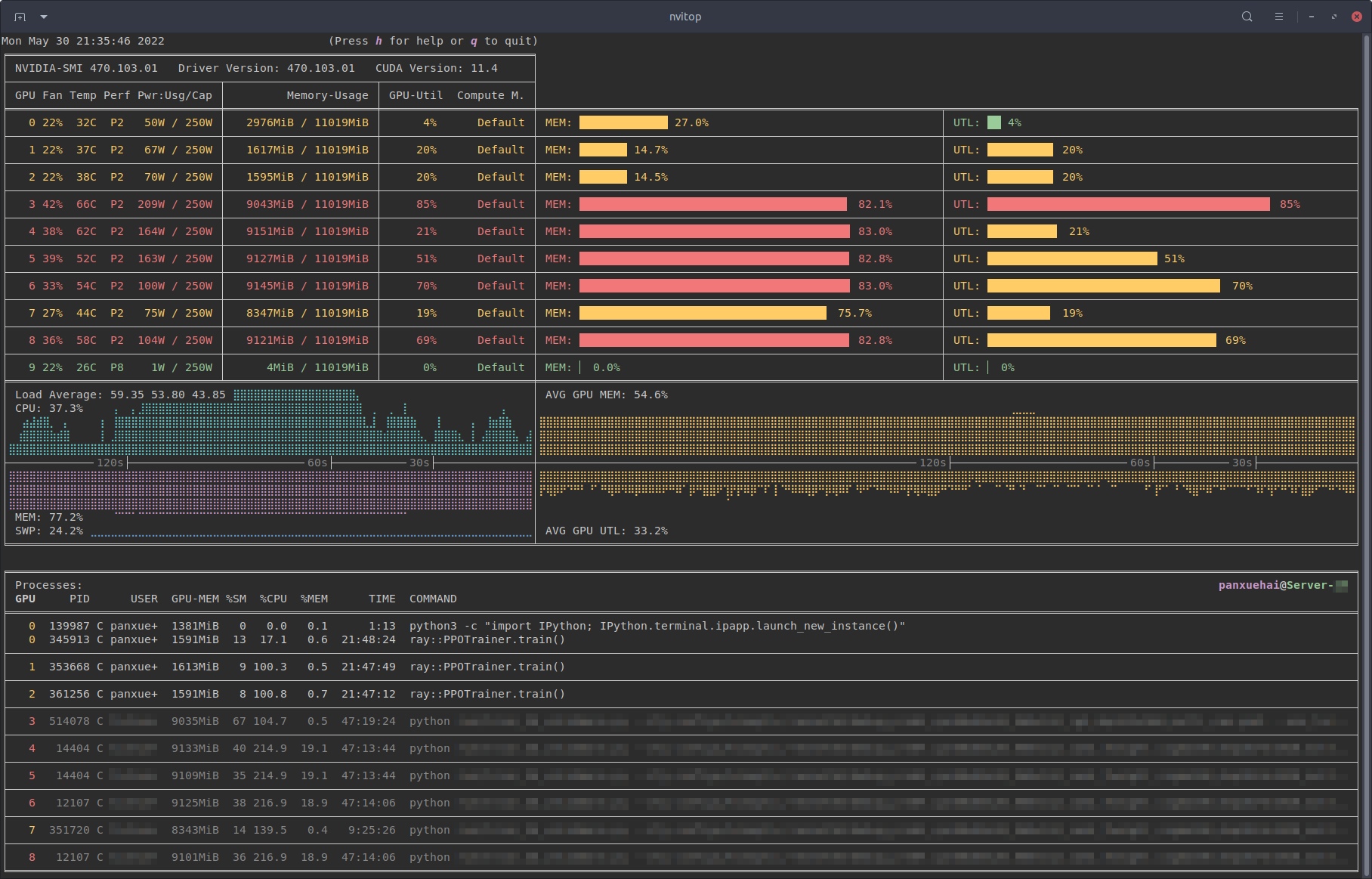
Jekyll2026-06-15T21:05:50+00:00https://alexzhang13.github.io/feed.xmlblankAlex Zhang's Website.
A Mini Exercise on the Mismanaged Geniuses Hypothesis (RLMs on LongCoT)2026-04-26T00:00:00+00:002026-04-26T00:00:00+00:00https://alexzhang13.github.io/blog/2026/longcot-rlmAlex Zhang, Omar Khattab
I believe it’s worth discussing an example of the Mismanaged Geniuses Hypothesis at play: we underestimate how good language models actually are, and they are inhibited by how we use them.
These days, I feel it’s pretty common to wake up and see a new benchmark come out which shows that “we’re not there yet”. The sense I get from these releases is that, despite perhaps the authors’ best interests, it often leads to the feeling that “the latest frontier model cannot solve a certain category of task”.
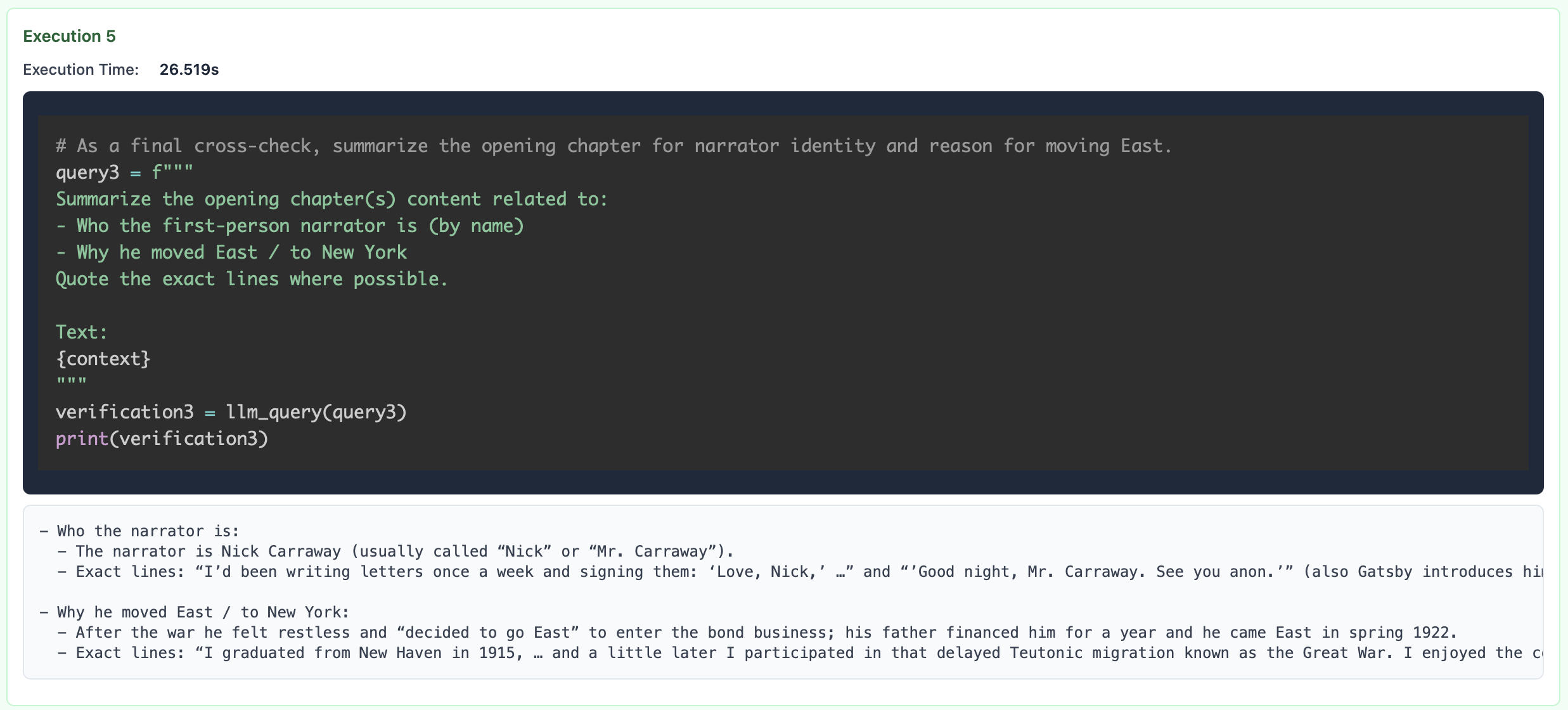
I often wonder whether this is really the conclusion we should be drawing nowadays. I want to provide a small case study on LongCoT (Motwani et al. 2026), which is a recent viral benchmark where frontier models fall somewhat short (<10% overall). The thesis is fairly simple: LMs cannot solve complicated compositional reasoning tasks consisting of sub-problems they are able to solve in isolation.
Taken from Figure 2 of the LongCoT paper. A LongCoT / LongCoT-mini task consists of a graph (often DAG) where each node is a sub-problem. The sub-problem relies on answers to incoming nodes, and these answers are needed to solve outgoing nodes.
Prelim: Frontier Models and RLMs on LongCoT-mini
I’ll restrict this post to LongCoT-mini, as the problems are structurally the same as the larger benchmark, but (1) there are fewer problems (500 vs. 2500), (2) each problem is easier, but the paper shows current models can’t solve these problems either. I also plan to reserve the full benchmark results for larger, non-blog releases.
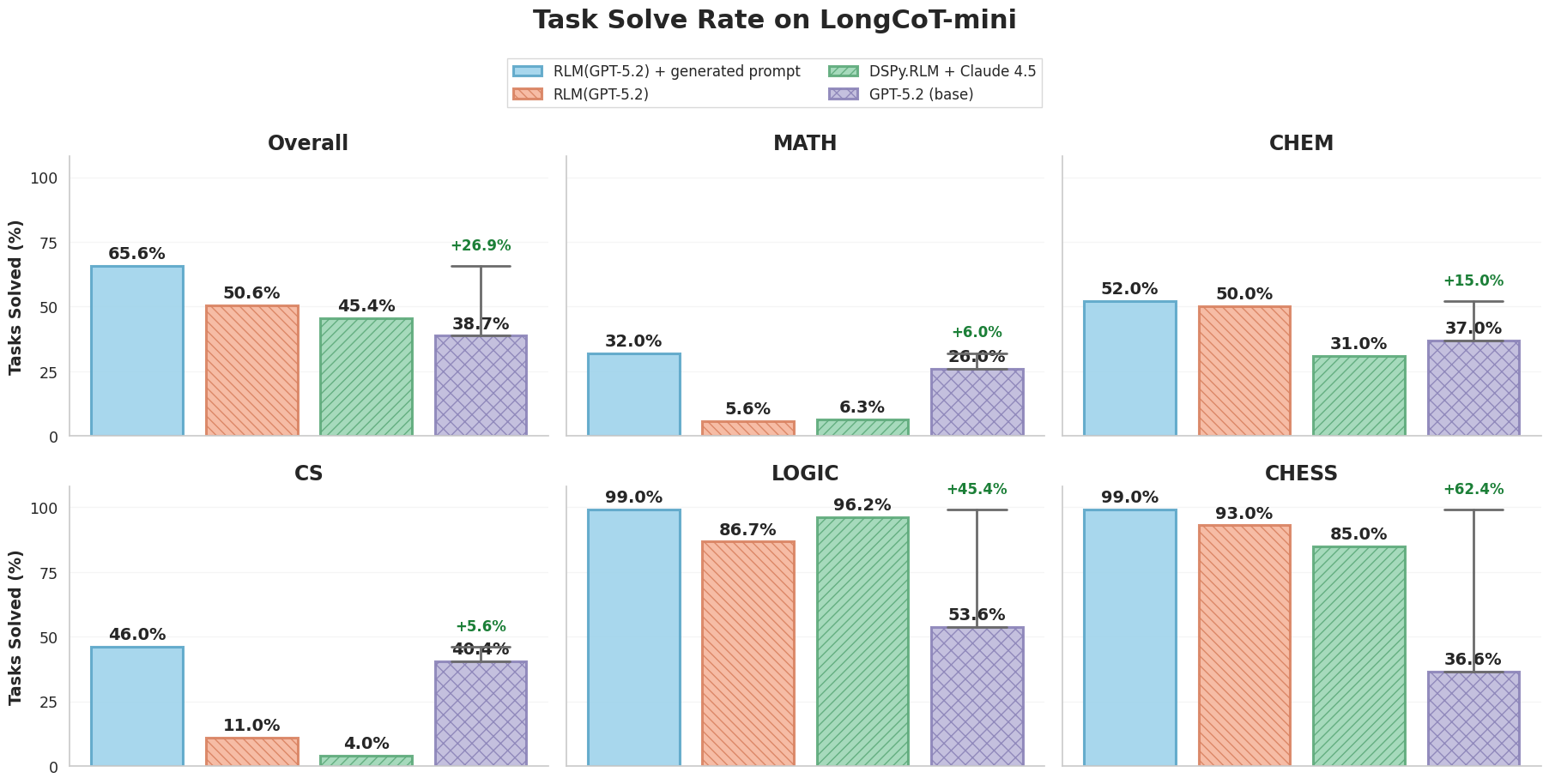
In the paper, they report GPT-5.2 as the strongest model, solving 38.7% of LongCoT-mini.
The LongCoT paper reports scores for frontier models on LongCoT-mini in Figure 9. The performance is generally low across the board, with the highest scoring model (GPT-5.2) solving 38.7% of tasks.
For a reasoning benchmark this is quite significant, considering it is pretty hard to craft problems that LMs have not loosely seen already. Furthermore, despite my intuition that an RLM would absolutely ace this benchmark through composition, it turned out that in most cases the RLM actually reportedly performed worse than the base model itself. The general conclusion, also by the authors, is that RLMs need to be trained for this style of graph-based compositional reasoning.
I wasn’t convinced, but Raymond Weitekamp beat me to the punch; a day after the benchmark’s release, he ran DSPy.RLM on Claude Sonnet 4.5 on LongCoT-mini and found the performance jumped from 13.0% —> 45.4%, a significant jump in performance through possibly a better tuned implementation of the RLM. But what especially stood out to me was 6.3% on MATH and 4% on CS. This is a rather unsatisfactory result, as the authors already pointed out that the RLM’s ability to use a coding environment inflates its performance on CHESS and LOGIC through solvers. So perhaps the conclusion is that RLMs just cannot solve LongCoT tasks (?)
“General method cannot do XYZ” is a VERY strong statement.
All of what I described earlier is summarized in this blurb in Appendix C of the LongCoT paper:
Appendix C. These issues illustrate that context decomposition is different from task decomposition: RLMs work well on problems with sequential or retrievable structure, but as soon as reasoning requires tracking graph-structured dependencies, as most LongCoT problems do, context-folding becomes much harder.
But this is kind of an odd conclusion to me. Nothing about the design of an RLM makes tracking graph dependencies harder than tracking map-reduce style dependencies (they can all be easily described in code). And sure, maybe the takeaway is that training an RLM will solve these issues, but can GPT-5.2 with an RLM really not perform programmatic task decomposition?
I decided to compare against GPT-5.2, as it was the strongest performing model reported on the benchmark. And it turned out, similar to Raymond’s results, despite stronger overall performance relative to GPT-5.2 (38.7% —> 50.6%), RLM(GPT-5.2) struggled on the MATH and CS splits!
Method
Total
MATH
CHEM
CS
LOGIC
CHESS
Raymond Weitekamp’s DSPy.RLM + Claude Sonnet 4.5
45.4%
6.3%
31.0%
4.0%
96.2%
85.0%
RLM(GPT-5.2)
50.6%
5.6%
50.0%
11.0%
86.7%
93.0%
GPT-5.2 (base)
38.7%
26.0%
37.0%
40.4%
53.6%
36.6%
Now against @Xeophon’s best wishes, I started manually examining RLM traces. It turned out in the majority of cases that the RLM was timing out, as it would attempt to solve a MATH or CS node using a pure brute-force approach, crashing the REPL and failing the trajectory (oops, perfectly guardrail-able with a better RLM implementation). Furthermore, the model would sometimes realize it could decompose the graph into sub-problems and launch sub-agents over these sub-problems, but would rarely check whether the sub-agent actually got the sub-problem correct. These all seemed like silly decision-making issues on the part of the LM, which seemingly had more to do with how we chose to prompt the RLM, rather than its inability to solve the task.
