of student models. Nevertheless, the works at this conference were pretty unique. In
they observe that student models have noisier features and attempt to de-noise them using diffusion. In , they motivate “concepts” in intermediate layers as an auxiliary signal for distillation. Finally, investigates whether properties like adversarial robustness, invariances, and generalization are transferred effectively during distillation.
[Memory Reduction] Interesting Papers
-
MCUFormer: Deploying Vision Transformers on Microcontrollers with Limited Memory
: They push the modern limits of Vision Transformers on ultra-low cost systems, using neural architecture search (NAS) to search for a compute-optimal architecture while also writing a library for performing each inference-level computation in a Vision Transformer efficiently. I’m not that aware of the pre-existing literature in this space, but this is one of the first papers I’ve seen do it for Vision Transformers. -
What Knowledge Gets Distilled in Knowledge Distillation?
: Knowledge distillation is sort of this black-boxy approach where we try to get a small student model to be the same as a larger teacher model. It would be nice to know what kind of information easily transfers and even nicer to understand why, which this paper attempts to do. Most surprisingly, they find that white-box vulnerabilities in a teacher model transfer over to a student model despite being a different parameterization, which might be indicative of some structural similarities inherent to networks (it is inconclusive in this paper though). They try to motivate this transfer by a dimensionality argument to argue that the student model solution is unique, but honestly the argument is pretty weak because the assumptions are just generally untrue in almost any realistic problem where knowledge distillation is applied. -
Polynomially Over-Parameterized Convolutional Neural Networks Contain Structured Strong Lottery Tickets
Subset sum is a classic NP-hard problem in CS theory where a program must decide if there exists a subset of a set of integers that sums to a number $T$. The randomized version is a set of random variables, and the sum can now be off by an error $\epsilon$ with high probability. has anything to do with the existence of strong lottery tickets in an over-parameterized convolutional neural network.
Graph Neural Networks
Graph neural networks (GNN) were really popular this year! I wish I had a stronger understanding overall of GNNs, but unfortunately I just haven’t found any specific use cases for them in my own research. I am aware of their use-cases in structured prediction (e.g. molecular dynamics
-
Heterophily vs. Homophily. Earlier works with GNNs worked under the assumption of graph homophily, meaning similarly labelled nodes tend to be linked. This assumption neatly allows for even unsupervised methods to exploit graph structure when making predictions, but it is unclear what the impact of graph heterophily is on GNN performance
. Thus, there has been work towards solving graphs under heterophily by focusing on non-local structure . In , they even try to rigorously characterize the properties and effects of these node-level relationships. -
Unsupervised graph learning. Unsupervised learning is natural in graph problems because regardless of the problem domain, the graph itself provides extremely useful structural information that can be leveraged for a prediction. There is still a lot ongoing research
into identifying and targetting useful structure in graphs, which includes (1). -
Spatio-temporal prediction involves time-series forecasting over spatially-varying data. This problem is significantly harder than stock prediction type forecasting over tabular data because of the inherent high dimensionality and structure (local vs. global) present in spatial data. Thus, a class of works this year
have emerged to study these problems using GNNs. -
Encoding representations in graphs. Typically GNN methods represent nodes or links with some kind of embedding representation, so understanding the mechanisms that shape these representations is important
.
Broadly speaking, a lot of advances in other fields that were discussed above are also active areas of research in GNNs (e.g. adversarial robustness
[GNN] Interesting Papers
-
Zero-One Laws of Graph Neural Networks
: Zero-one laws generally study the limiting behavior of probabilities and show that they converges to $0$ or $1$. This paper proves equivalent zero-one laws for the outputs of certain classes of GNNs (e.g. boolean graph convolutional classifiers) as they get larger and larger. Practically speaking, I don’t currently see a use case for this kind of analysis, but it is cool nonetheless. -
Unsupervised Learning for Solving the Travelling Salesman Problem
: They use a simple unsupervised graph neural network with surrogate loss objectives that provably move towards the objective, that being minimizing the path cost and ensuring the path is a Hamiltonian cycle. I’m really curious to see future GNN works on approximating solutions to NP-hard/NP-complete problems based on derived surrogate objective functions. -
Lovász Principle for Unsupervised Graph Representation Learning
: Math researchers have done lots of incredible work in study global and local properties of graphs, and I expect that we will continue to see these results be useful in GNNs. Unsupervised learning for graph neural networks makes so much sense, because so much structure comes from the graph itself regardless of the domain it is describing. Having learned about Lovász numbers in an extremal combinatics course taught by Professor Alon Noga himself, it was cool to see them re-appear in an ML setting.
