The Mismanaged Geniuses Hypothesis
Alex Zhang, Zhening (Zed) Li, and Omar Khattab.
tldr; AI models are already good enough for the next leap in capabilities.
For the last decade, scaling the size and data of AI models has led to groundbreaking, super-human achievements in the capabilities of these systems. The recent success of RL and reasoning in particular implies that models can be trained to generalize on tasks we have never even solved ourselves. It is natural to believe that continuing this trend of scaling across a single neural model will be the recipe that gets us to the next jump in AI capabilities.
We have an alternate hypothesis on what will take us to the next inflection point of AI systems.
It can be said that frontier language models (LMs) are “geniuses” at solving the broad range of tasks they’ve been trained on. Nowadays, this represents virtually all the advanced subjects and content we learn throughout higher education to prepare ourselves for researching unsolved problems. Yet despite the fact that these models outperform even the brightest humans on the hardest exams like IMO and IOI and are super-human at general software engineering, they oddly also struggle to reliably tackle long-horizon and iterative reasoning problems that may seem “easy” to us. It is an interesting thought experiment to consider whether this is an inherent limitation of the LM, or the way in which we use them.
The mismanaged geniuses hypothesis (MGH) posits that existing frontier language models are severely underutilized due to sub-optimal use of individual language model calls. We believe that the next leap in “language model” capabilities will come not from continued scaling of existing LMs, but from enabling language models to “manage” themselves, i.e. natively decompose tasks and act on these decompositions. In particular, we believe that existing systems that let LMs decompose tasks are the limiting bottleneck, and the first step would be to define the space of decompositions the LM has access to. Upon figuring out this space of decompositions, the “bitter-lesson”-pilled allocation of compute would go towards training models to perform the correct decompositions.
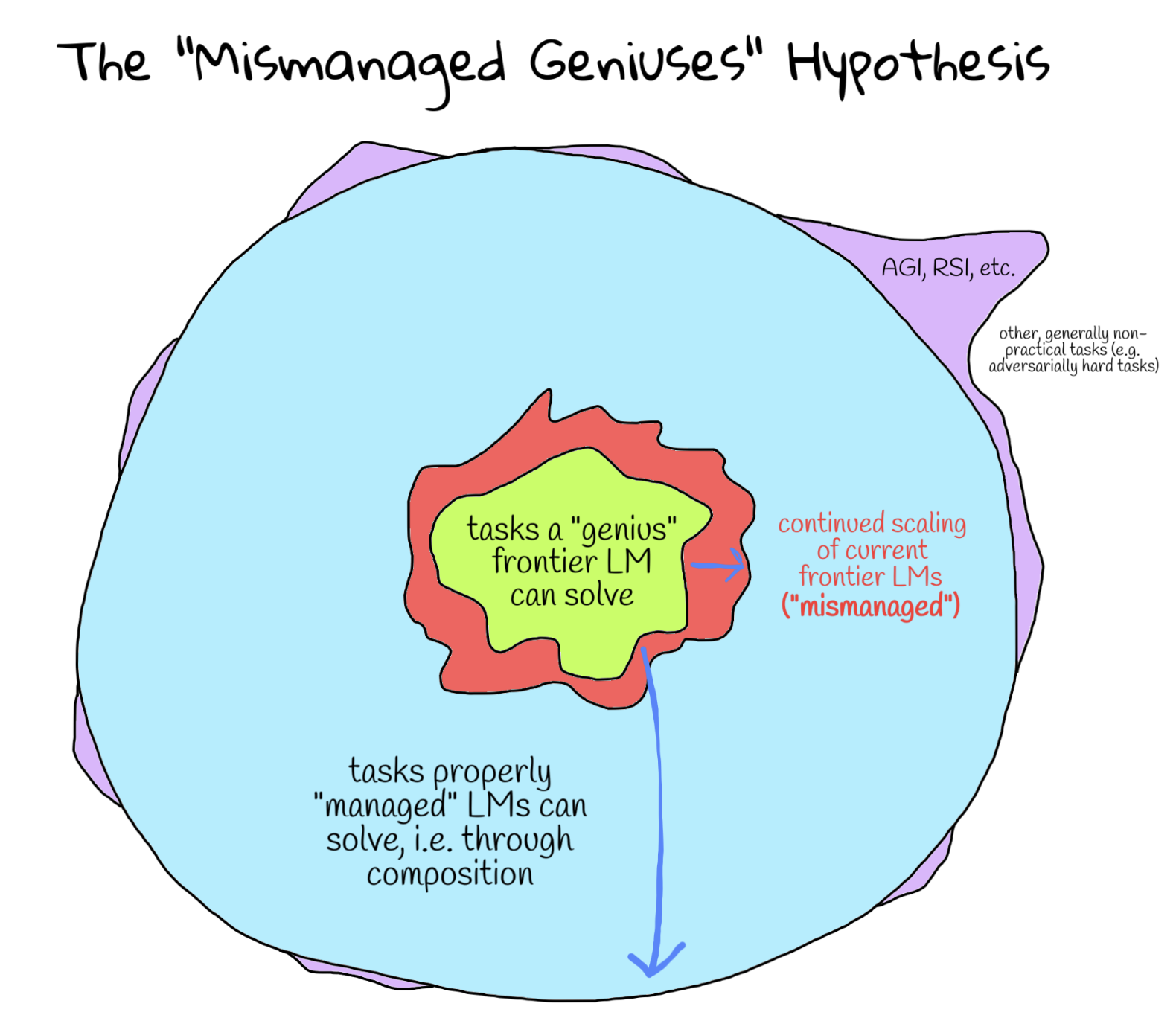
You and I are not good managers.
