A Mini Exercise on the Mismanaged Geniuses Hypothesis (RLMs on LongCoT)
Alex Zhang, Omar Khattab
I believe it’s worth discussing an example of the Mismanaged Geniuses Hypothesis at play: we underestimate how good language models actually are, and they are inhibited by how we use them.
These days, I feel it’s pretty common to wake up and see a new benchmark come out which shows that “we’re not there yet”. The sense I get from these releases is that, despite perhaps the authors’ best interests, it often leads to the feeling that “the latest frontier model cannot solve a certain category of task”.
I often wonder whether this is really the conclusion we should be drawing nowadays. I want to provide a small case study on LongCoT (Motwani et al. 2026), which is a recent viral benchmark where frontier models fall somewhat short (<10% overall). The thesis is fairly simple: LMs cannot solve complicated compositional reasoning tasks consisting of sub-problems they are able to solve in isolation.

Prelim: Frontier Models and RLMs on LongCoT-mini
I’ll restrict this post to LongCoT-mini, as the problems are structurally the same as the larger benchmark, but (1) there are fewer problems (500 vs. 2500), (2) each problem is easier, but the paper shows current models can’t solve these problems either. I also plan to reserve the full benchmark results for larger, non-blog releases.
In the paper, they report GPT-5.2 as the strongest model, solving 38.7% of LongCoT-mini.
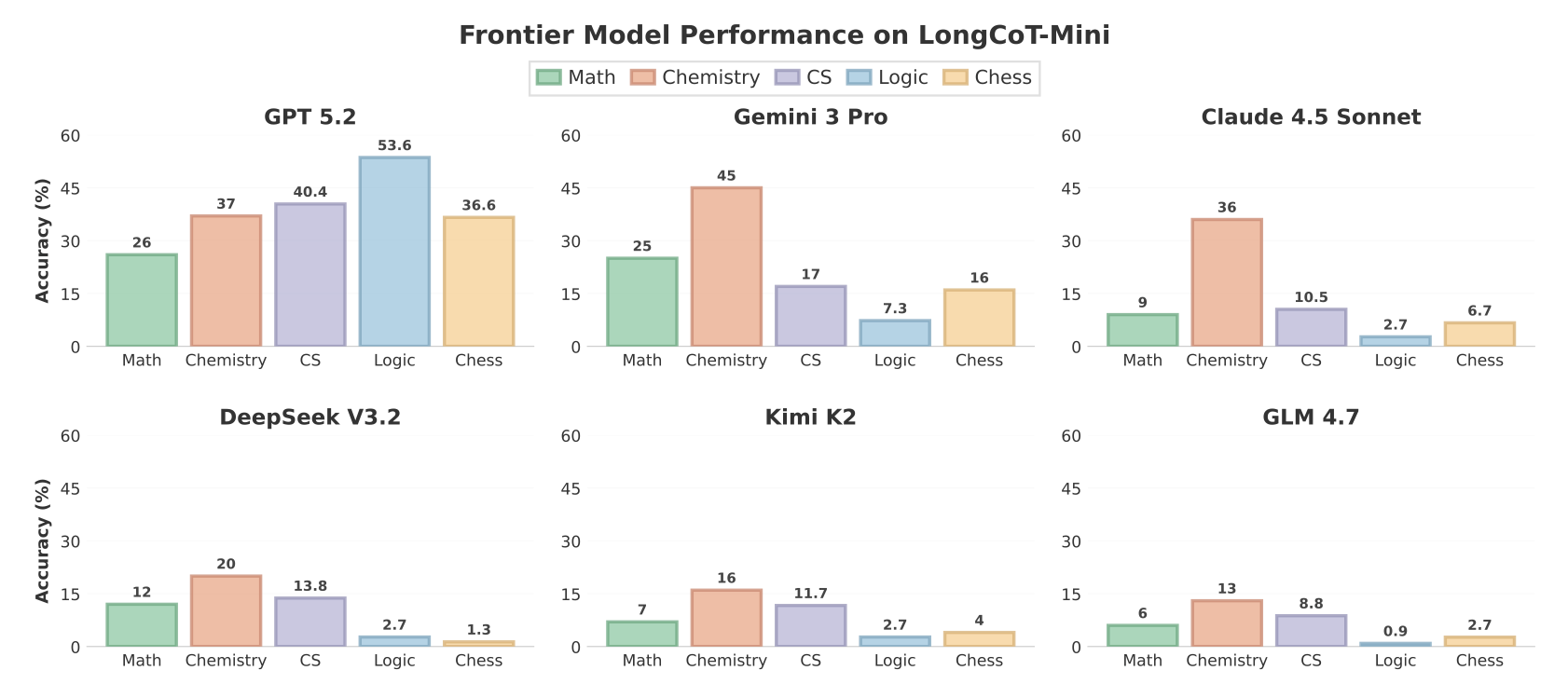
For a reasoning benchmark this is quite significant, considering it is pretty hard to craft problems that LMs have not loosely seen already. Furthermore, despite my intuition that an RLM would absolutely ace this benchmark through composition, it turned out that in most cases the RLM actually reportedly performed worse than the base model itself. The general conclusion, also by the authors, is that RLMs need to be trained for this style of graph-based compositional reasoning.
I wasn’t convinced, but Raymond Weitekamp beat me to the punch; a day after the benchmark’s release, he ran DSPy.RLM on Claude Sonnet 4.5 on LongCoT-mini and found the performance jumped from 13.0% —> 45.4%, a significant jump in performance through possibly a better tuned implementation of the RLM. But what especially stood out to me was 6.3% on MATH and 4% on CS. This is a rather unsatisfactory result, as the authors already pointed out that the RLM’s ability to use a coding environment inflates its performance on CHESS and LOGIC through solvers. So perhaps the conclusion is that RLMs just cannot solve LongCoT tasks (?)