So overnight, I asked Claude Code to look at the trajectories, write tips for the RLM to not make mistakes, and restart the run on LongCoT-mini. When I woke up in the morning, the updated results were as follows:
Not only did it greatly increase performance across the board, the overall performance jumped from 38.7% —> 65.6%. I also tracked partial rewards (i.e. many tasks ask for multiple answers which all need to be correct, and the model sometimes gets one wrong) which jumped the performance to well above 70%! I’m pretty confident we could further push these scores, but I think the point I’m trying to make is well illustrated from this jump alone.
Remark. I also asked it to write a similar set of tips for the LM to use as an ablation of the value of the RLM mechanism itself. I actually iterated on these prompts more than the RLM prompt, but generally just found worse performance versus the base prompt. Unfortunately, even though the LM becomes aware of the right decomposition, it is difficult for a pure reasoning language model to track and perform these decompositions through chain-of-thought.
Remark 2. The prompt is found in the trajectories repository (see Resources at the bottom), and is the same across all tasks. It describes the graph structure of LongCoT problems, an example of how to solve a fake problem, and tips for not brute-forcing problems. It illustrates that RLMs performing the correct decompositions are powerful, and ideally in the long run we want them to come up with these strategies on the fly from minimal prompting.
What does this mean for LMs, RLMs, and RLM training
There are some interesting takeaways from this mini experiment beyond the Mismanaged Geniuses Hypothesis that relate to training, and more specifically post-training on RLMs. We already knew that steering models with better prompts could yield wildly different results (my advisor has a whole collection of papers on this topic), but I think this effect is exaggerated with systems like RLMs that equip models with significantly more expressive capabilities.
While we would like to naively bootstrap out RLM-like behavior from pure RL, it is becoming somewhat apparent that maybe we’ll have to steer models a bit through prompting while generating trajectories, then gradually remove these priors. Luckily, from this mini experiment it seems frontier models themselves are perfectly capable of doing this: the prompt generated for RLM(GPT-5.2) was made by Claude Code itself. In some sense, the LM itself can recognize the decomposition an RLM needs to do!
In general, our intuition about how an RLM should behave is likely sub-optimal, but it turns out to be better than what the frontier models choose to do. I’d like to get to the point where, like a Move 37 scenario, the RLM makes decisions that we do not understand, but ultimately are significantly better than the decompositions we come up with. For now though, it seems a valid strategy in the short term to avoid sparse rewards and steer.
What was the point of this exercise? I don’t have a great way to conclude the writing, so I’ll just be straightforward. Based on the MGH, I think our understanding of model capabilities is still quite poor. As someone who spent a lot of time building benchmarks, I have felt it extremely hard to curate novel problems that modern models truly cannot solve. Even without additional training, we can squeeze out a significant improvement in performance in harnesses like RLMs just by nudging it on the structure of a problem. It really is an exciting time, so let’s please be responsible!
tldr; AI models are already good enough for the next leap in capabilities.
For the last decade, scaling the size and data of AI models has led to groundbreaking, super-human achievements in the capabilities of these systems. The recent success of RL and reasoning in particular implies that models can be trained to generalize on tasks we have never even solved ourselves. It is natural to believe that continuing this trend of scaling across a single neural model will be the recipe that gets us to the next jump in AI capabilities.
We have an alternate hypothesis on what will take us to the next inflection point of AI systems.
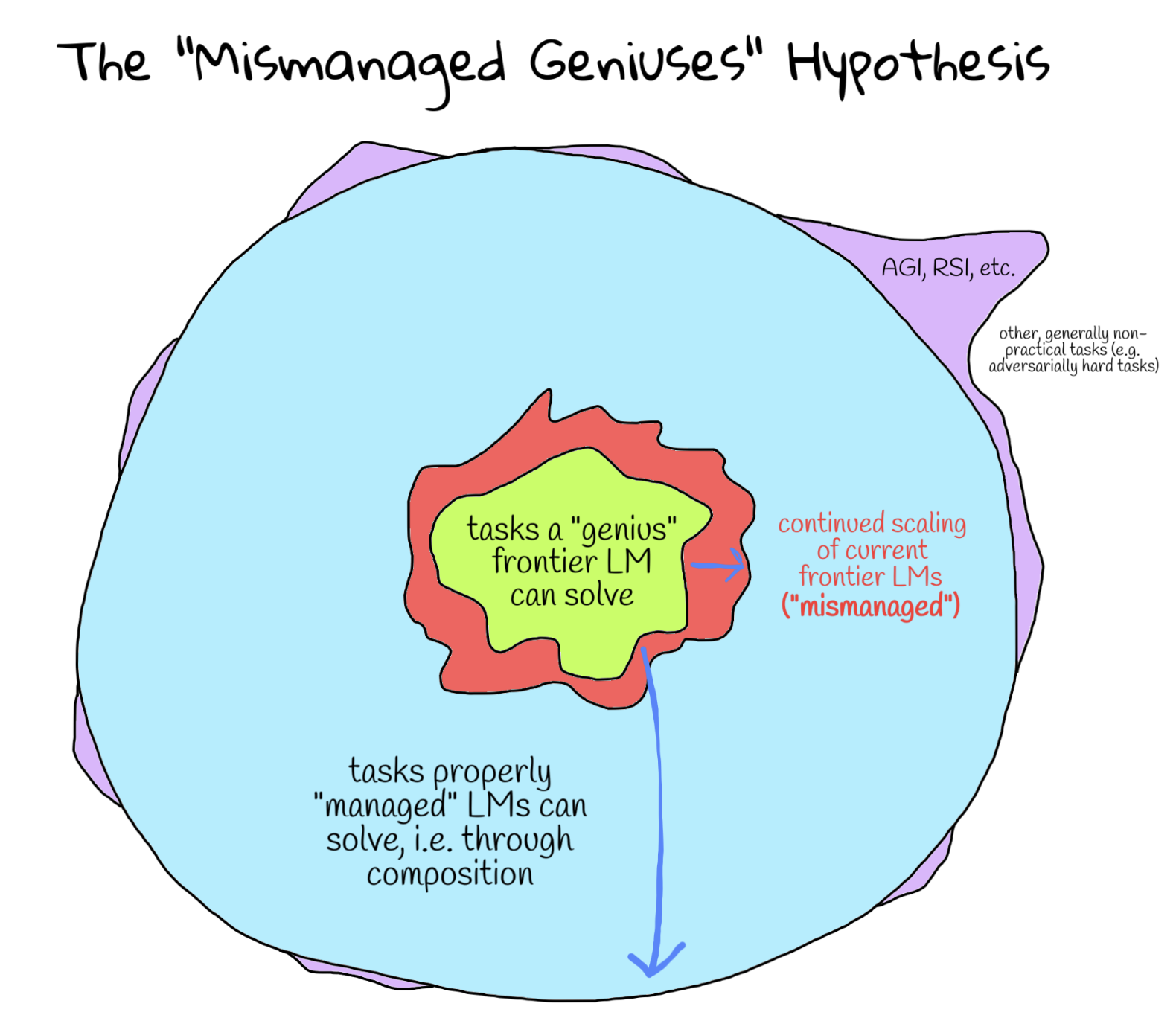
It can be said that frontier language models (LMs) are “geniuses” at solving the broad range of tasks they’ve been trained on. Nowadays, this represents virtually all the advanced subjects and content we learn throughout higher education to prepare ourselves for researching unsolved problems. Yet despite the fact that these models outperform even the brightest humans on the hardest exams like IMO and IOI and are super-human at general software engineering, they oddly also struggle to reliably tackle long-horizon and iterative reasoning problems that may seem “easy” to us. It is an interesting thought experiment to consider whether this is an inherent limitation of the LM, or the way in which we use them.
The mismanaged geniuses hypothesis (MGH) posits that existing frontier language models are severely underutilized due to sub-optimal use of individual language model calls. We believe that the next leap in “language model” capabilities will come not from continued scaling of existing LMs, but from enabling language models to “manage” themselves, i.e. natively decompose tasks and act on these decompositions. In particular, we believe that existing systems that let LMs decompose tasks are the limiting bottleneck, and the first step would be to define the space of decompositions the LM has access to. Upon figuring out this space of decompositions, the “bitter-lesson”-pilled allocation of compute would go towards training models to perform the correct decompositions.
Figure 1. The "mismanaged geniuses" hypothesis posits that current ways of using LMs ("geniuses") remain far from unlocking their full potential because current systems built to "manage" them (e.g. human-engineered agents) are suboptimal. We propose that instead of continuing to scale frontier LMs using current methods (in red), we should focus on the "management" or decomposition aspect itself. We believe that training LMs to learn to decompose is a significantly more efficient path towards expanding LM capabilities (in blue) and could potentially unlock solutions to many tasks we care about (in purple, e.g. open scientific problems, long-horizon autonomous agents, self-improvement, etc.). In particular, a key determining factor of the success of this approach is the space of decompositions that "manager" LMs have access to and the language in which they are expressed.
You and I are not good managers.
It is worth articulating the “mismanagement” of language models.
Nearly all modern agent scaffolds are human-engineered, task-specific decomposition strategies that use language models. These systems rely on our intuition about how individual language model calls can be used together to solve a larger problem, and are often brittle with respect to different models and different problems. The outcome is a diverse set of agent scaffolds that can only solve narrow problems and must frequently be updated, leading to a misrepresentation of how good language models “actually are” at any given time. As an example, is it really true that frontier language models cannot play certain video games at a human level, or is it just that we haven’t put in the effort to build a good scaffold around them?
Coding agents like Claude Code are a first step in enabling the language model itself to decompose a problem into sub-tasks, then launch subagents to solve each sub-task. These “orchestrator-subagent” systems, where the orchestrator LM outputs a rough plan of how its going to go about solving a task, and then executes this plan using subagents, have been shown to work extremely well for general human-like workflows (e.g. for software engineering). Furthermore, it turns out that the plans that these models generate tend to be intuitive and easy to describe: the model does not need to know the exact solution to a problem to outline how it may go about decomposing it!
The success of these more general scaffolds like Claude Code, OpenClaw, Hermes Agent, etc. suggest that LMs are perfectly capable of managing other LMs to solve longer-horizon tasks. Furthermore, it is natural to ask whether the “orchestrator-subagent” scaffold is sufficient for longer running tasks, with recent works like Recursive Language Models (RLMs) proposing a more expressive mechanism for describing “plans” through code execution with recursive sub-calls / tools as functions, enabling fully recursive task decomposition. In particular, RLMs show how expanding the space of decompositions used to manage LM sub-calls beyond API-based tool calling unlocks length generalization capabilities for LMs.
Whether it be RLMs, coding agents, or undiscovered systems, a key unknown is the right general scaffold to train over that fully enables LMs to properly manage LMs.
Using composition to get around the out-of-distribution (OOD) problem.
So where do we go from here, and how can we fix the “mismanagement” issue?
To preface, it is well known that neural network language models have a generalization problem. Rather unsurprisingly, they naturally struggle to generalize to longer lengths (i.e. context rot) and low-resource tasks (e.g. as of the time of writing, writing GPU kernels on Blackwell).
One interpretation of the mismanaged geniuses hypothesis is that within the bounds of what is considered “in-distribution” for frontier language models, there already exists a powerful general “language model” system that can solve OOD problems in which its individual LM calls only see in-distribution inputs. Based on our intuition for scaffolds that currently work (e.g. Claude Code, RLMs, etc.), this loosely involves decomposing tasks into sub-tasks that the LM can solve, where the act of “decomposing the task” itself must also be an “in-distribution” task for the LM!
More generally, composition is an efficient way to solve OOD tasks in a learning-based system that is sufficiently capable. To be specific, the MGH posits that modern LMs are so good yet so expensive to further train, that directly learning the operator to compose LMs is a significantly more efficient strategy for reaching these OOD tasks than continuing to scale current LMs.
Assuming the MGH is actually true, we believe there are two main research / engineering directions in creating these systems:
Defining “decomposition”. Defining the space of decompositions the LM is allowed to express is important for ensuring the individual LM calls stay “in-distribution”. How we define “decomposition” has an exponentially large impact (with respect to depth) on the tasks solvable via decomposition. In long-context tasks, for example, tool-call-style subagents prevent the root LM from decomposing the context into arbitrarily many chunks, inhibiting its ability to scale. In RLMs, the space of decompositions is expanded so as to allow an efficient representation of decomposition into arbitrarily many subtasks (e.g. using a for loop), which suddenly enables the system to handle near-infinite context. Similarly, simple expansions to the space of decompositions, compounded by the effect of recursion, may suddenly unlock generalization to near-infinite long-horizon tasks, self-improvement, and more.
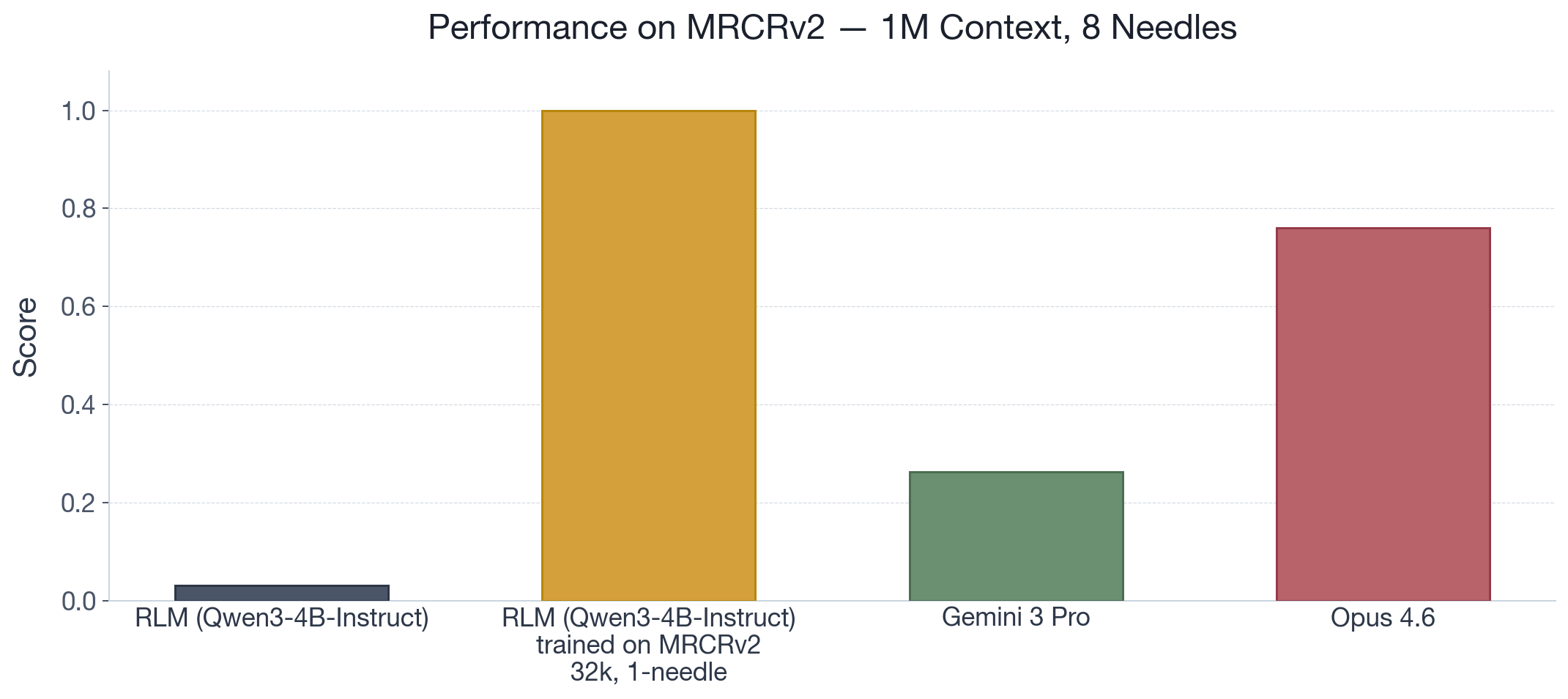
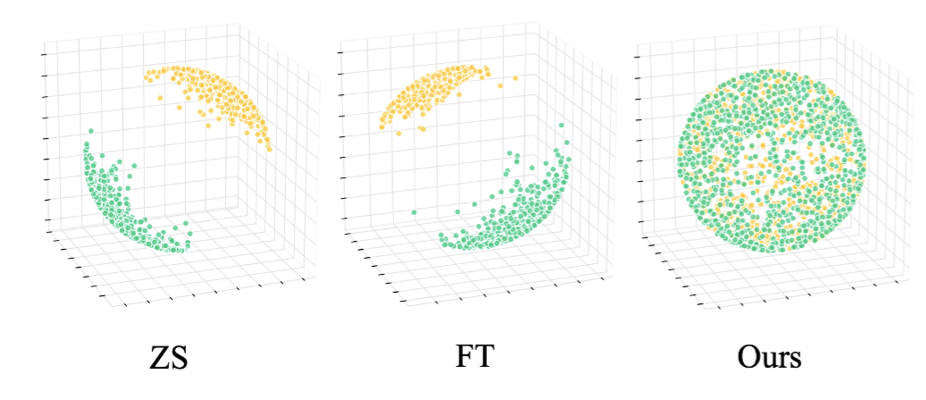
Training and scaling the ability to compose. LMs need to be trained to correctly decompose tasks under any scaffold, but the correct decompositions are likely already within the distribution of what LMs can generate. To provide an example, we examine MRCRv2 1M context with 8 needles, a commonly reported long-context benchmark for frontier models. We find that while RLM(Qwen3-4B-Instruct) solves nearly 0% of the tasks, it gets 100% after only RL training on a significantly simpler setting (32k context, 1 needle). Despite being a small model, it learns purely through its own rollouts the correct decomposition that generalizes.