Privacy and Federated Learning
Trust in AI and the companies that build these AIs is extremely important. This year’s conference had a strong emphasis on privacy and data protection methods, as well as federated learning methods
-
Differential Privacy. Data privacy and anonymity can be mathematically guaranteed under differential privacy (DP) constraints, so adding these DP mechanisms to deep learning models with minimal overhead is an active area of research. Because DP is so mathematically sound, some work goes into studying DP under conditions common in machine learning
while others go into applying DP to machine learning problems . -
Machine Unlearning looks into removing sensitive information that was present in a trained model’s training distribution, effectively wiping the information from a model altogether
. These techniques are useful for combatting copyright issues, but they are not well understood and can even lead to exploits -
Client attacks on Federated learning. Federated learning involves lots of gradient information from different worker sources. If an attacker got a hold of some workers (e.g. a malicious mobile device user), they could, in theory, inject harmful information into a federated learning system (similar to an adversarial attack, formally called a Byzantine attack). It is far easier in a federated learning setting for attackers to become clients, so many studies look into poisoning attacks
and robust defenses against them through things like trust scores , zero order optimization with DP guarantees , and measuring divergence from the average . -
Failure modes of federated learning. Federated learning does gradient updates out of sync, which means 1) theoretical analysis is a serious pain and 2) failure modes are more apparent. Furthermore, with extra mechanisms for privacy, an open research question is understanding the convergence guarantees of federated learning under various techniques and mechanisms
.
[Privacy and Fed. Learning] Interesting Papers
-
Privacy Auditing with One (1) Training Run
: We generally have to prove that an algorithm is differentially private (which is too hard in most cases!), but there are ways to audit or inspect empirically if an algorithm is differentially private. The problem is that DP is a probabilistic guarantee about the inclusion and exclusion of any data point, so we have to sample taking out data points. But sampling in the DP sense means re-training with or without data, which is extremely expensive. This work remarkably shows that they can audit with O(1) training runs under provable guarantees, which is a huge step from prior works. I skimmed the theoretical work, and it seems that they show the desired concentration bound of their method by showing that their process is stochasticly dominated by a binomial (a trick which appeared on my probability theory PSET!), and I’m excited to sit down and go through the math when I get the chance. Oh also, this paper won Outstanding Paper at this year’s conference. -
Lockdown: Backdoor Defense for Federated Learning with Isolated Subspace Training
-
Training Private Models That Know What They Don’t Know
: I think this paper is a pretty simple example of the type of performance and computational overhead that privacy constraints can induce. I’m hoping to see these kinds of works extended to larger models and more modern datasets, but they’re nonetheless very important.
Datasets, Benchmarks, Challenges
As NeurIPS is an AI-centric conference, there were datasets, benchmarks, and challenges for every topic above. There’s even a Datasets and Benchmarks track at NeurIPS. The more popular topics had more datasets (multimodal, LLM, etc.) and the datasets reflect the current needs of each field. A lot of the references put in earlier sections are dataset papers, so this section is going to be dedicated instead to some interest datasets I found while going through.
One thing I noticed though was a few papers on using synthetic data
Interesting Datasets
-
Multimodal C4: An Open, Billion-scale Corpus of Images Interleaved with Text
: This is the multi-modal variant of the original C4 dataset, which has been a standard in LLM pre-training since its release. Because of how prevalent this dataset is going to be, I think it’s at worth at least taking a look at the data that’s going to be a part of most of our generative AI in the near future. -
BEDD: The MineRL BASALT Evaluation and Demonstrations Dataset for Training and Benchmarking Agents that Solve Fuzzy Tasks
: MineRL is really cool. If you haven’t seen it already, I highly recommend taking a look, as Minecraft is the type of game that you would expect to be extremely complex for an AI to understand, but also simple enough that it seems feasible to eventually solve. This dataset provides a suite of labelled frame-action pairs and human labels that have been collected over the past two years and is extremely valuable for researchers working on this challenge. -
GenImage: A Million-Scale Benchmark for Detecting AI-Generated Image
: This is the closest thing to a synthetic dataset that I found at this year’s conference, but their focus was explicitly on creating AI-generated discriminators. I’m actually really curious to see if someone completely AI-generated a copy of the ImageNet dataset and trained models on it, how good would these models be? What kind of special differences, if any, could we find with these models and the originals?