“General method cannot do XYZ” is a VERY strong statement.
All of what I described earlier is summarized in this blurb in Appendix C of the LongCoT paper:
Appendix C. These issues illustrate that context decomposition is different from task decomposition: RLMs work well on problems with sequential or retrievable structure, but as soon as reasoning requires tracking graph-structured dependencies, as most LongCoT problems do, context-folding becomes much harder.
But this is kind of an odd conclusion to me. Nothing about the design of an RLM makes tracking graph dependencies harder than tracking map-reduce style dependencies (they can all be easily described in code). And sure, maybe the takeaway is that training an RLM will solve these issues, but can GPT-5.2 with an RLM really not perform programmatic task decomposition?
I decided to compare against GPT-5.2, as it was the strongest performing model reported on the benchmark. And it turned out, similar to Raymond’s results, despite stronger overall performance relative to GPT-5.2 (38.7% —> 50.6%), RLM(GPT-5.2) struggled on the MATH and CS splits!
| Method | Total | MATH | CHEM | CS | LOGIC | CHESS |
|---|---|---|---|---|---|---|
| Raymond Weitekamp’s DSPy.RLM + Claude Sonnet 4.5 | 45.4% | 6.3% | 31.0% | 4.0% | 96.2% | 85.0% |
| RLM(GPT-5.2) | 50.6% | 5.6% | 50.0% | 11.0% | 86.7% | 93.0% |
| GPT-5.2 (base) | 38.7% | 26.0% | 37.0% | 40.4% | 53.6% | 36.6% |
Now against @Xeophon’s best wishes, I started manually examining RLM traces. It turned out in the majority of cases that the RLM was timing out, as it would attempt to solve a MATH or CS node using a pure brute-force approach, crashing the REPL and failing the trajectory (oops, perfectly guardrail-able with a better RLM implementation). Furthermore, the model would sometimes realize it could decompose the graph into sub-problems and launch sub-agents over these sub-problems, but would rarely check whether the sub-agent actually got the sub-problem correct. These all seemed like silly decision-making issues on the part of the LM, which seemingly had more to do with how we chose to prompt the RLM, rather than its inability to solve the task.