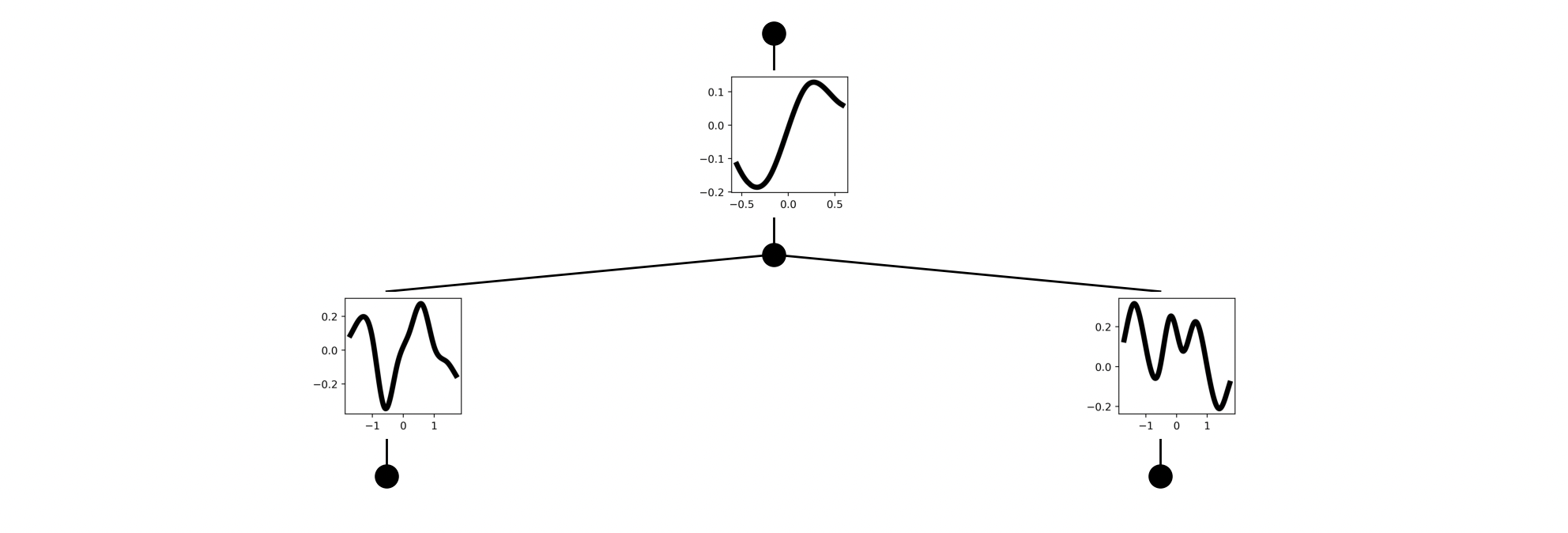
Figure 2. We provide evidence for two points: 1) decomposition for a task is not as difficult as directly solving the task; 2) LMs are often capable of writing the correct compositions, but do not always natively do so. To show (1), we show that a 4B parameter RLM is perfectly capable of one-shotting a task commonly reported as a "long-context benchmark" in many frontier model reports. To show (2), we show that the original model struggles to perform the task as an RLM. However, after RL-training only on a smaller, simpler version of the benchmark (i.e. 32k context, 1 needle), the model bootstraps the correct decomposition behavior to solve the bigger task.
An exciting corollary of this hypothesis is that it implies that most of the necessary behavior that the model needs to learn during pre-training and mid-training is likely already there. Given a sufficiently well-designed scaffold that supports composition (e.g. RLMs), training out such a system through bootstrapping may be enough to draw out a general task solving system.
Language models have gotten to the point where they’re ridiculously powerful, and the bottlenecks to creating fancy things like long-horizon solvers or self-improving systems seem sort of silly (i.e. is length generalization really a concern). Should the MGH be true, the problem that remains is managing the geniuses (with guardrails, of course).
Acknowledgements. We thank Armando Solar-Lezama and Matthew Ho for helpful feedback.
]]>Language Models will be Scaffolds2026-02-25T00:00:00+00:002026-02-25T00:00:00+00:00https://alexzhang13.github.io/blog/2026/scaffoldAlex Zhang, Feb 25, 2026.
I have been somewhat convinced since before I started my PhD that the language models we interact with in the (near) future will be what we call scaffolds today. For the earlier half of this decade, it was generally believed that any work other than improving the base “neural” language model (i.e. an end-to-end neural network model like Opus 4.6 or Qwen3-8B) was a contrarian take on Sutton’s Bitter Lesson that would ultimately fall victim to scale. And this belief was genuinely a good bet since the invention of the Transformer in 2017: religiously following this bet is how companies like OpenAI and Anthropic have exploded in valuation since. The inability to follow this bet is also what has led to academia’s weakening presence in AI, and the growing pull of industry labs for ambitious, young researchers.
For the second half of this decade, my intuition tells me to bet differently. I’m not saying that scaling is dead; scaling is quite literally the key to everything in a data-driven strategy like deep learning. It’s more that language models are really good now: so good, that I theorize that existing neural language models are actually severely underutilized. I am implying that they are much better at general task solving than what we naively use them for. We’ve spent the better half of this decade exhausting every axis of scale we can find (e.g. data, compute, model capacity) in hopes that the neural language models we produce can edge out a few extra points on benchmarks built three years ago, but the obsession over “raw model capability” has ironically led to our evaluation metrics being completely off. How do you begin to evaluate between scaffolds like Claude Code, Codex, Cursor, and Antigravity with anything other than “vibes”? The lack of comparison is not because it doesn’t exist; it’s because we weren’t prepared for it.
Another consequence of the “language model purist” view is the conflation of the term “language model” to mean neural network. A language model, as we defined it pre-“Attention is All You Need”, is merely a probabilistic function from text to text. As an example, at the very end of 2025, I released a preprint called “Recursive Language Models”. A common point of confusion is in two-thirds of the title being “Language Model”, when the main proposal of the paper is about a task-agnostic scaffold. The argument presented in that paper is a formalized implementation of the theme of this essay, which is that a powerful class of language models with near-infinite input, output, and reasoning context are scaffolds around neural language models that can call themselves recursively inside of a REPL. To be blunt, what I am suggesting is that the line between a language model and a scaffold is blurring, and the field is once again open to novel ideas on what these scaffolds should look like.
As a researcher in AI, this should be very exciting. The field is generally resistant to “out-there” ideas, but the ability to produce novel, state-of-the-art systems without expensive training is at a peak. What’s even more exciting is that there isn’t “low-hanging fruit” per se (I strongly dislike this term because it implies you should pursue lazy incremental ideas), it’s more that we have once again hit a ripe period where innovative, clever ideas can make a huge impact on the direction of the field. Of course, I will continue to bet that training Recursive Language Models (RLMs) are the way to go to achieve near infinite-context LMs and produce a breakthrough in reasoning capabilities for models, but I also firmly believe that there are a plethora of other refinements or alternatives that may prove to be better. Only time will tell if GPT-9-super-high-genius-think ends up being a scaffold, but for now, I’m hopeful for the ideas to come.
]]>Recursive Language Models2025-10-15T00:00:00+00:002025-10-15T00:00:00+00:00https://alexzhang13.github.io/blog/2025/rlmThe full paper is now available here: https://arxiv.org/abs/2512.24601.
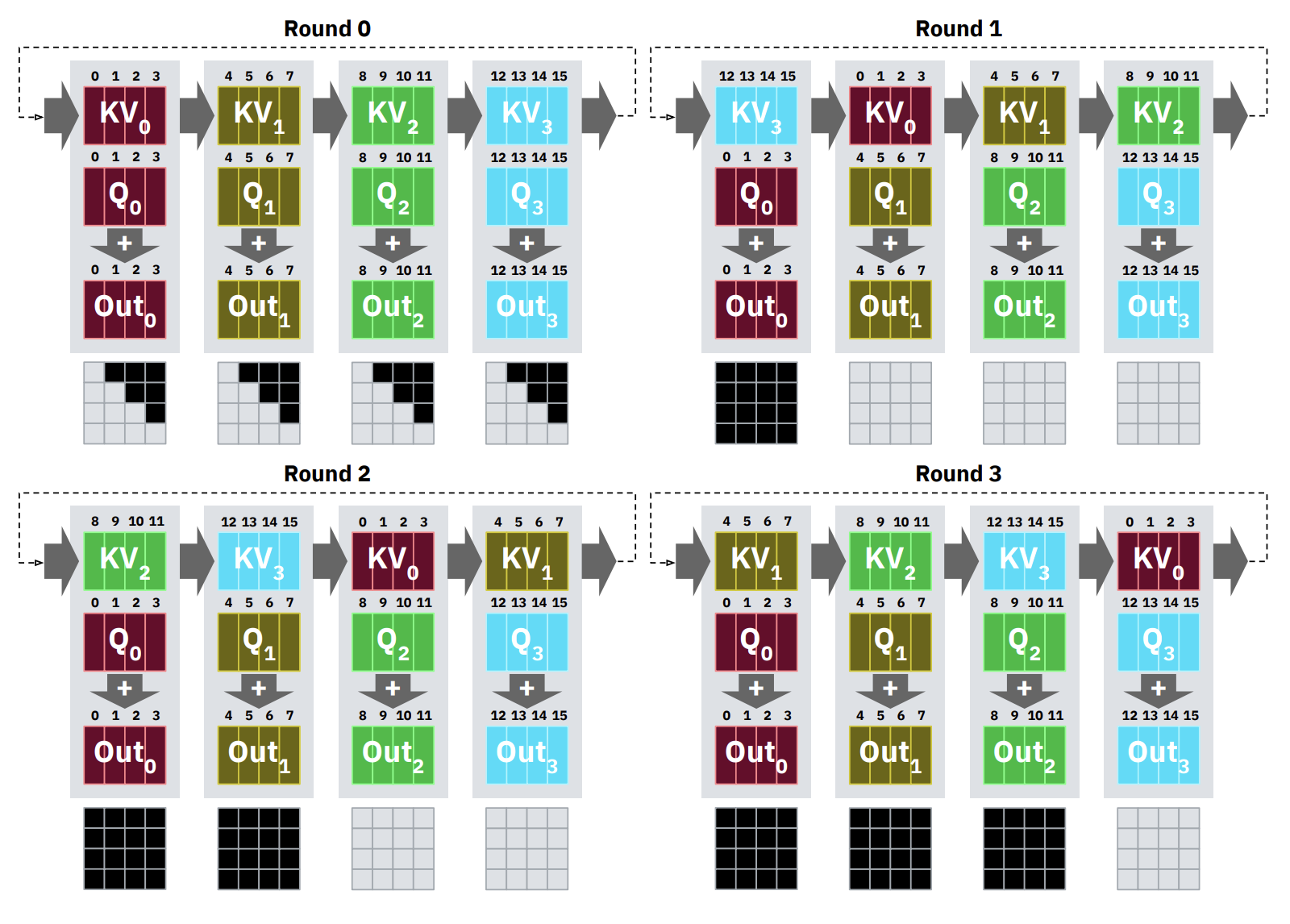
We explore language models that recursively call themselves or other LLMs before providing a final answer. Our goal is to enable the processing of essentially unbounded input context length and output length and to mitigate degradation “context rot”.
We propose Recursive Language Models, or RLMs, a general inference strategy where language models can decompose and recursively interact with their input context as a variable. We design a specific instantiation of this where GPT-5 or GPT-5-mini is queried in a Python REPL environment that stores the user’s prompt in a variable.
We demonstrate that an RLM using GPT-5-mini outperforms GPT-5 on a split of the most difficult long-context benchmark we got our hands on (OOLONG ) by more than double the number of correct answers, and is cheaper per query on average! We also construct a new long-context Deep Research task from BrowseComp-Plus . On it, we observe that RLMs outperform other methods like ReAct + test-time indexing and retrieval over the prompt. Surprisingly, we find that RLMs also do not degrade in performance when given 10M+ tokens at inference time.
We are excited to share these very early results, as well as argue that RLMs will be a powerful paradigm very soon. We think that RLMs trained explicitly to recursively reason are likely to represent the next milestone in general-purpose inference-time scaling after CoT-style reasoning models and ReAct-style agent models.
Figure 1. An example of a recursive language model (RLM) call, which acts as a mapping from text → text, but is more flexible than a standard language model call and can scale to near-infinite context lengths. An RLM allows a language model to interact with an environment (in this instance, a REPL environment) that stores the (potentially huge) context, where it can recursively sub-query “itself”, other LM calls, or other RLM calls, to efficiently parse this context and provide a final response.
Prelude: Why is “long-context” research so unsatisfactory?
There is this well-known but difficult to characterize phenomenon in language models (LMs) known as “context rot”. Anthropic defines context rot as “[when] the number of tokens in the context window increases, the model’s ability to accurately recall information from that context decreases”, but many researchers in the community know this definition doesn’t fully hit the mark. For example, if we look at popular needle-in-the-haystack benchmarks like RULER, most frontier models actually do extremely well (90%+ on 1-year old models).
I asked my LM to finish carving the pumpkin joke it started yesterday. It said, “Pumpkin? What pumpkin?” — the context completely rotted.
But people have noticed that context rot is this weird thing that happens when your Claude Code history gets bloated, or you chat with ChatGPT for a long time — it’s almost like, as the conversation goes on, the model gets…dumber? It’s sort of this well-known but hard to describe failure mode that we don’t talk about in our papers because we can’t benchmark it. The natural solution is something along the lines of, “well maybe if I split the context into two model calls, then combine them in a third model call, I’d avoid this degradation issue”. We take this intuition as the basis for a recursive language model.
Recursive Language Models (RLMs).