Other Topics
The following sections are dedicated to topics that were either not as popular this year but are still broadly relevant or where I could not really get a sense of the central themes surrounding them. The main issue boils down to not having enough background on the topic, so I have to go through a few papers on the subject before comprehensively understanding what they’re doing. Regardless, they each had some interesting papers to highlight.
Interpretability and Explainable AI
Interpretability and explainable AI is really hard. We know that deep learning models tend to be a black box, and it’s generally because their inner mechanisms are too deep and intertwined with non-linearities that unless we make strong assumptions . I’d highly recommend going through the https://transformer-circuits.pub posts (start from the bottom), as they are extremely thorough and have been updated over time as well.
On the topic of mechanistic interpretability
-
Scan and Snap: Understanding Training Dynamics and Token Composition in 1-layer
They analyze 1-layer transformers without positional encoding or residual connections, so their analysis is a bit different than some earlier transformer mechanistic interpretability works that focus on residual streams. I haven’t gotten the chance to read through their analysis carefully, but they claim that under these conditions, the attention mechanism initially attends to “distinct” (uncommon among many pairs) key tokens and continues putting weight on the highest co-occuring distinct tokens, but eventually these weights get fixed after a certain time in the training process. The idea is that common tokens (i.e. words that probably don’t really add to the semantics) are not attended, naturally filtering them out as dataset sizes increase. -
Reverse Engineering Self-Supervised Learning
: They do self-supervised learning over CIFAR-100 and attempt to probe the intermediate layers, using the performance of probes over the course of training to justify their claims. Their conclusion is that self-supervised learning algorithms learn intermediate representations that are clustered based on semantic classes, and they show this using the performance of probes after accurate model performance, citing regularization constraints as the key driver. -
The geometry of hidden representations of large transformer models
: This work attempts to uncover common geometrical patterns, mainly intrinsic dimension Intrinsic dimension is the lowest dimension manifold that can approximate a dataset up to some error. The reason why we care about intrinsic dimension is that high-dimensional data is very hard to work with and significantly increases the complexity and failure modes of a learning algorithm. In practice, however, high-dimensional data like images often contain structure that leads to a low intrinsic dimension. and a metric they call “neighborhood overlap”, across layers in transformer models. I am not familiar with the tool they use to measure intrinsic dimensionality and how accurate it is, but Figures 1 and 2 in their paper are pretty telling of the conclusions they draw. -
Towards Automated Circuit Discovery for Mechanistic Interpretability
: There has been quite a lot of work on studying toy networks in mechanistic interpretability, and this paper attempts to write out a concrete framework for doing mechanistic interpretability research. They then attempt to automate one of the steps, which is activation patching (varying inputs to an activation) to find circuits that exhibit a particular behavior. -
Explaining Predictive Uncertainty with Information Theoretic Shapley Values
: Shapley values https://en.wikipedia.org/wiki/Shapley_value are the solution to a cooperative game theory problem that satisfy a set of axioms. Informally (and related to explainable AI), they are a way of rigorously identifying which features contributed to a certain model prediction (although it is very expensive and scales poorly with training dataset sizes). In this paper, they motivate using a similar framework for measuring how training data features affect conditional entropy, which is directly linked to model uncertainty. -
Theoretical and Practical Perspectives on What Influence Functions Do
: Influence Functions (IF) measure the change in a model prediction when re-weighting training examples, effectively relating a model’s output behavior to the training data. More formally, for a training dataset $\mathcal{S}$, suppose we perturb the weighting of data point $x$ by $\delta$. Let $\mathcal{L}(x,\theta)$ be the loss of a model with parameters $\theta$ on datapoint $x$, and let $\theta_{x,\delta}$ be the minimizer of the perturbed dataset. For a test data point $z$, the influence function $I(z,x,\theta^*)$ is defined as
which is precisely the change in test loss through perturbation. Of course, this expression is not that interesting, but through Taylor expansion and assumptions about the loss function, it has an even nicer closed form solution (albeit with an inverse Hessian) in terms of $z,x$ and $\theta^*$, the minimizer of the original unperturbed dataset. For the aforementioned closed form solution to make sense, a lot of assumptions have to be made, which this paper tries to break down and explain why it may fail on real problems.