So overnight, I asked Claude Code to look at the trajectories, write tips for the RLM to not make mistakes, and restart the run on LongCoT-mini. When I woke up in the morning, the updated results were as follows:
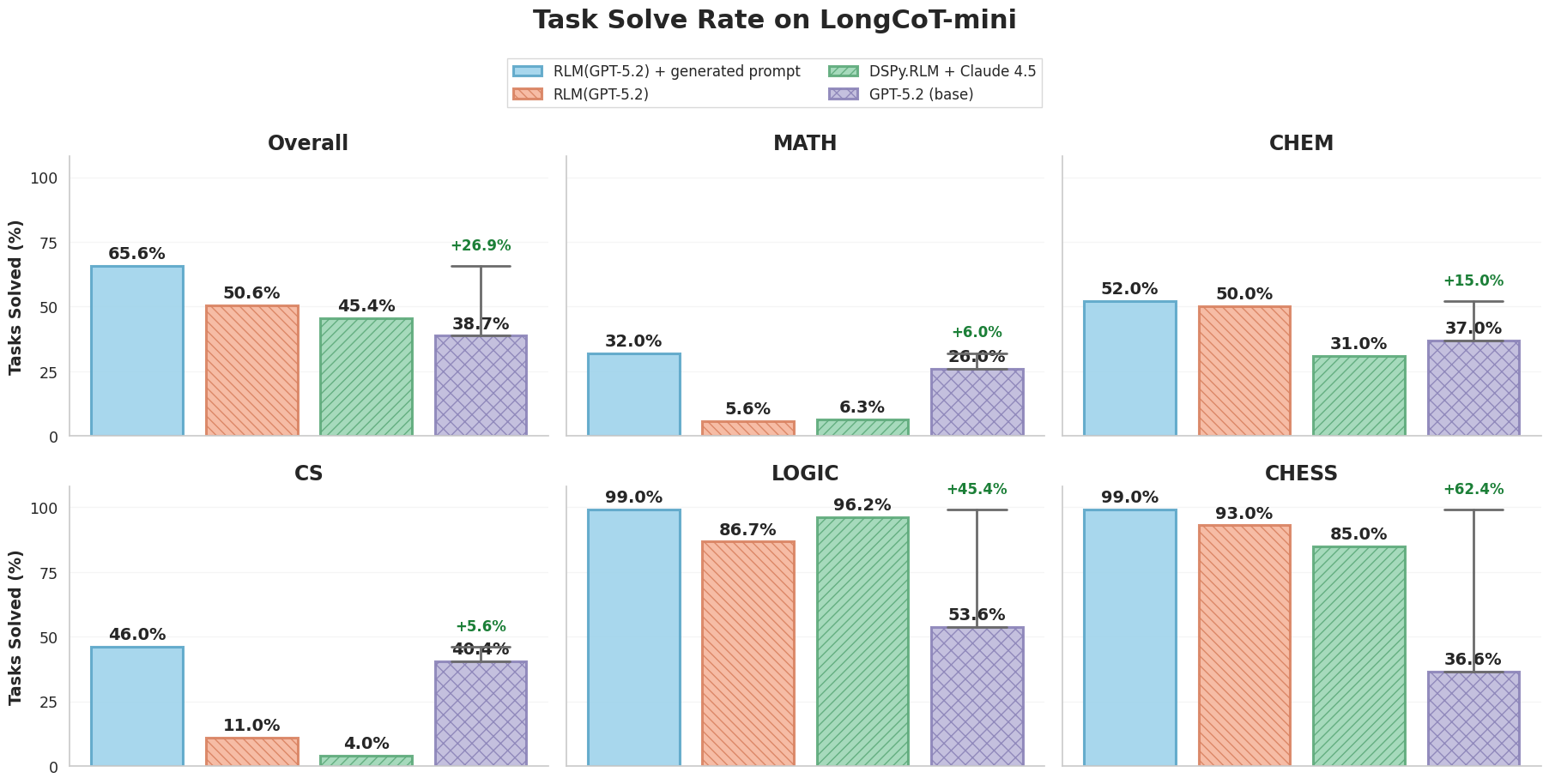
Not only did it greatly increase performance across the board, the overall performance jumped from 38.7% —> 65.6%. I also tracked partial rewards (i.e. many tasks ask for multiple answers which all need to be correct, and the model sometimes gets one wrong) which jumped the performance to well above 70%! I’m pretty confident we could further push these scores, but I think the point I’m trying to make is well illustrated from this jump alone.