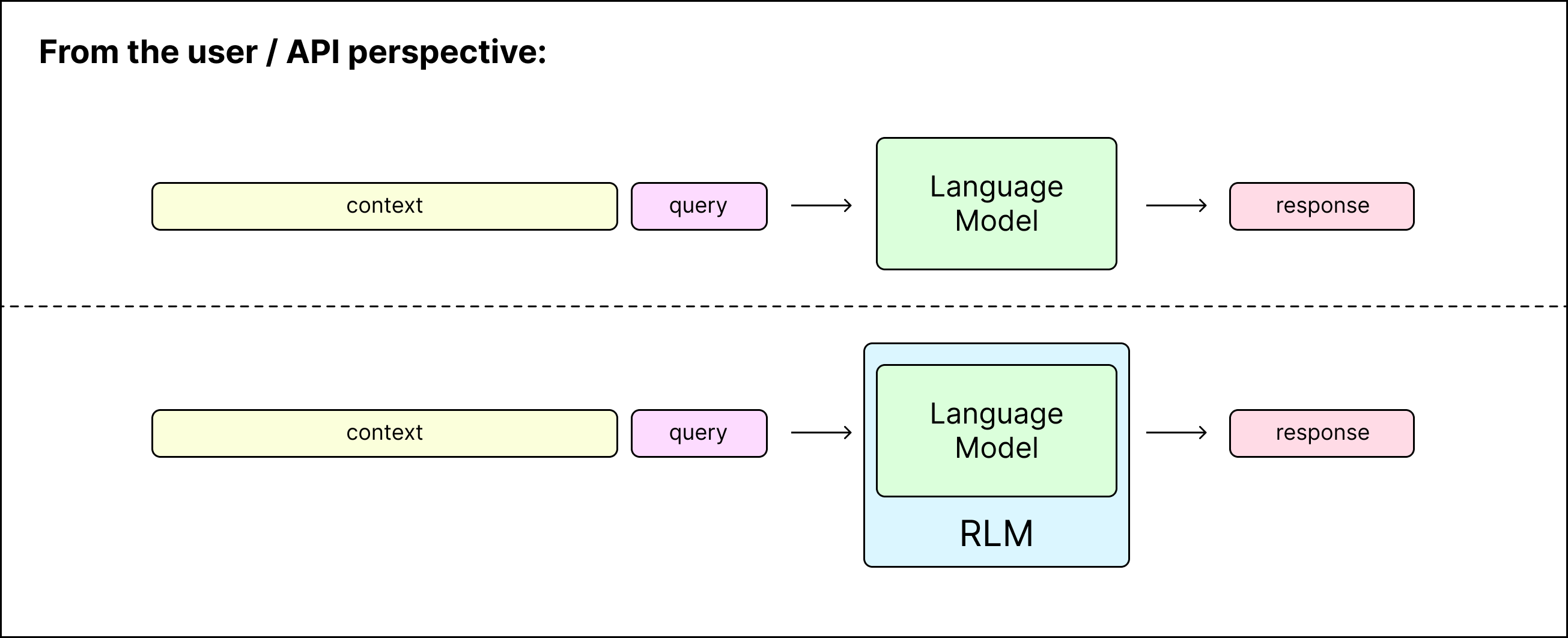
A recursive language model is a thin wrapper around a LM that can spawn (recursive) LM calls for intermediate computation — from the perspective of the user or programmer, it is the same as a model call. In other words, you query a RLM as an “API” like you would a LM, i.e. rlm.completion(messages) is a direct replacement for gpt5.completion(messages). We take a context-centric view rather than a problem-centric view of input decomposition. This framing retains the functional view that we want a system that can answer a particular query over some associated context:
Figure 2. A recursive language model call replaces a language model call. It provides the user the illusion of near infinite context, while under the hood a language model manages, partitions, and recursively calls itself or another LM over the context accordingly to avoid context rot.
Under the hood, a RLM provides only the query to the LM (which we call the root LM, or LM with depth=0), and allows this LM to interact with an environment, which stores the (potentially huge) context.
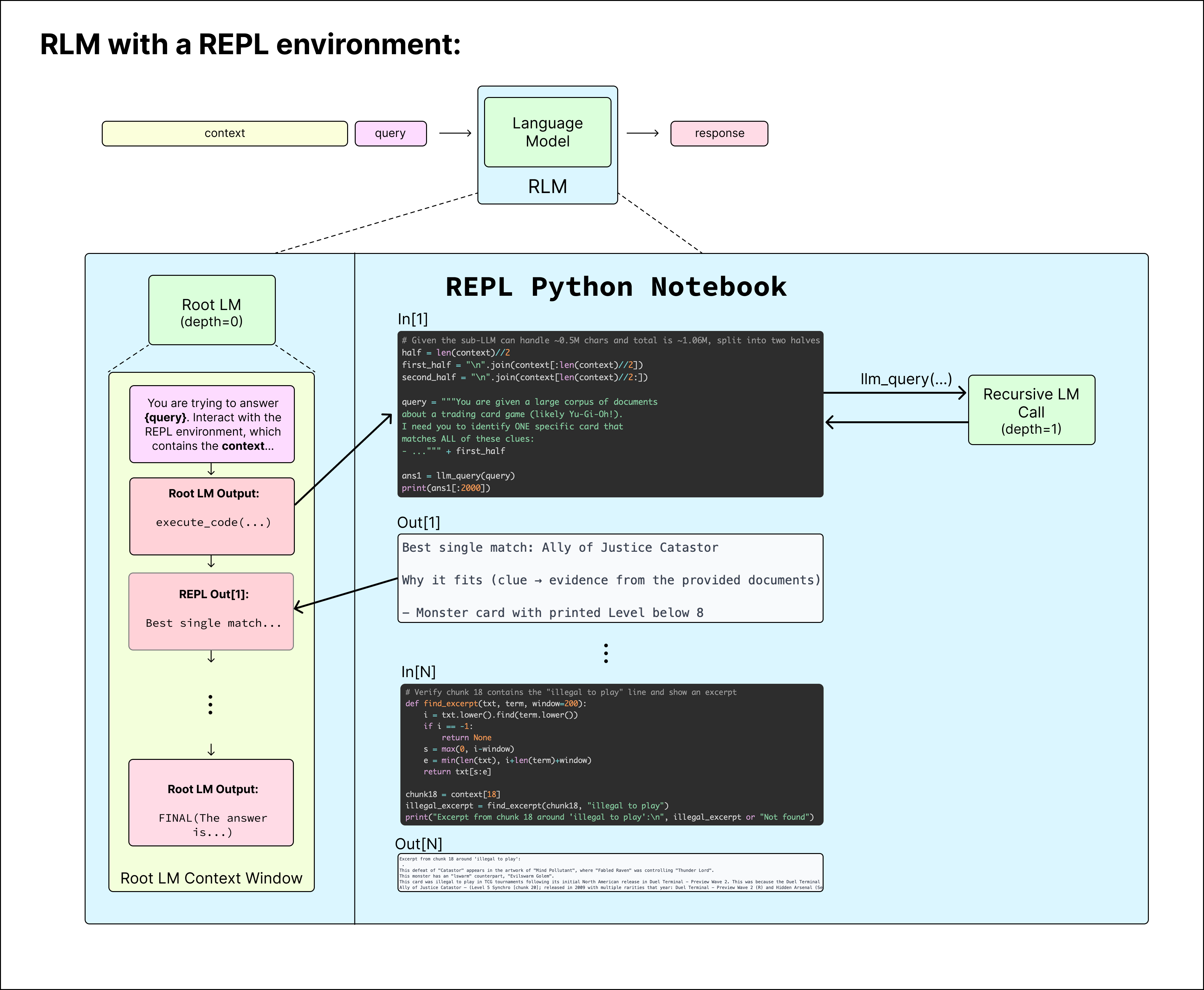
We choose the environment to be a loop where the LM can write to and read the output of cells of a Python REPL Notebook (similar to a Jupyter Notebook environment) that is pre-loaded with the context as a variable in memory. The root LM has the ability to call a recursive LM (or LM with depth=1) inside the REPL environment as if it were a function in code, allowing it to naturally peek at, partition, grep through, and launch recursive sub-queries over the context. Figure 3 shows an example of how the RLM with a REPL environment produces a final answer.
Figure 3. Our instantiation of the RLM framework provides the root LM the ability to analyze the context in a Python notebook environment, and launch recursive LM calls (depth=1) over any string stored in a variable. The LM interacts by outputting code blocks, and it receives a (truncated) version of the output in its context. When it is done, it outputs a final answer with `FINAL(…)` tags or it can choose to use a string in the code execution environment with `FINAL_VAR(…)`.
When the root LM is confident it has an answer, it can either directly output the answer as FINAL(answer), or it can build up an answer using the variables in its REPL environment, and return the string inside that answer as FINAL_VAR(final_ans_var).
This setup yields several benefits that are visible in practice:
The context window of the root LM is rarely clogged — because it never directly sees the entire context, its input context grows slowly.
The root LM has the flexibility to view subsets of the context, or naively recurse over chunks of it. For example, if the query is to find a needle-in-the-haystack fact or multi-hop fact, the root LM can use regex queries to roughly narrow the context, then launch recursive LM calls over this context. This is particularly useful for arbitrary long context inputs, where indexing a retriever is expensive on the fly!
The context can, in theory, be any modality that can be loaded into memory. The root LM has full control to view and transform this data, as well as ask sub-queries to a recursive LM.
Relationship to test-time inference scaling. We are particularly excited about this view of language models because it offers another axis of scaling test-time compute. The trajectory in which a language model chooses to interact with and recurse over its context is entirely learnable, and can be RL-ified in the same way that reasoning is currently trained for frontier models. Interestingly, it does not directly require training models that can handle huge context lengths because no single language model call should require handling a huge context.
RLMs with REPL environments are powerful. We highlight that the choice of the environment is flexible and not fixed to a REPL or code environment, but we argue that it is a good choice. The two key design choices of recursive language models are 1) treating the prompt as a Python variable, which can be processed programmatically in arbitrary REPL flows. This allows the LLM to figure out what to peek at from the long context, at test time, and to scale any decisions it wants to take (e.g., come up with its own scheme for chunking and recursion adaptively) and 2) allowing that REPL environment to make calls back to the LLM (or a smaller LLM), facilitated by the decomposition and versatility from choice (1).
We were excited by the design of CodeAct, and reasoned that adding recursive model calls to this system could result in significantly stronger capabilities — after all, LM function calls are incredibly powerful. However, we argue that RLMs fundamentally view LM usage and code execution differently than prior works: the context here is an object to be understood by the model, and code execution and recursive LM calls are a means of understanding this context efficiently. Lastly, in our experiments we only consider a recursive depth of 1 — i.e. the root LM can only call LMs, not other RLMs. It is a relatively easy change to allow the REPL environment to call RLMs instead of LMs, but we felt that for most modern “long context” benchmarks, a recursive depth of 1 was sufficient to handle most problems. However, for future work and investigation into RLMs, enabling larger recursive depth will naturally lead to stronger and more interesting systems.
The formal definition (click to expand)
Consider a general setup of a language model $M$ receiving a query $q$ with some associated, potentially long context $C = {[c_1,c_2,…,c_m]}$. The standard approach is to treat $M(q,C)$ like a black box function call, which takes a query and context and returns some `str` output. We retain this frame of view, but define a thin scaffold on top of the model to provide a more expressive and interpretable function call $RLM_M(q,C)$ with the same input and output spaces.
Formally, a recursive language model $RLM_{M}(q, C)$ over an environment $\mathcal{E}$ similarly receives a query $q$ and some associated, potentially long context $C = [c_1,c_2,…,c_m]$ and returns some `str` output. The primary difference is that we provide the model a tool call $RLM_M(\hat{q}, \hat{C})$, which spawns an isolated sub-RLM instance using a new query $\hat{q}$ and a transformed version of the context $\hat{C}$ with its own isolated environment $\hat{\mathcal{E}}$; eventually, the final output of this recursive callee is fed back into the environment of the original caller.
The environment $\mathcal{E}$ abstractly determines the control flow of how the language model $M$ is prompted, queried, and handled to provide a final output. In this paper, we specifically explore the use of a Python REPL environment that stores the input context $C$ as a variable in memory. This specific choice of environment enables the language model to peek at, partition, transform, and map over the input context and use recursive LMs to answer sub-queries about this context. Unlike prior agentic methods that rigidly define these workflow patterns, RLMs defer these decisions entirely to the language model. Finally, we note that particular choices of environments $\mathcal{E}$ are flexible and are a generalization of a base model call: the simplest possible environment $\mathcal{E}_0$ queries the model $M$ with input query and context $q, C$ and returns the model output as the final answer.
Some early (and very exciting) results!
We’ve been looking around for benchmarks that reflect natural long-context tasks, e.g. long multi-turn Claude Code sessions. We namely were looking to highlight two properties that limit modern frontier models: 1) the context rot phenomenon, where model performance degrades as a function of context length, and 2) the system-level limitations of handling an enormous context.
We found in practice that many long-context benchmarks offer contexts that are not really that long and which were already solvable by the latest generation (or two) of models. In fact, we found some where models could often answer queries without the context! We luckily quickly found two benchmarks where modern frontier LLMs struggle to perform well, but we are actively seeking any other good benchmark recommendations to try.
Exciting Result #1 — Dealing with Context Rot.
The OOLONG benchmark is a challenging new benchmark that evaluates long-context reasoning tasks over fine-grained information in context. We were fortunate to have the (anonymous but not affiliated with us) authors share the dataset upon request to run our experiments on a split of this benchmark.
Setup. The trec_coarse split consists of 6 different types of queries to answer distributional queries about a giant list of “question” entries. For example, one question looks like:
For the following question, only consider the subset of instances that are associated with user IDs 67144, 53321, 38876, 59219, 18145, 64957, 32617, 55177, 91019, 53985, 84171, 82372, 12053, 33813, 82982, 25063, 41219, 90374, 83707, 59594. Among instances associated with these users, how many data points should be classified as label 'entity'? Give your final answer in the form 'Answer: number'.
The query is followed by ~3000 - 6000 rows of entries with associated user IDs (not necessarily unique) and instances that are not explicitly labeled (i.e. the model has to infer the labeling to answer). They look something like this:
The score is computed as the number of queries answered correctly by the model, with the caveat that for numerical / counting problems, they use a continuous scoring metric. This benchmark is extremely hard for both frontier models and agents because they have to semantically map and associate thousands of pieces of information in a single query, and cannot compute things a-priori! We evaluate the following models / agents:
GPT-5. Given the whole context and query, tell GPT-5 to provide an answer.
GPT-5-mini. Given the whole context and query, tell GPT-5-mini to provide an answer.
RLM(GPT-5-mini). Given the whole context and query, tell RLM(GPT-5-mini) to provide an answer. GPT-5-mini (root LM) can recursively call GPT-5-mini inside its REPL environment.
RLM(GPT-5) without sub-calls. Given the whole context and query, tell RLM(GPT) to provide an answer. GPT-5 (root LM) cannot recursively call GPT-5 inside its REPL environment. This is an ablation for the use of a REPL environment without recursion.
ReAct w/ GPT-5 + BM25. We chunk every lines into its own “document”, and gives a ReAct loop access to a BM25 retriever to return 10 lines per search request.