Implicit Bias
From a statistical learning perspective, overparameterized neural networks under gradient descent should exhibit overfitting. However, it has been shown empirically that overparameterization is generally helpful and leads to good generalization ability. Additionally, it is well known that there are many machine learning algorithms that provably generalize well on certain domains (e.g. support vector machines on linearly separable data). Implicit bias is the notion that overparameterized deep neural networks tend towards solutions that are similar to algorithms that generalize well as an explanation for their generalization ability. There has been some nice theoretical work in the field, some of which was present at NeurIPS 2023.
-
The Double-Edged Sword of Implicit Bias: Generalization vs. Robustness in ReLU Networks
: Usually implicit bias is understood as a net positive for pushing models to generalize better, but this paper rigorously shows convergence towards solutions that are weak to adversarial $\ell_2$ perturbations. The analysis is limited to logistic loss or exponential loss on 2-layer ReLU networks but is entirely theoretical. -
Implicit Bias of Gradient Descent for Logistic Regression at the Edge of Stability
: If you’ve ever done the proof of gradient descent for $L$-smooth convex functions, you’re probably aware of the Descent Lemma and the $<1/L$ step size requirement. The edge of stability is this step-size range where this monotonicity guarantee is broken, but empirically models still seem to be able to converge. Interestingly, they show superiority of logistic loss over exponential loss theoretically in that at regardless of the step size chosen, logistic loss will converge eventually while exponential loss will diverge from the implicit bias using gradient descent.
Training Dynamics
For generic gradient-based learning in neural networks, we are often interested in understanding common patterns that emerge during different phases of the training process. Grokking
-
Phase Diagram of Early Training Dynamics in Deep Neural Networks: Effect of The Learning Rate, Depth, and Width
: They motivate a bit about why sharpness matters as a metric for training dynamics, an analysis of how different hyperparameter choices affect how loss and sharpness over time. It’s a pretty interesting set of experiments in a toy setting, but I don’t know how observable the phases they observe are when you add all the tricks and complexities of modern deep learning. -
Training shallow ReLU networks on noisy data using hinge loss: when do we overfit and is it benign?
: Similar to the work above, it’s again a rigorous empirical analysis on a toy problem, but it’s important progress towards understanding what our models are learning during training. -
Efficient Bayesian Learning Curve Extrapolation using Prior-Data Fitted Networks
: I remember laughing when I first found this paper because it is literally inferencing what the training dynamics of another model will look like. It’s not the first work of its kind, but they incorporate the prior training curve data to do Bayesian inference of the training dynamics. I’m honestly also curious why regression doesn’t suffice.
Embodied AI
Embodied AI is a nascent field, but it focuses on building agents that can utilize multiple modalities. The field is set up to be a pre-cursor to the fabled AGI, but progress on this field hinges on the success of other fields like NLP, multi-modal learning, RL (although this is debated frequently). I didn’t see many works directly focusing on embodied AI, but I’m sure there will be many in the future.
-
Egocentric Planning for Scalable Embodied Task Achievement
: This was the winning agent for the ALFRED challenge at CVPR 2023 https://embodied-ai.org , where agents solve language-specified tasks in a first-person simulation. It’s a domain-specific agent, but I think what’s interesting is understanding how they choose to ground skills and actions for planning the next action. -
Describe, Explain, Plan and Select: Interactive Planning with Large Language Models Enables Open-World Multi-Task Agents
: I’ve seen quite a few LLM-based approaches to Minecraft, but this is the first to do zero-shot planning. To add game context, they have a visual-language model map visual observations to language, and they use these models to further decide which LLM-generated goals are more feasible conditioned on the visual state.
Neural Architecture Search
Neural architecture search (NAS) is a class of algorithms that automatically search for model parameters (not just hyperparameters!) to optimize for some metric and has been around for a while. NAS is used a lot in finding model parameters for ultra low-cost machines like in
-
EvoPrompting: Language Models for Code-Level Neural Architecture Search
: Along the themes of can LLMs do everything, this paper looks into whether LLMs can aid in NAS. A lot of algorithms in NAS involve evolutionary search, so they query the LLM to generate the code for network parameters and mutate them over time through a soft-prompt tuning process.