Remark. I also asked it to write a similar set of tips for the LM to use as an ablation of the value of the RLM mechanism itself. I actually iterated on these prompts more than the RLM prompt, but generally just found worse performance versus the base prompt. Unfortunately, even though the LM becomes aware of the right decomposition, it is difficult for a pure reasoning language model to track and perform these decompositions through chain-of-thought.
Remark 2. The prompt is found in the trajectories repository (see Resources at the bottom), and is the same across all tasks. It describes the graph structure of LongCoT problems, an example of how to solve a fake problem, and tips for not brute-forcing problems. It illustrates that RLMs performing the correct decompositions are powerful, and ideally in the long run we want them to come up with these strategies on the fly from minimal prompting.
What does this mean for LMs, RLMs, and RLM training
There are some interesting takeaways from this mini experiment beyond the Mismanaged Geniuses Hypothesis that relate to training, and more specifically post-training on RLMs. We already knew that steering models with better prompts could yield wildly different results (my advisor has a whole collection of papers on this topic), but I think this effect is exaggerated with systems like RLMs that equip models with significantly more expressive capabilities.
While we would like to naively bootstrap out RLM-like behavior from pure RL, it is becoming somewhat apparent that maybe we’ll have to steer models a bit through prompting while generating trajectories, then gradually remove these priors. Luckily, from this mini experiment it seems frontier models themselves are perfectly capable of doing this: the prompt generated for RLM(GPT-5.2) was made by Claude Code itself. In some sense, the LM itself can recognize the decomposition an RLM needs to do!
In general, our intuition about how an RLM should behave is likely sub-optimal, but it turns out to be better than what the frontier models choose to do. I’d like to get to the point where, like a Move 37 scenario, the RLM makes decisions that we do not understand, but ultimately are significantly better than the decompositions we come up with. For now though, it seems a valid strategy in the short term to avoid sparse rewards and steer.
What was the point of this exercise? I don’t have a great way to conclude the writing, so I’ll just be straightforward. Based on the MGH, I think our understanding of model capabilities is still quite poor. As someone who spent a lot of time building benchmarks, I have felt it extremely hard to curate novel problems that modern models truly cannot solve. Even without additional training, we can squeeze out a significant improvement in performance in harnesses like RLMs just by nudging it on the structure of a problem. It really is an exciting time, so let’s please be responsible!
Resources
- Trajectories and visualizer for the main experiment above: https://github.com/alexzhang13/longcot-mini-rlm-results
- LongCoT Dataset: https://huggingface.co/datasets/LongHorizonReasoning/longcot
- LongCoT Repository: https://github.com/LongHorizonReasoning/longcot
- LongCoT paper: https://arxiv.org/abs/2604.14140
- Raymond Weitekamp’s blog on RLMs: https://raw.works/longcot-a-benchmark-worthy-of-a-rlms-attention/
- Recursive Language Models (RLM) paper: https://arxiv.org/abs/2512.24601
- My RLM implementation: https://github.com/alexzhang13/rlm
- Prime Intellect’s RLM implementation in verifiers: https://github.com/PrimeIntellect-ai/verifiers/blob/main/verifiers/envs/experimental/rlm_env.py