Results. We focus explicitly on questions with contexts over 128k tokens (~100 queries), and we track both the performance on the benchmark, as well as the overall API cost of each query. In all of the following results (Figure 4a,b), the entire input fits in the context window of GPT-5 / GPT-5-mini — i.e., incorrect predictions are never due to truncation or context window size limitations:
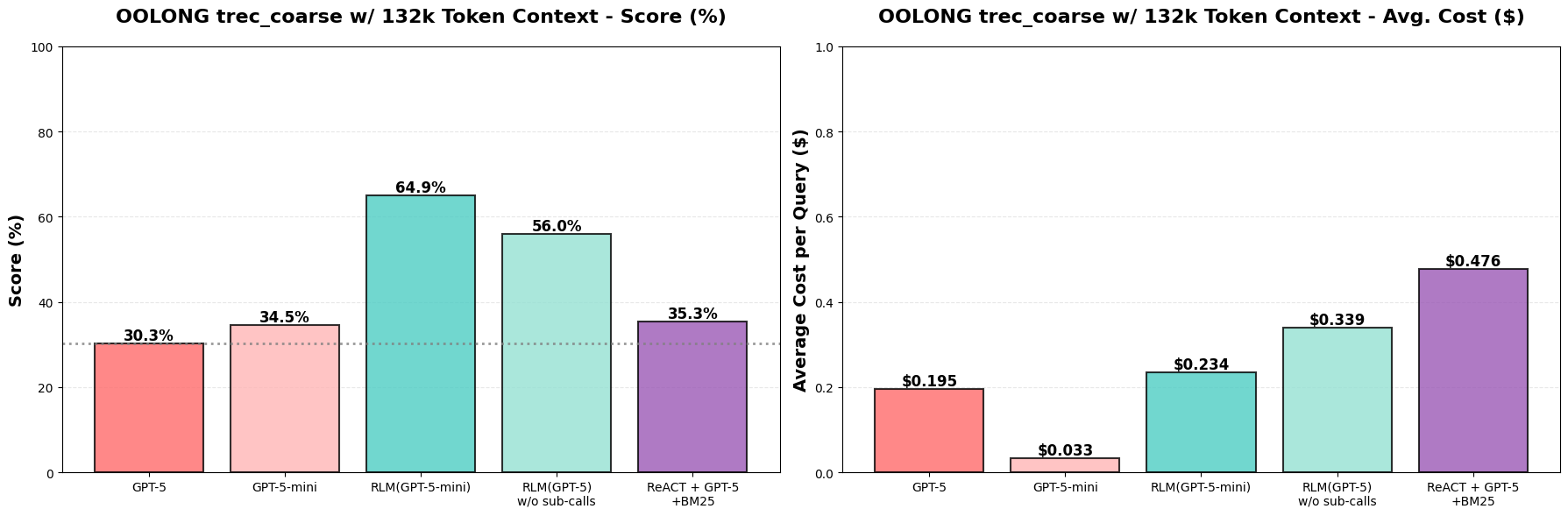
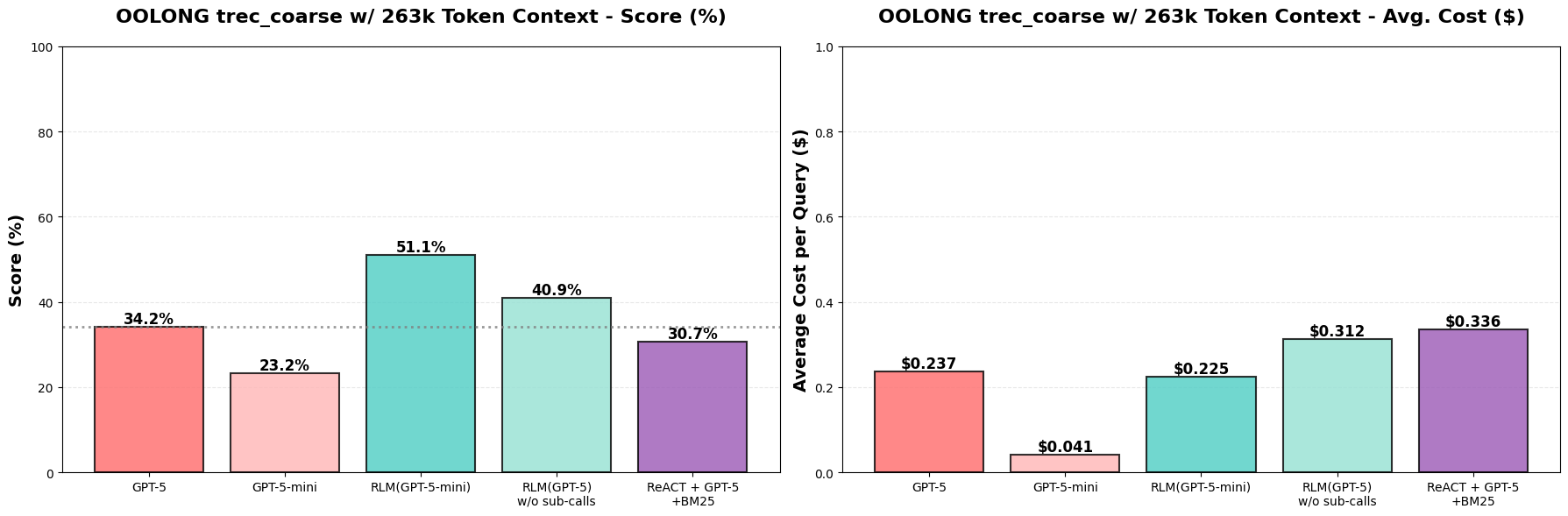
Figure 4a. We report the overall score for each method on the `trec_coarse` dataset of the OOLONG benchmark for queries that have a context length of 132k tokens. We compare performance to GPT-5. RLM(GPT-5-mini) outperforms GPT-5 by over 34 points (~114% increase), and is nearly as cheap per query (we found that the median query is cheaper due to some outlier, expensive queries).
It turns out actually that RLM(GPT-5-mini) outperforms GPT-5 and GPT-5-mini by >33%↑ raw score (over double the performance) while maintaining roughly the same total model API cost as GPT-5 per query! When ablating recursion, we find that RLM performance degrades by ~10%, likely due to many questions requiring the model to answer semantic questions about the data (e.g. label each question). We see in Figure 4b that these gains roughly transfer when we double the size of the context to ~263k tokens as well, although with some performance degradation!
Figure 4b. We report the overall score for each method on the trec_coarse dataset of the OOLONG benchmark for queries that have a context length of 263k tokens, nearly the limit for GPT-5/GPT-5-mini. We compare performance to GPT-5. RLM(GPT-5-mini) outperforms GPT-5 by over 15 points (~49% increase), and is cheaper per query on average.
Notably, the performance of GPT-5-mini drops while GPT-5 does not, which indicates that context rot is more severe for GPT-5-mini. We additionally noticed that the performance drop for the RLM approaches occurs for counting problems, where it makes more errors when the context length increases — for GPT-5, it already got most of these questions incorrect in the 132k context case, which explains why its performance is roughly preserved. Finally, while the ReAct + GPT-5 + BM25 baseline doesn’t make much sense in this setting, we provide it to show retrieval is difficult here while RLM is the more appropriate method.
Great! So we’re making huge progress in solving goal (1), where GPT-5 has just enough context window to fit the 263k case. But what about goal (2), where we may have 1M, 10M, or even 100M tokens in context? Can we still treat this like a single model call?
Exciting Result #2 — Ridiculously Large Contexts
My advisor Omar is a superstar in the world of information retrieval (IR), so naturally we also wanted to explore whether RLMs scale properly when given thousands (or more!) of documents. OOLONG provides a giant block of text that is difficult to index and therefore difficult to compare to retrieval methods, so we looked into DeepResearch-like benchmarks that evaluate answering queries over documents.
Retrieval over huge offline corpuses. We initially were interested in BrowseComp, which evaluates agents on multi-hop, web-search queries, where agents have to find the relevant documents online. We later found the BrowseComp-Plus benchmark, which pre-downloads all possible relevant documents for all queries in the original benchmark, and just provides a list of ~100K documents (~5k words on average) where the answer to a query is scattered across this list. For benchmarking RLMs, this benchmark is perfect to see if we can just throw ridiculously large amount of context into a single chat.completion(...) RLM call instead of building an agent!
Setup. We explore how scaling the # documents in context affects the performance of various common approaches to dealing with text corpuses, as well as RLMs. Queries on the BrowseComp-Plus benchmark are multi-hop in the sense that they require associating information across several different documents to answer the query. What this implies is that even if you retrieve the document with the correct answer, you won’t know it’s correct until you figure out the other associations. For example, query 984 on the benchmark is the following:
I am looking for a specific card in a trading card game. This card was released between the years 2005 and 2015 with more than one rarity present during the year it was released. This card has been used in a deck list that used by a Japanese player when they won the world championship for this trading card game. Lore wise, this card was used as an armor for a different card that was released later between the years 2013 and 2018. This card has also once been illegal to use at different events and is below the level 8. What is this card?
For our experiments, we explore the performance of each model / agent / RLM given access to a corpus of sampled documents of varying sizes — the only guarantee is that the answer can be found in this corpus. In practice, we found that GPT-5 can fit ~40 documents in context before it exceeds the input context window (272k tokens), which we factor into our choice of constants for our baselines. We explore the following models / agents, similar to the previous experiment:
GPT-5. Given all documents in context and the query, tell GPT-5 to provide an answer. If it goes over the context limit, return nothing.
GPT-5 (Truncated). Given all documents in context and the query, tell GPT-5 to provide an answer. If it goes over the context limit, truncate by most recent tokens (i.e. random docs).
GPT-5 + Pre-query BM25. First retrieve the top 40 documents using BM25 with the original query. Given these top-40 documents and the query, tell GPT-5 to provide an answer.
RLM(GPT-5). Given all documents in context and the query, tell RLM(GPT-5) to provide an answer. GPT-5 (root LM) can “recursively” call GPT-5-mini inside its REPL environment.
RLM(GPT-5) without sub-calls. Given the whole context and query, tell RLM(GPT-5) to provide an answer. GPT-5 (root LM) cannot recursively call GPT-5 inside its REPL environment. This is an ablation for the use of a REPL environment without recursion.
ReAct w/ GPT-5 + BM25. Given all documents, query for an answer from a ReAct loop using GPT-5 with access to a BM25 retriever that can return 5 documents per request.
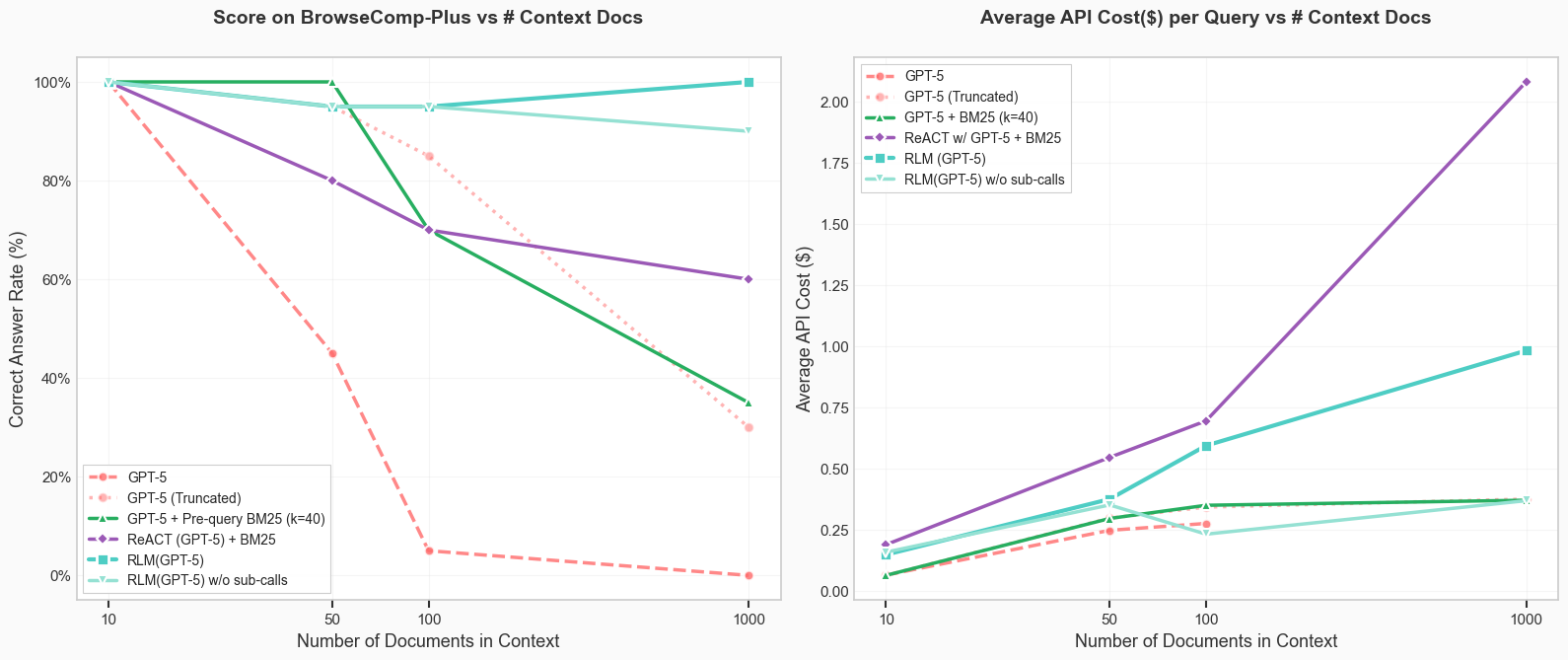
Results. We want to emphasize that these preliminary results are not over the entire BrowseComp-Plus dataset, and only a small subset. We report the performance over 20 randomly sampled queries on BrowseComp-Plus when given 10, 50, 100, and 1000 documents in context in Figure 5. We always include the gold / evidence document documents in the corpus, as well as the hard-mined negatives if available.
Figure 5. We plot the performance and API cost per answer of various methods on 20 random queries in BrowseComp-Plus given increasing numbers of documents in context. Only the iterative methods (RLM, ReAct) maintain reasonable performance at 100+ documents.
There are a few things to observe here — notably, RLM(GPT-5) is the only model / agent able to achieve and maintain perfect performance at the 1000 document scale, with the ablation (no recursion) able to similarly achieve 90%. The base GPT-5 model approaches, regardless of how they are conditioned, show clear signs of performance dropoff as the number of documents increase. Unlike OOLONG , all approaches are able to solve the task when given a sufficiently small context window (10 documents), making this a problem of finding the right information rather than handling complicated queries. Furthermore, the cost per query of RLM(GPT-5) scales reasonably as a function of the context length!
These experiments are particularly exciting because without any extra fine-tuning or model architecture changes, we can reasonably handle huge corpuses (10M+ tokens) of context on realistic benchmarks without the use of a retriever. It should be noted that the baselines here index BM-25 per query, which is a more powerful condition than indexing the full 100K document corpus and applying BM-25. Regardless, RLMs are able to outperform the iterative ReAct + GPT-5 + BM25 loop on a retrieval style task with a reasonable cost!
Amazing! So RLMs are a neat solution to handle our two goals, and offer natural way to extend the effective context window of a LM call without incurring large costs. The rest of this blog will be dedicated to some cool and interesting behavior that RLMs exhibit!