Neural Operators
Most data is inherently discretized, or it lies on some well-defined finite-dimensional Euclidean space. However, there are many problems that involve learning functions (e.g. approximating partial differential equations) where we instead want to learn mappings between functional spaces. I think this paper
-
Convolutional Neural Operators for robust and accurate learning of PDEs
: They prove similar universal approximation theorem guarantees for neural operators, but explicitly using convolutional layers. This is a pretty significant work in expanding neural operator use-cases, and they also show some examples of learning PDEs.
Variational Inference Methods
Bayesian methods are provably good at examining uncertainty in the posterior given your prior information and beliefs, but in practice they require approximating different intractible integrals in the closed for computation. More formally, suppose we want to compute the posterior $P(\theta|X)$, which represents the distribution over the parameters given our data. From Bayes rule,
\[P \left(\theta|\mathbf{X} \right) = \frac{P \left(\mathbf{X}|\theta \right)P\left(\theta \right)}{P \left(\mathbf{X} \right)} = \frac{P \left(\mathbf{X}|\theta \right)P \left(\theta \right)}{\int_{\theta}P \left(\mathbf{X}|\theta^{\prime} \right) P \left(\theta^{\prime} \right) d \theta^{\prime}}\]The idea is that the denominator is intractible, but it’s actually a constant, so we can learn the posterior up to some normalization factor. So we instead will learn a simpler distribution \(Q(\mathbf{\theta})\) to approximate the posterior. The techniques for minimizing the difference between these distributions during optimization are well known and used frequently in applied ML.
-
Joint Prompt Optimization of Stacked LLMs using Variational Inference
: This paper presents a very unique idea. Basically, if we stack langauge models (I had no idea people did this), you can treat the output of the $N-1$th language model as a latent parameterization of the $N$th language model, so we can perform variational inference to get a good estimate of the generative distribution of the $N$th language model. This theme of prompts being parameters is not new, especially if you’ve read earlier parts of this post, but the purpose of this work is to show that stacking language models can, in theory, provide better performance with a bit of extra machinery.
Quantum Information Theory
Quantum computers are notably faster at solving certain classes of problems (e.g. Shor’s algorithm for prime factorization), so if they end up replacing modern processors, we ideally want to ensure machine learning algorithms are efficient on them. While there were barely any papers on this topic, I did think it was interesting to look into.
-
On quantum backpropagation, information reuse, and cheating measurement collapse
: The backpropagation relies on re-using intermediate computations to achieve a linear runtime, which almost the entirety of deep learning is built on. In quantum mechanics, however, measurements fundamentally change the quantum state describing a system, so storing copies of a quantum state for future use doesn’t really make sense. It’s a really unique and interesting challenge to balance the tradeoffs between quantum computing and classical computing (freshman year me was once interested in pursuing quantum computing, but alas), and this paper provides a unique solution to achieve backpropagation scaling, potentially enabling the development of scalable overparameterized neural networks on quantum computers.
Energy-based Models
Energy based models (EBM) are a different way to view and train probabilistic models based on learning an energy function, but they provably can represent a wide varieties of algorithms such as k-means and maximum likelihood estimation
-
Energy Transformer
: I think EBMs have the potential for a major breakthrough, but it really depends on whether they can reliably crack a really hard or popular problem. This work adapts EBMs for modern deep learning mechanisms like attention, and I’m interested to see if people take this further to things like LMs!
Curriculum Learning
Curriculum learning is the notion of learning simple tasks first before learning complex tasks. This intuitively makes sense in RL, where we want to learn simple skills before learning complex high-level strategies, but it is not limited to RL. I have always been kind of skeptic of curriculum learning because it is not well understood, but at the same time there have been some successful use cases of it.
-
Curriculum Learning With Infant Egocentric Videos
: Funnily enough, this was a research direction I was interested in taking back in 2021, but I just never got access to the data to do it. I’m curious though if curriculum learning is particularly useful for self-supervised learning because it helps form the intermediate representation space in a nicer way or order, i.e. starting from representation space A, it’s a lot easier to move to B through gradient-based learning, so we should learn A first.