It is worth articulating the “mismanagement” of language models.
Nearly all modern agent scaffolds are human-engineered, task-specific decomposition strategies that use language models. These systems rely on our intuition about how individual language model calls can be used together to solve a larger problem, and are often brittle with respect to different models and different problems. The outcome is a diverse set of agent scaffolds that can only solve narrow problems and must frequently be updated, leading to a misrepresentation of how good language models “actually are” at any given time. As an example, is it really true that frontier language models cannot play certain video games at a human level, or is it just that we haven’t put in the effort to build a good scaffold around them?
Coding agents like Claude Code are a first step in enabling the language model itself to decompose a problem into sub-tasks, then launch subagents to solve each sub-task. These “orchestrator-subagent” systems, where the orchestrator LM outputs a rough plan of how its going to go about solving a task, and then executes this plan using subagents, have been shown to work extremely well for general human-like workflows (e.g. for software engineering). Furthermore, it turns out that the plans that these models generate tend to be intuitive and easy to describe: the model does not need to know the exact solution to a problem to outline how it may go about decomposing it!
The success of these more general scaffolds like Claude Code, OpenClaw, Hermes Agent, etc. suggest that LMs are perfectly capable of managing other LMs to solve longer-horizon tasks. Furthermore, it is natural to ask whether the “orchestrator-subagent” scaffold is sufficient for longer running tasks, with recent works like Recursive Language Models (RLMs) proposing a more expressive mechanism for describing “plans” through code execution with recursive sub-calls / tools as functions, enabling fully recursive task decomposition. In particular, RLMs show how expanding the space of decompositions used to manage LM sub-calls beyond API-based tool calling unlocks length generalization capabilities for LMs.
Whether it be RLMs, coding agents, or undiscovered systems, a key unknown is the right general scaffold to train over that fully enables LMs to properly manage LMs.
Using composition to get around the out-of-distribution (OOD) problem.
So where do we go from here, and how can we fix the “mismanagement” issue?
To preface, it is well known that neural network language models have a generalization problem. Rather unsurprisingly, they naturally struggle to generalize to longer lengths (i.e. context rot) and low-resource tasks (e.g. as of the time of writing, writing GPU kernels on Blackwell).
One interpretation of the mismanaged geniuses hypothesis is that within the bounds of what is considered “in-distribution” for frontier language models, there already exists a powerful general “language model” system that can solve OOD problems in which its individual LM calls only see in-distribution inputs. Based on our intuition for scaffolds that currently work (e.g. Claude Code, RLMs, etc.), this loosely involves decomposing tasks into sub-tasks that the LM can solve, where the act of “decomposing the task” itself must also be an “in-distribution” task for the LM!
More generally, composition is an efficient way to solve OOD tasks in a learning-based system that is sufficiently capable. To be specific, the MGH posits that modern LMs are so good yet so expensive to further train, that directly learning the operator to compose LMs is a significantly more efficient strategy for reaching these OOD tasks than continuing to scale current LMs.