What is the RLM doing? Some Interesting Cases…
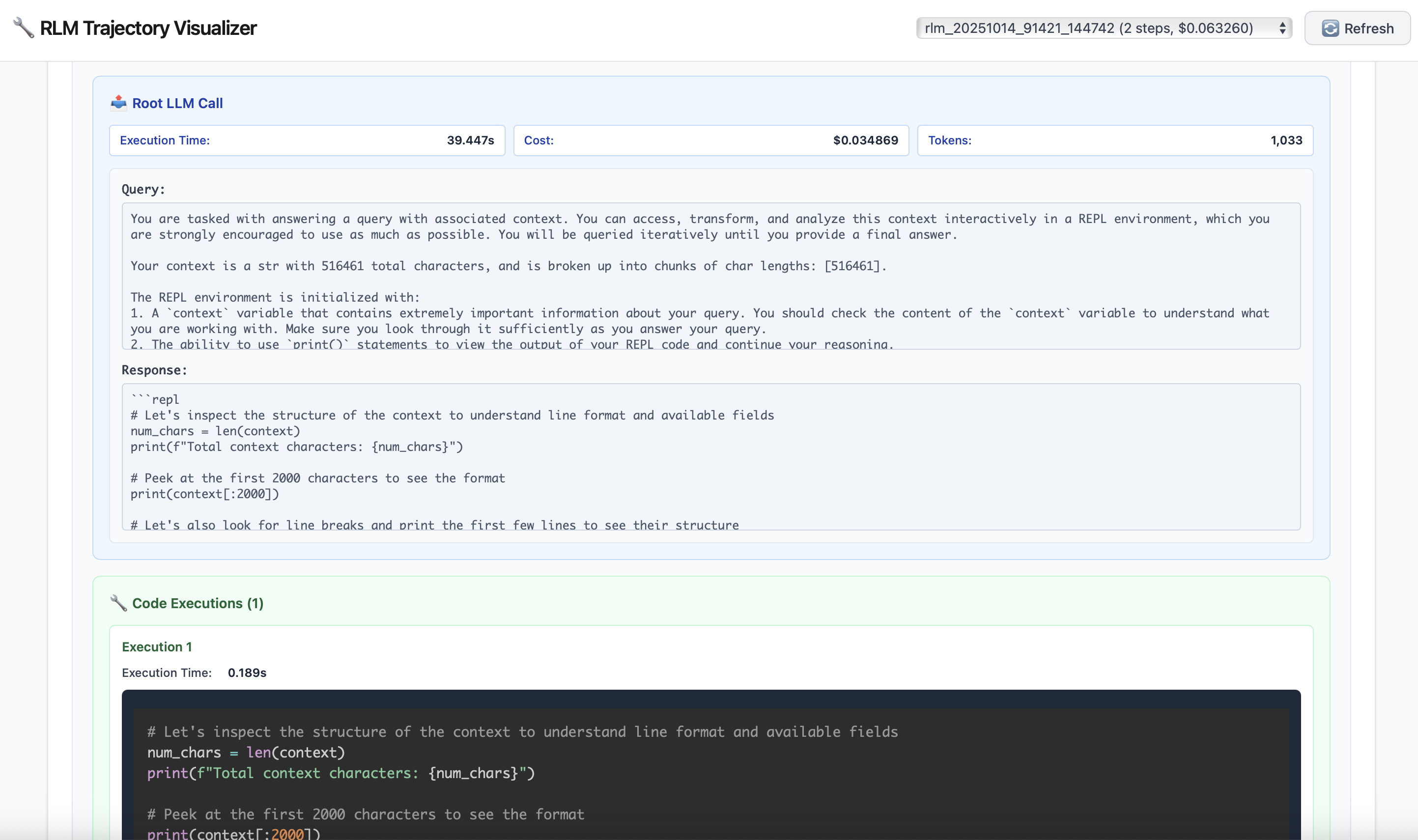
A strong benefit of the RLM framework is the ability to roughly interpret what it is doing and how it comes to its final answer. We vibe-coded a simple visualizer to peer into the trajectory of an RLM, giving us several interesting examples to share about what the RLM is doing!
Strategies that have emerged that the RLM will attempt. At the level of the RLM layer, we can completely interpret how the LM chooses to interact with the context. Note that in every case, the root LM starts only with the query and an indication that the context exists in a variable in a REPL environment that it can interact with.
Peeking. At the start of the RLM loop, the root LM does not see the context at all — it only knows its size. Similar to how a programmer will peek at a few entries when analyzing a dataset, the LM can peek at its context to observe any structure. In the example below on OOLONG, the outer LM grabs the first 2000 characters of the context.
Grepping. To reduce the search space of its context, rather than using semantic retrieval tools, the RLM with REPL can look for keywords or regex patterns to narrow down lines of interest. In the example below, the RLM looks for lines with questions and IDs.
Partition + Map. There are many cases where the model cannot directly grep or retrieve information due to some semantic equivalence of what it is looking for. A common pattern the RLM will perform is to chunk up the context into smaller sizes, and run several recursive LM calls to extract an answer or perform this semantic mapping. In the example below on OOLONG, the root LM asks the recursive LMs to label each question and use these labels to answer the original query.
Summarization. RLMs are a natural generalization of summarization-based strategies commonly used for managing the context window of LMs. RLMs commonly summarize information over subsets of the context for the outer LM to make decisions.
Long-input, long-output. A particularly interesting and expensive case where LMs fail is in tasks that require long output generations. For example, you might give ChatGPT your list of papers and ask it to generate the BibTeX for all of them. Similar to huge multiplication problems, some people may argue that a model should not be expected to solve these programmatic tasks flawlessly — in these instances, RLMs with REPL environments should one-shot these tasks! An example is the LoCoDiff benchmark, where language models are tasked with tracking a long git diff history from start to finish, and outputting the result of this history given the initial file. For histories longer than 75k tokens, GPT-5 can’t even solve 10% of the histories! An example of what the model is given (as provided on the project website) is as follows:
> git log -p \
--cc \
--reverse \
--topo-order \
-- shopping_list.txt
commit 008db723cd371b87c8b1e3df08cec4b4672e581b
Author: Example User
Date: Wed May 7 21:12:52 2025 +0000
Initial shopping list
diff --git a/shopping_list.txt b/shopping_list.txt
new file mode 100644
index 0000000..868d98c
--- /dev/null
+++ b/shopping_list.txt
@@ -0,0 +1,6 @@
+# shopping_list.txt
+apples
+milk
+bread
+eggs
+coffee
commit b6d826ab1b332fe4ca1dc8f67a00f220a8469e48
Author: Example User
Date: Wed May 7 21:12:52 2025 +0000
Change apples to oranges and add cheese
diff --git a/shopping_list.txt b/shopping_list.txt
index 868d98c..7c335bb 100644
--- a/shopping_list.txt
+++ b/shopping_list.txt
@@ -1,6 +1,7 @@
# shopping_list.txt
-apples
+oranges
milk
bread
eggs
coffee
+cheese
...
We tried RLM(GPT-5) to probe what would happen, and found in some instances that it chooses to one-shot the task by programmatically processing the sequence of diffs! There are many benchmark-able abilities of LMs to perform programmatic tasks (e.g. huge multiplication, diff tracking, etc.), but RLMs offer a framework for avoiding the need for such abilities altogether.
More patterns…? We anticipate that a lot more patterns will emerge over time when 1) models get better and 2) models are trained / fine-tuned to work this way. An underexplored area of this work is how efficient a language model can get with how it chooses to interact with the REPL environment, and we believe all of these objectives (e.g. speed, efficiency, performance, etc.) can be optimized as scalar rewards.
Limitations.
We did not optimize our implementation of RLMs for speed, meaning each recursive LM call is both blocking and does not take advantage of any kind of prefix caching! Depending on the partition strategy employed by the RLM’s root LM, the lack of asynchrony can cause each query to range from a few seconds to several minutes. Furthermore, while we can control the length / “thinking time” of an RLM by increasing the maximum number of iterations, we do not currently have strong guarantees about controlling either the total API cost or the total runtime of each call. For those in the systems community (cough cough, especially the GPU MODE community), this is amazing news! There’s so much low hanging fruit to optimize here, and getting RLMs to work at scale requires re-thinking our design of inference engines.
Related Works
Scaffolds for long input context management. RLMs defer the choice of context management to the LM / REPL environment, but most prior works do not. MemGPT similarly defers the choice to the model, but builds on a single context that an LM will eventually call to return a response. MemWalker imposes a tree-like structure to order how a LM summarizes context. LADDER breaks down context from the perspective of problem decomposition, which does not generalize to huge contexts.
Other (pretty different) recursive proposals. There’s plenty of work that invokes forking threads or doing recursion in the context of deep learning, but none have the structure required for general-purpose decomposition. THREAD modifies the output generation process of a model call to spawn child threads that write to the output. Tiny Recursive Model (TRM) is a cool idea for iteratively improving the answer of a (not necessarily language) model in its latents. Recursive LLM Prompts was an early experiment on treating the prompt as a state that evolves when you query a model. Recursive Self-Aggregation (RSA) is a recent work that combines test-time inference sampling methods over a set of candidate responses.
What We’re Thinking Now & for the Future.
Long-context capabilities in language models used to be a model architecture problem (think ALiBi, YaRN, etc.). Then the community claimed it was a systems problem because “attention is quadratic”, but it turned out actually that our MoE layers were the bottleneck. It now has become somewhat of a combination of the two, mixed with the fact that longer and longer contexts do not fall well within the training distributions of our LMs.
Do we have to solve context rot? There are several reasonable explanations for “context rot”; to me, the most plausible is that longer sequences are out of distribution for model training distributions due to lack of natural occurrence and higher entropy of long sequences. The goal of RLMs has been to propose a framework for issuing LM calls without ever needing to directly solve this problem — while the idea was initially just a framework, we were very surprised with the strong results on modern LMs, and are optimistic that they will continue to scale well.
RLMs are not agents, nor are they just summarization. The idea of multiple LM calls in a single system is not new — in a broad sense, this is what most agentic scaffolds do. The closest idea we’ve seen in the wild is the ROMA agent that decomposes a problem and runs multiple sub-agents to solve each problem. Another common example is code assistants like Cursor and Claude Code that either summarize or prune context histories as they get longer and longer. These approaches generally view multiple LM calls as decomposition from the perspective of a task or problem. We retain the view that LM calls can be decomposed by the context, and the choice of decomposition should purely be the choice of an LM.
The value of a fixed format for scaling laws. We’ve learned as a field from ideas like CoT, ReAct, instruction-tuning, reasoning models, etc. that presenting data to a model in predictable or fixed formats are important for improving performance. The basic idea is that we can reduce the structure of our training data to formats that model expects, we can greatly increase the performance of models with a reasonable amount of data. We are excited to see how we can apply these ideas to improve the performance of RLMs as another axis of scale.
RLMs improve as LMs improve. Finally, the performance, speed, and cost of RLM calls correlate directly with improvements to base model capabilities. If tomorrow, the best frontier LM can reasonably handle 10M tokens of context, then an RLM can reasonably handle 100M tokens of context (maybe at half the cost too).
As a lasting word, RLMs are a fundamentally different bet than modern agents. Agents are designed based on human / expert intuition on how to break down a problem to be digestible for an LM. RLMs are designed based on the principle that fundamentally, LMs should decide how to break down a problem to be digestible for an LM. I personally have no idea what will work in the end, but I’m excited to see where this idea goes!
--az
Acknowledgements
We thank our wonderful MIT OASYS labmates Noah Ziems, Jacob Li, and Diane Tchuindjo for all the long discussions about where steering this project and getting unstuck. We thank Prof. Tim Kraska, James Moore, Jason Mohoney, Amadou Ngom, and Ziniu Wu from the MIT DSG group for their discussion and help in framing this method for long context problems. This research was partly supported by Laude Institute.
We also thank the authors (who shall remain anonymous) of the OOLONG benchmark for allowing us to experiment on their long-context benchmark. They went from telling us about the benchmark on Monday 10:30am to sharing it with us by 1pm, and two days ago, we’re able to tell you about these cool results thanks to them.
Finally, we thank Jack Cook and the other first year MIT EECS students for their support during the first year of my PhD!
Citation
You can cite this blog (before the full paper is released) here:
@article{zhang2025rlm,
title = "Recursive Language Models",
author = "Zhang, Alex and Khattab, Omar",
year = "2025",
month = "October",
url = "https://alexzhang13.github.io/blog/2025/rlm/"
}
]]>Alex ZhangA Meticulous Guide to Advances in Deep Learning Efficiency over the Years2024-10-30T00:00:00+00:002024-10-30T00:00:00+00:00https://alexzhang13.github.io/blog/2024/efficient-dlThis post offers a comprehensive and chronological guide to advances in deep learning from the perspective of efficiency: things like clusters, individual hardware, deep learning libraries, compilers — even architectural changes. This post is not a survey paper, and is intended to provide the reader with broader intuition about this field — it would be impossible to include every little detail that has emerged throughout the last 40 years. The posted X thread https://x.com/a1zhang/status/1851963904491950132 also has a very high-level summary of what to expect!
Preface. The field of deep learning has flourished in the past decade to the point where it is hard as both a researcher and a student to keep track of what is going on. Sometimes, I even find it hard to keep track of the actual direction of the field. In a field that often feels hand-wavy and where many methods and results feel lackluster in practice, I wanted to at least get a sense for progress in how we got to where we are now.
I wanted to write this post in a narrative form — to 1) be digestible to the reader rather than an information dump, and 2) allow the reader to view the field from a macroscopic lens and understand why the field moved the way it did. I have tried to be as paper-focused as possible (similar to Lilian Weng style blogs!) and include as many landmark (or just cool) works as I saw fit; if the reader feels something should be included or edited, please let me knowI really hope all of the information is correct and I’ve tried to make sure of it as much as possible, but it is possible I’ve made errors! If you find any, feel free to shoot me an email and let me know! I’m quite a young person, so I was probably playing Minecraft hypixel when some of these breakthroughs happened. Finally, I always recommend reading the original paper when you want to understand something in more depth. There’s no way for me to fit all of the information about every work here (especially the math), so if you’re ever confused and care enough to know the details, I’ve included both citations and a direct link to every mentioned work.! Before we begin, let me just list out some relevant numbers to give us a bit of appreciation for all of the advances to come. I’ve also added some notes for folks who aren’t familiar with what these numbers really mean.