Anomaly Detection
Anomaly detection (AD)
-
Unsupervised Anomaly Detection with Rejection
: In my mind anomaly detection makes the most sense in as unsupervised or self-supervised learning problem because they inherently pop up in any domain. Their work deals providing strong theoretical guarantees for a general unsupervised algorithm that to reject low-confidence outputs. -
Energy-Based Models for Anomaly Detection: A Manifold Diffusion Recovery Approach
: One way of detecting anomalies is to have a general understanding of what your data should look like. In this work, the authors follow this idea by training an energy-based model to approximate the low-dimensional manifold that the training data lies on and use the energy function as a score for identifying anomalies.
Class Imbalance Approaches
For multi-class classification problems, we generally want a uniform distribution of class labels across the dataset so models do not converge to the most frequently occurring label with probability 1. Class imbalance is a long-standing problem in optimization-based methods, and there has been a lot of work to try and combat it (e.g. data augmentation to balance classes, sampling, new loss funcitons).
-
Simplifying Neural Network Training Under Class Imbalance
: This paper makes some pretty strong claims: that just by tuning hyperparameters like batch sizes, label smoothing, optimizers, and data augmentation, we can combat class imbalance. The experiments they run are on fairly simple and old datasets, but this is pretty common for works that study general deep learning phenomena. I’m just not sure how well these observations hold at scale.
Continual Learning
I was interested in continual learning, also known as lifelong learning, when I first discovered machine learning. I think continual learning, like multimodal learning, is another important piece towards artificial general intelligence (AGI), but it is not as popular at the moment. The general idea is a learning framework that continues to adapt and learn over time, but well-known problems like catastrophic forgetting (model learns A then B. model will forget A.) and plasticity (how easily does a model learn something new) make continual learning extremely difficult. It is entirely possible that completely different paradigms are necessary for continual learning, but this is an active field of research
-
A Definition of Continual Reinforcement Learning
: Reinforcement learning is explicitly a reward-maximizing algorithm under a fixed environment, which is sort of at odds with continual learning, where we want a policy to continue to adapt. This paper lays some of the groundwork for defining the necessary vocabulary and tools to approach continual learning in a reinforcement learning setting. -
RanPAC: Random Projections and Pre-trained Models for Continual Learning
: We ideally want to leverage pre-trained foundation models as a base for continual learning, but because we do not have a strong mechanistic understanding of these models, it is unclear how changing these weights over time in a continual learning sense will affect the model performance. This work is a first step into performing parameter updates on pre-trained models without forgetting.
Deep Learning Theory
Deep learning theory is specifically the study of deep neural network models, and generally centers around dense linear layers with activations (at least for now). The most well known result is probably the Neural Tangent Kernel (NTK)
- Kernel methods. This was formalized in the NTK work, but there is a provable duality between gradient descent in the infinite width limit and kernel gradient descent over the NTK as the kernel. Because of the rich theory present in kernel methods, we can apply these tools to study the behavior of neural networks as well.
- Mean-field theory has historically been applied in probability theory and physics settings (thanks to my roommate Evan for explaining the basic idea to me), and is essentially a suite of tools for solving extremely high-dimensional and complex dynamics by approximating their behavior as an “average”. It has been applied extensively to deep learning theory as well for studying the behavior of infinite-width and infinite-depth networks as an alternative to viewing everything as kernels.
There’s a bit too much necessary background information that goes into the machinery required for deep learning theory for me to really understand any of these papers, so unfortunately I do not have anything to list for interesting papers (yet at least!). I can list some examples though:
Bio-inspired AI
Artificial Intelligence is an extension of our desire to mimic biological intelligence (although I wish it wasn’t), so naturally we have a lot to gain by using ideas we discover from biology. I think over time we will always see a steady number of works on bio-inspired AI, but so far, I haven’t seen too many works of this type that really take off (e.g. spiking neural networks). Part of the problem is that we know very little about our brains and how they function, so potentially once we figure that out, we’ll start implementing those mechanisms in our AI!
-
Are Vision Transformers More Data Hungry Than Newborn Visual Systems?
: I think it’s always sort of assumed that humans are far more data efficient than neural networks. They compare ViT performance on object recognition against newborn chicks with the same visual data and show that ViTs actually solved the same tasks. This paper is interesting, but I think the task is too simple and doesn’t capture the efficiency and task complexity tradeoff that would be more interesting to know.