Assuming the MGH is actually true, we believe there are two main research / engineering directions in creating these systems:
-
Defining “decomposition”. Defining the space of decompositions the LM is allowed to express is important for ensuring the individual LM calls stay “in-distribution”. How we define “decomposition” has an exponentially large impact (with respect to depth) on the tasks solvable via decomposition. In long-context tasks, for example, tool-call-style subagents prevent the root LM from decomposing the context into arbitrarily many chunks, inhibiting its ability to scale. In RLMs, the space of decompositions is expanded so as to allow an efficient representation of decomposition into arbitrarily many subtasks (e.g. using a
forloop), which suddenly enables the system to handle near-infinite context. Similarly, simple expansions to the space of decompositions, compounded by the effect of recursion, may suddenly unlock generalization to near-infinite long-horizon tasks, self-improvement, and more. -
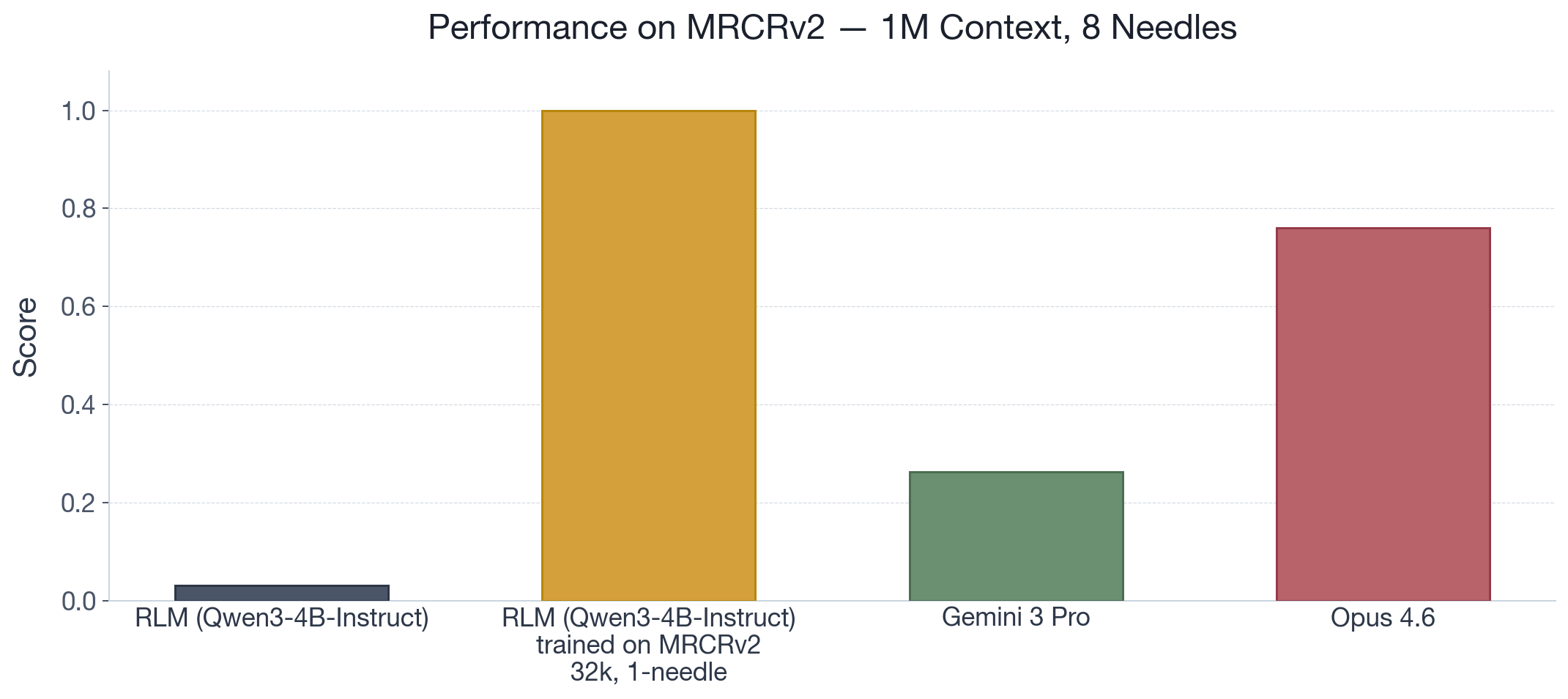
Training and scaling the ability to compose. LMs need to be trained to correctly decompose tasks under any scaffold, but the correct decompositions are likely already within the distribution of what LMs can generate. To provide an example, we examine MRCRv2 1M context with 8 needles, a commonly reported long-context benchmark for frontier models. We find that while
RLM(Qwen3-4B-Instruct)solves nearly 0% of the tasks, it gets 100% after only RL training on a significantly simpler setting (32k context, 1 needle). Despite being a small model, it learns purely through its own rollouts the correct decomposition that generalizes.
An exciting corollary of this hypothesis is that it implies that most of the necessary behavior that the model needs to learn during pre-training and mid-training is likely already there. Given a sufficiently well-designed scaffold that supports composition (e.g. RLMs), training out such a system through bootstrapping may be enough to draw out a general task solving system.
Language models have gotten to the point where they’re ridiculously powerful, and the bottlenecks to creating fancy things like long-horizon solvers or self-improving systems seem sort of silly (i.e. is length generalization really a concern). Should the MGH be true, the problem that remains is managing the geniuses (with guardrails, of course).
Acknowledgements. We thank Armando Solar-Lezama and Matthew Ho for helpful feedback.