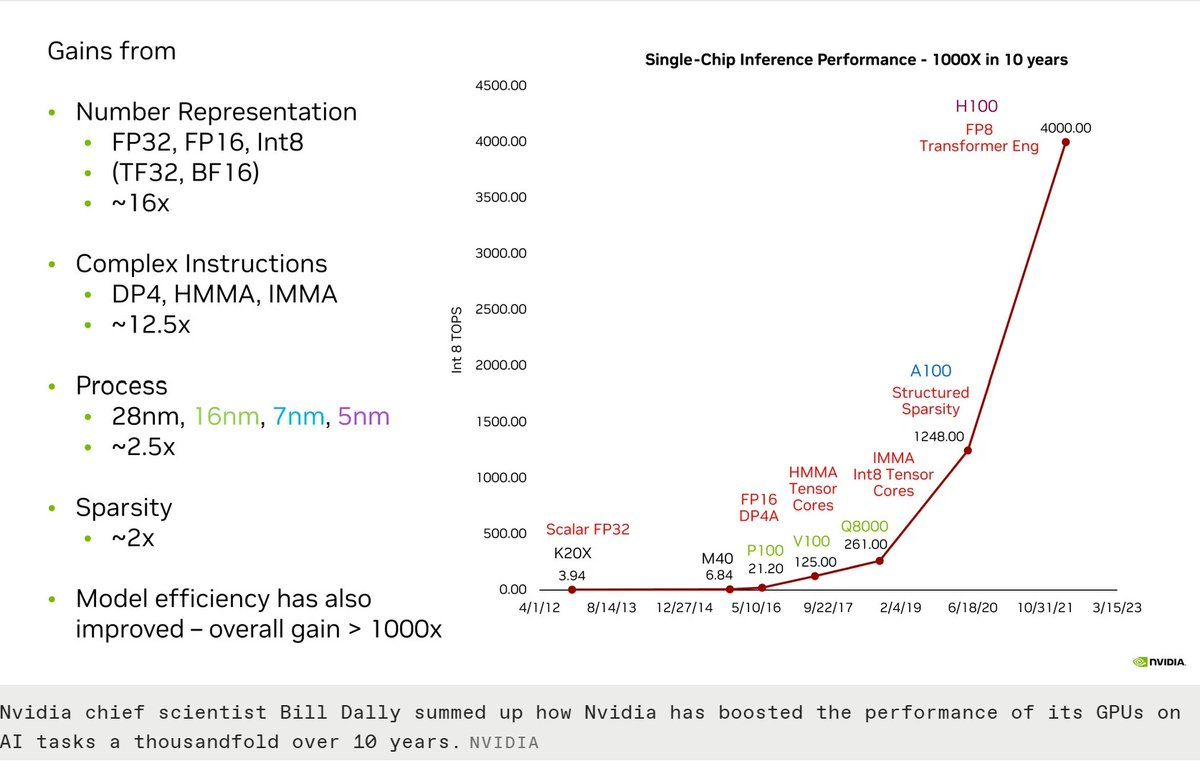
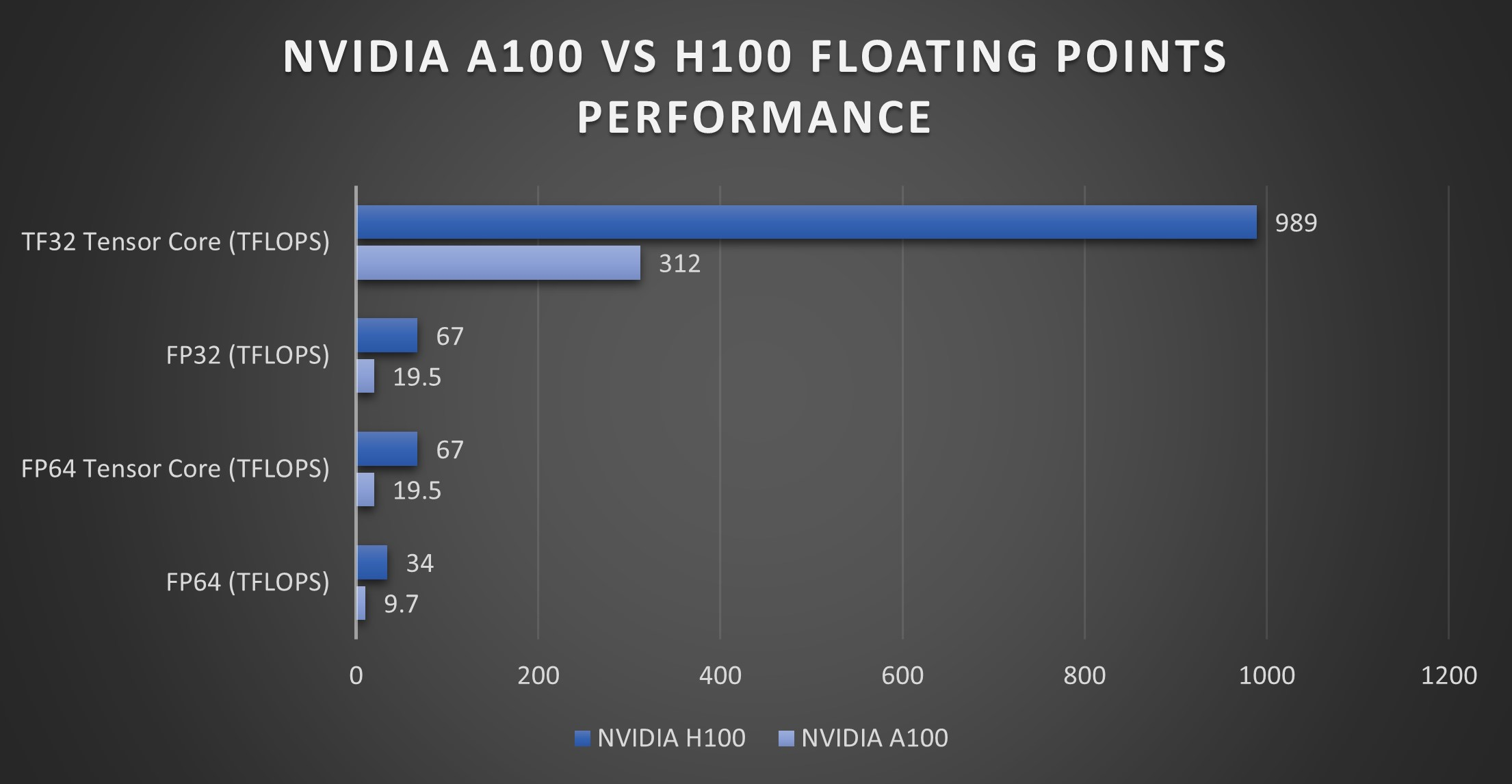
For FP8Recent NVIDIA hardware includes specialized “tensor cores” that can compute matrix multiplication on 8-bit floating point numbers really fast., it can achieve up to ~4500 TeraFLOPSFLOPS means floating-point operations per second, which is a metric for roughly how fast a processor or algorithm is because most operations in deep learning are over floating point numbers., which is absolutely insane!
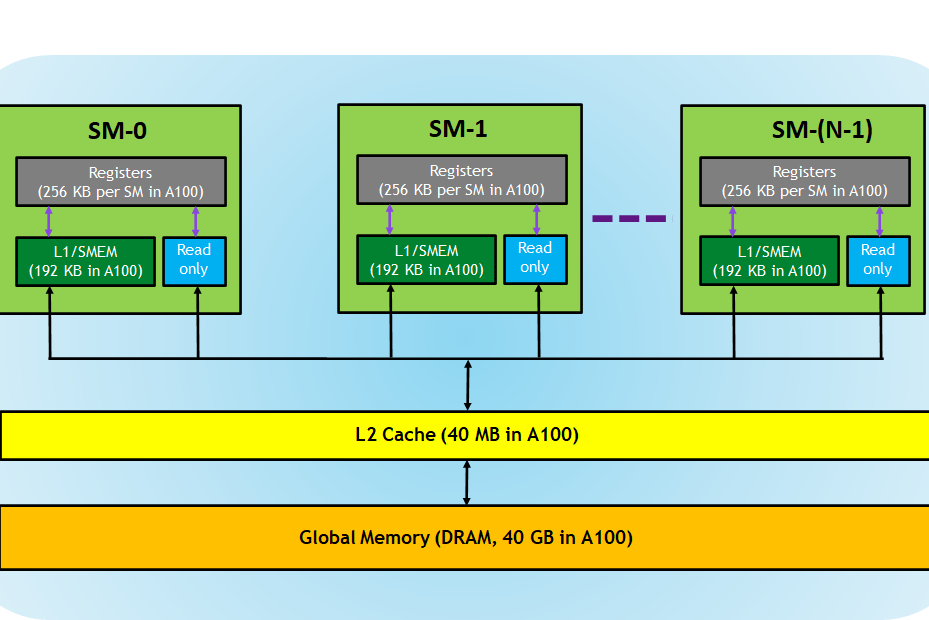
It features 192GB of high-bandwidth memory / DRAM, which is the main GPU memory.
Llama 3.1 405B, Meta’s latest open-source language model is 405B parameters (~800GB).
It was trained on a whopping 16k NVIDIA H100s (sitting on their 24k GPU cluster)
It’s training dataset was 15 trillion tokens.
Part I. The Beginning (1980s-2011)
The true beginning of deep learning is hotly contested, but I, somewhat arbitrarily, thought it was best to begin with the first usage of backpropagation for deep learning: Yann Lecun’s CNN on a handwritten digits dataset in 1989.
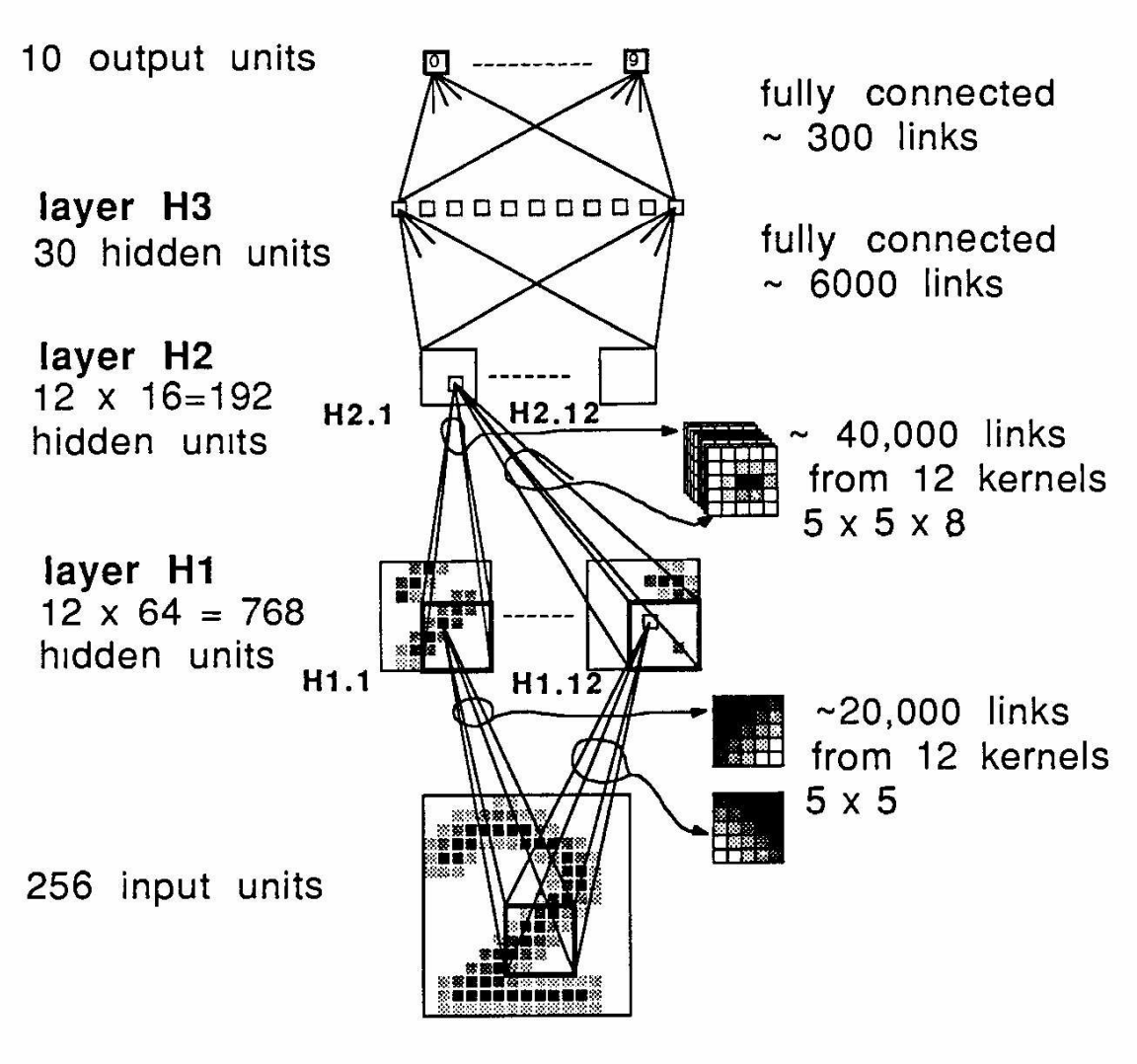
Figure 1. Lecun’s original network (1989) for learning to classify digits. It is a simple convolutional network written in Lisp running on a backpropagation simulator.
Backpropagation Applied to Handwritten Zip Code Recognition (Lecun, 1989).
It is remarkable how simple this setup is: given a training dataset of 7291 normalized 16x16 images of handwritten digits, they train a 2-layer convolutional network with 12 5x5 learnable kernels, followed by a final projection to 10 logits. They train for 23 epochs (~3 days), and approximate the Hessian in Newton’s method to perform weight updates. Without an autodifferentiation engine, they had to write their own backpropagation simulator to compute the relevant derivatives. Finally, these experiments were run on a SUN-4/260 work station, which is a single-core machine running at 16.67 MHz and 128MB of RAM.For reference, a Macbook nowadays will have ~2-3 GHz and 16GB of RAM!
Andrej Karpathy has a wonderful blog that attempts to reproduce this paper on modern deep learning libraries with some extra numbers for reference:
The original model contains roughly 9760 learnable parameters, 64K MACsMAC stands for multiplication-accumulate, which is a common metric for GPUs because they have fused multiply-and-adder instructions for common linear algebra operations, and 1K activations in one forward pass.
On his Macbook M1 CPU, he trains a roughly equivalent setup in 90 seconds — it goes to show how far the field has progressed!
Some other notable works at the time were the Long Short-Term Memory (1997), Deep Belief Networks (2006), and Restricted Boltsmann Machines (2007), but I couldn’t really find the hardware, software library, or even programming language used to develop these methods (most likely Lisp / CUDA C++). Furthermore, these methods were more concerned with training stability (e.g. vanishing gradient problem) and proving that these methods could converge on non-trivial tasks, so I can only assume “scale” was not really a concern here.
I.1. Existing Fast Linear Algebra Methods
The introduction of the graphics processors in the late 20th century did not immediately accelerate progress in the deep learning community. While we know GPUs and other parallel processors as the primary workhorse of modern deep learning applications, they were originally designed for efficiently rendering polygons and textures in 3D games — for example, if you look at the design of the NVIDIA GeForce 256 (1999), you’ll notice a distinct lack of modern components like shared memoryNot to be confused with shared memory in the OS setting, I think this naming convention is bad. Shared memory on an NVIDIA GPU is a low-latency cache / SRAM that can be accessed among threads in a threadblock. It is typically used to quickly communicate between threads. and tensor cores that are critical for modern deep learning workloads.
Programming a GPU in the 2000s. By this point the CUDA ecosystem had not matured, so the common method for hacking GPUs for general purpose applications was to configure DirectX or OpenGL, the popular graphics APIs at the time, to perform some rendering operation that involved say a matrix multiplication.To corroborate the anecdote above, I had heard that this was true in a talk at Princeton given by Turing award winner Patrick Hanrahan.
Figure 2. A list of the different BLAS primitives. [Image Source]
Linear Algebra on a CPU. During this time, a suite of libraries had emerged in parallel for computing and solving common linear algebra paradigms like matrix multiplication, vector addition, dot products, etc. Many of these libraries used or were built off of the BLAS (Basic Linear Algebra Subprograms) specification with bindings for C and Fortran. BLAS divides its routines into three levels, mainly based on their runtime complexity (e.g. level 2 contains matrix-vector operations, which are quadratic with respect to the dimension). On CPUs, these libraries take advantage of SIMD / vectorizationModern CPUs allow for processing multiple elements with a single instruction, enabling a form of parallelization. Hardware components like vector registers (see https://cvw.cac.cornell.edu/vector/hardware/registers) also enable this behavior., smart caching, and multi-threading to maximize throughput. It is also pretty well known that MATLAB, NumPy, and SciPy were popular language / libraries used for these tasks, which essentially used BLAS primitives under the hood. Below were some commonly used libraries:
LAPACK (1992): The Linear Algebra Package provides implementations of common linear algebra solvers like eigendecomposition and linear least squares.
Intel MKL (1994): The Intel Math Kernel Library is a closed-source library for performing BLAS (now other) operations on x86 CPUs.
OpenBLAS (2011): An open-source version of Intel MKL with similar, but worse, performance on most Intel instruction-set architectures (ISAs).
OpenCL (2009): An alternative to hacking in OpenGL, OpenCL was a device-agnostic library for performing computations in multiple processors. It was far more flexible for implementing primitives like matrix multiplication.
Just for some reference numbers, I just ran a simple matrix multiplication experiment on my Macbook M2 Pro (12-core CPU, 3.5 GHz) with NumPy 1.26.4, which currently uses OpenBLAS under the hood. I found this blogpost by Aman Salykov which does more extensive experimenting as well.
I really like this post by Fabien Sanglard, which explains the history and motivating design patterns of CUDA and NVIDIA GPUs starting from the Tesla architecture over the years.
Figure 3. The CUDA ecosystem from device drivers to specific frameworks has been one of the major reasons behind NVIDIA's success in deep learning. [Image Source]
CUDA was originally designed to enable parallel programmers to work with GPUs without having to deal with graphics APIs. The release of CUDA also came with the release of the NVIDIA Tesla microarchitecture, featuring streaming multiprocessors (SMs), which is the standard abstraction for “GPU cores” used today (this is super important for later!). I’m not an expert in GPU hardware design (actually I’m not an expert in anything for that matter), but the basic idea is that instead of having a lot of complicated hardware units performing specific vectorized tasks, we can divide up computation into general purpose cores (the SMs) that are instead SIMT (single-instruction multiple threads). While this design change was meant for graphics programmers, it eventually made NVIDIA GPUs more flexible for generic scientific workloads.
Nowadays, CUDA has evolved beyond just a C API to include several NVIDIA-supported libraries for various workloads. Many recent changes target maximizing tensor core usage, which are specialized cores for fast generalized matrix multiplication (GEMM) in a single cycle. If what I’m saying makes no sense, don’t worry — I will talk more extensively about tensor cores and roughly how CUDA is used with NVIDIA GPUs in the next section.
Some notable libraries that I’ve used in practice are:
cuBLAS (Introduced in CUDA 8.0): The CUDA API for BLAS primitives.
cuDNN: The CUDA API for standard deep learning operations (e.g. softmax, activation functions, convolutions, etc.).