Domain-specific applications of AI
There were a lot of very cool domain-specific applications of AIML at NeurIPS this year, most of
which was completely beyond me. Applications and datasets for the natural sciences were probably the most popular, especially related to protein modeling or protein functional prediction
-
Circuit As Set of Points
: I wanted to highlight this paper because I thought it was zany. They literally treat circuit discovery as a point-cloud prediction problem instead of like a graph as in prior works. The authors say it’s to avoid pre-processing, so they’re literally just feeding in a raw circuit and treating it like a point cloud. Works like these are honestly really exciting, even if doesn’t end up become the standard method.
Reproducibility Studies
So I didn’t know reproducibility experiments were publishable at major AI conferences like NeurIPS, but I’m happy to discover that it is. This year featured quite a few reproducibility experiments for older works, and it seems like they all follow a kind of template of how they should be conducted. I have experience working with repositories that just do not align with the results of described in the papers, so I know how annoying it is to not know if a paper actually works. I saw this paper
Other Papers I Liked
-
Task Arithmetic in the Tangent Space: Improved Editing of Pre-Trained Models.
: It seems that literally adding the weights of a bunch of fine-tuned experts on distinct downstream tasks can actually lead to a generalized model that solves all of them. From a linear algebra perspective, this only makes sense if the fine-tuning process pushes the weights into their own distinctive regions of the weight space. They motivate this sort of behavior as weight disentanglement and use it to fine-tune models for better weight addition properties. -
Language-based Action Concept Spaces for Video Self-Supervised Learning.
: I’ve recently been interested in more abstract representations of concepts like actions for building agents that can “think” using these representations. I think a lot of works on thinking in terms of actions and skills has been in terms of LLMs, but this work examines it from an encoder perspective. -
The Grand Illusion: The Myth of Software Portability and Implications for ML Progress
: I generally take for-granted the libraries that I use, so it was cool to see a study on the performance of popular frameworks across a variety of devices. These kinds of details are the things that I’ve been more and more interested in understanding, so I’m happy to see a paper like this at the conference. -
Human-Guided Complexity-Controlled Abstractions
: To develop agents that can interact with the environment the way we do, we first have to understand how to integrate our mental abstraction hierarchy into an agent’s. If you look at some of the papers I talked about earlier like , it is clear that people are interested in building action hierarchies for agents. This paper looks into understanding what level of abstraction or complexity is required to understand and execute actions for different types of tasks. I’m hoping to build a mental model of how we would go about building robust systems that can act in this way. -
The Tunnel Effect: Building Data Representations in Deep Neural Networks
: This paper provides some empirical insight into how data is represented throughout generic overparameterized neural networks. They propose this tunnel effect hypothesis, where the early layers of the network focus on linearly separable representations that focus on learning the actual task, while the later layers are just compression layers that harm generalization performance. They also suggest that regardless of model capacity (as long as it is sufficient), models will allocate the same amount of capacity to a specific task, which may also offer some insight into the implicit bias of models and why they tend not to overfit in the overparameterized regime.
Final Thoughts
This was a really rewarding process for me, not only from a knowledge standpoint. Before doing this little exercise, I was feeling a bit burnt out from school and learning in general. For a while, I had been thinking really hard researching how to inject language information for policy learning, but a lot of directions I had in mind just didn’t seem to make sense in the end. I had spent a lot of time reading in this specific direction, and I was a bit tired of seeing the same flavour of methods being applied. So it was honestly really refreshing to take a step back and reel in what people had been doing. I didn’t get a chance to go to NeurIPS 2023 (or any major conference for that matter) because of my courseload, but at least now I can say I know at least a little bit about what was going on there!
During this process I also compiled a list of open research questions I think are worth pursuing, which I may clean up in the future and put up. If you made it this far, thanks for giving it a read! It took a long time to synthesize these resources and figure out the structure of this article, so regardless of your background or prior knowledge, I hope this was at least somewhat useful for you!
Random Terms
I kept track of a list of terms that I had to Google while going through these abstracts. I probably
also ended up looking into more and forgot to put them in this list, but in case you’re interested,
here they are below. Edit: Ok so, this article ended up being way longer than intended, so instead if you want this list you should email me. My email is on my home page.
Citation
Just as a formality, if you want to cite this for whatever reason, use the BibTeX below.
@article{zhang2024neuripshighlights,
title = "Highlights of NeurIPS 2023 from Abstracts",
author = "Zhang, Alex",
journal = "Alex's Writing",
year = "2024",
month = "Jan",
url = "https://alexzhang13.github.io/blog/2024/neurips2023/"
}