CUTLASS (Introduced in CUDA 9.0): A template abstraction (CuTe layouts) for implementing GEMM for your own kernels — doesn’t have the large overhead of CuBLAS/CuDNN, which supports a wide variety of operations.
Part II: Oh s***— Deep learning works! (2012-2020)
Although this section roughly covers the 2010s, many modern methods were derived from works during this time, so you may find some newer techniques mentioned in this section because it felt more natural.
While classical techniques in machine learning and statistics (e.g. SVM, boosting, tree-based methods, kernel-based methods) had been showing promise in a variety of fields such as data science, a lot of people initially did not believe in deep learning. There were definitely people working in the field by the early 2010s, but the pre-dominant experiments were considered more “proof-of-concept”. At the time, classical techniques in fields like computer vision (e.g. SIFT features, edge detectors) and machine translation were thought to be considerably better than any deep-learning methods. That is, until 2012, when team SuperVision dominated every other carefully crafted computer vision technique by an absurd margin.
Part II.1: The first breakthrough on images!
Figure 4. Examples of images and annotations from ImageNet. [Image Source]
ImageNet, 2009. In 2009, the ImageNet dataset (shout-out to Prof. Kai Li, the co-PI, who is now my advisor at Princeton) was released as “the” canonical visual object recognition benchmark. The dataset itself included over 14 million annotated images with >20k unique classes, and represented the largest annotated image dataset to date. The following is a snippet of 2012 leaderboard for top-5 image classification, where the model is allowed 5 guesses for each image.
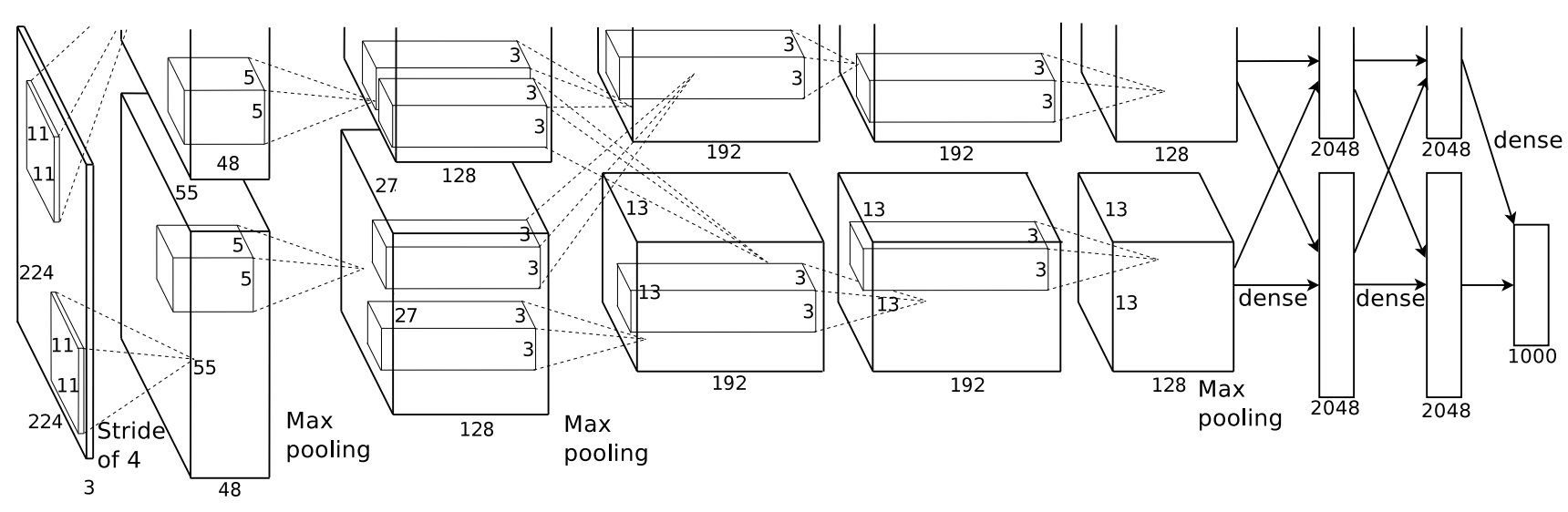
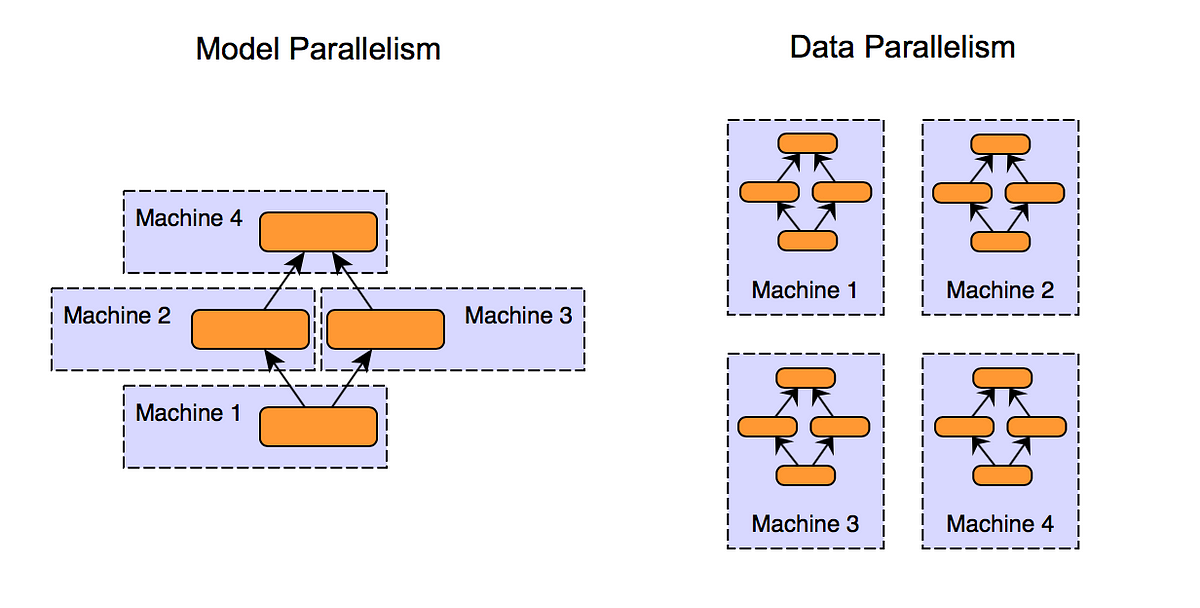
Figure 5. AlexNet was split in half in a model parallelism strategy to be able to fit the model in GPU memory (~3GB). [Image Source]
AlexNet (Krizhevsky et al., 2012). AlexNet was one of the first deep convolution networks to be successfully trained on a GPU. The model itself is tiny by today’s standards, but at the time it was far larger than anything that could be trained on a CPU. AlexNet was an 8-layer, 60M parameter model trained on 2 GTX580 GPUs with 3GB of RAM for ~5-6 days. It also featured some important design choices like ReLU activations and dropout that are still common in modern neural networks.
I came across this GitHub repository by user albanie that estimates the throughput of AlexNet’s forward pass to be ~700 MFLOPS, but I’m not sure where they got this runtime estimate from or what hardware it was run on. Regardless, it is most likely an upper-bound for the actual performance.
DanNet (Cireşan, 2011). DanNet was an earlier work by Dan Cireșan in Jürgen Schmidhuber’s lab that similarly implemented a deep convolutional network on GPUs to accelerate training on a variety of tasks. The method itself achieved great performance on a variety of image-based benchmarks, but unfortunately the work is often overshadowed by AlexNet and its success on ImageNet.I want to return to this paper because, while they don’t include the actual hardware used, they mention all the architectural components and dataset details to estimate the efficiency of their approach.
Remark. Interestingly, I found from this Sebastian Raschka blog that there were several other works that had adapted deep neural networks on GPUs. Nonetheless, none of these works had implemented a general-enough method to efficiently scale up the training of a convolutional neural network on the available hardware.
Part II.2: Deep learning frameworks emerge
So it’s 2012, and Alex Krizhevsky, a GPU wizard, has proven that we can successfully use deep learning to blow out the competition on a serious task. As a community, the obvious next step is to build out the infrastructure for deep learning applications so you don’t need to be a GPU wizard to use these tools.
Figure 6. The most popular deep learning frameworks as of 2024. [Image Source]
Theano (2012)From what I’m aware of, this library came out earlier, but a lot of the core deep learning features did not come out until 2012.. Theano was an open-source linear algebra compiler developed by the MILA group at Université de Montréal for Python, and it mainly handled optimizing symbolic tensor expressions under the hood. It also handled multi-GPU setups (e.g. data parallelism) without much effort, making it particularly useful for the new wave of deep learning. Personally, I found it quite unintuitive to use by itself, and nowadays it is used as a backend for Keras.
Caffe (2013). Developed at UC Berkeley, Caffe was an older, high-performance library for developing neural networks in C/C++. Models are defined in configuration files, and the focus on performance allowed developers to easily deploy on low-cost machines like edge devices and mobile. Eventually, a lot of features in Caffe/Caffe2 were merged into PyTorch, and by this point it’s rarely directly used.
TensorFlow v1 (2015). Google’s deep learning library targeted Python applications, and felt far more flexible far dealing with the annoying quirks of tensorsTry dealing with tensors in C++ and you’ll quickly see what I mean.. Like its predecessors, TensorFlow v1 also favored a “graph execution” workflow, meaning the developer had to define a computational graph of their models statically so it could be compiled for training / inference. For performance sake, this is obviously a good thing, but it also meant these frameworks were difficult to debug and hard to get used to.
Torch (2002) —> PyTorch (2016). Torch was originally a linear algebra library for Lua, but eventually it evolved into an “eager execution”-basedThe core idea behind eager execution is to execute the model code imperatively. This design paradigm makes the code a lot easier to debug and follow, and is far more “Pythonic” in nature, making it friendly for developers to quickly iterate on their models. deep learning library for Python. PyTorch is maintained as an open-source software, and is arguably the most popular framework used in deep learning research. It used to be the case that you had to touch TorchScript to make PyTorch code production-level fast, but recent additions like torch.compile(), TorchServe, and ONNXONNX was a standard developed jointly by Meta and Microsoft to allow models to be cross-compatible with different frameworks. ONNX is now useful for converting your PyTorch models into other frameworks like Tensorflow for serving. have made PyTorch more widely used in production code as well.
TensorFlow v2 (2019) & Keras (2015). Keras was developed independently by François Chollet, and like PyTorch, it was designed to be intuitive for developers to define and train their models in a modular way. Eventually, Keras merged into TensorFlow, and TensorFlow 2 was released to enable eager execution development in TensorFlow. TensorFlow 2 has a lot of design differences than PyTorch, but I find it relatively easy to use one after you’ve learned the other.
Jax (2020). Google’s latest deep learning framework that emphasizes its functional design and its just-in-time (JIT) XLA compiler for automatically fusing operations (we’ll talk about this more in the GPU section). Jax is more analogous to an amped up NumPy with autodifferentiation features, but it also has support for standard deep learning applications through subsequent libraries like Flax and Haiku. Jax has been getting more popular recently and has, in my opinion, replaced TensorFlow as Google’s primary deep learning framework. Finally, Jax has been optimized heavily for Google’s Tensor Processing Units (TPUs), i.e. anyone using cloud TPUs should be using Jax.
By this point, we’ve set the stage for deep learning to flourish — frameworks are being developed to make research on deep learning far easier, so we can now move on to talking about the types of architectures people were interested in and the core research problems of the time.
Part II.3: New deep learning architectures emerge
Here is where the focus of the field begins to diverge into applying these networks to different domains. For the sake of brevity, I am going to assume the reader is familiar with all of these works, so I will very loosely gloss over what they are. Feel free to skip this section.
Recurrent Networks (1980s - 1990s ish). Recurrent neural networks (RNNs) were popular at the nascent period of deep learning, with methods like GRU and LSTM being used in many time-series and language tasks. Their sequential nature made them hard to scale on parallel processors, making them somewhat obscure for a long time after. More recently, recurrent networks have been re-popularized in the form of state-space models (SSMs) for linear dynamical systems. Early versions of these SSMs used the linear-time-invariance (LTI) assumption to rewrite sequential computations as a convolution at the cost of flexibility. Recent works have removed these assumptions through efficient hardware implementations of critical algorithms like the Fast Fourier Transform.
Convolutional Neural Networks (CNN). CNNs were there from the beginning, and they still remain popular in the computer vision domain. The main component is the convolutional layer, which contains learnable “kernels”Kernel is an annoyingly overloaded term. In this case, it just means a small matrix that is convolved around an input. that are applied through a convolution operation on an N-dimensional input. Convolutional layers are nice because the learned kernels are often somewhat interpretable, and they have built in invariants that work well for learning spatial structure.
Graph Neural Networks. Graph neural networks are somewhat broad, but generally involve some parameterization of a graph using standard deep learning components like a linear weight matrix. They are very hard to implement efficiently on modern hardware (think how locality would be done) and can be very large and sparse. Even though most information can be represented as a graph, in practice there are only certain settings like social media graphs in recommendation systems and biochemistry where they have seen success.
Deep Reinforcement Learning (DRL). DRL generally involved approximating value functions (e.g. DQN) or policies (e.g. PPO) from the RL setting, which were traditionally represented as some kind of discrete key-value map. The standard RL setting is a Markov Decision Process (MDP) with some kind of unknown reward. DRL has also extended to post-training large language models by re-framing the alignment problem as some kind of reward maximization problem. DRL has traditionally also been hard to make efficient because 1) existing algorithms do not respond well to blind scaling, 2) agents interacting with an environment is inherently not parallelizable, 3) the environment itself is a large bottleneck.
Generative Adversarial Networks (Goodfellow et al., 2014). Also hotly contested whether these actually came out in 2014, but GANs were (a rather unstable) framework for training generative models. They had some nice theoretical guarantees (the input distribution is the optimal generator) but ultimately were hard to train, and they also were not great at high-resolution generations.
Diffusion Models (Sohl-Dickstein et al., 2015 & Song et al., 2020). I don’t have intuition as to why diffusion model generations turn out that much better than GANs, but from my own experience they definitely do. A lot of efficiency work in diffusion looks into reducing the number of noise/de-noising steps (which I find counterintuitive to how diffusion even works), and most parameterizations of diffusion models are just standard modules that are used in deep learning (e.g. MLPs, convolutions, transformers, etc.).
Transformers (Google, 2017). The Transformer block (and variants of it) are widely used today, and a lot of work over the past 5 years has gone into optimizing each component of the Transformer. Some of the key bottlenecks to get around are 1) the quadratic time and memory complexity of the attention mechanism w.r.t sequence length, 2) the growing KV cache that eats up on-device memory, 3) making Transformer computations faster on existing hardware. We will see a lot of these problems come up in the rest of this post.
Part II.4: Efficient convergence. Inductive biases and architectural choices
A natural question any researcher has when first exploring a domain is whether the existing mechanisms and algorithms are optimal. It was known that without tricks like dropout, regularization, the correct activation functions, learning rate scheduler, inductive biases, etc. your model would diverge or overfit on your data. It is way too difficult to pinpoint all of the architectural design changes over the years, and in, for example, the large language space, many of these changes are sort of “open secrets” — many researchers and engineers at large labs are probably aware of these tricks (e.g. local attention, RoPE embeddings, ReLU^2) but as a regular person like myself, it is hard to figure out these details from academic papers. This section will be dedicated to some cool changes that have emerged as empirically useful over the years.
II.4.a: Inductive biases that lead to better convergence behavior
There are many tricks that have been known empirically to lead to better convergence behavior for a lot of models — it is known that many older models struggled to even converge! We still don’t have a rigorous understanding for why many of these tricks are useful, but in this section we list some important architecture changes that have led to better convergence behavior. It’s not always 100% clear why these tricks work so well, so I won’t justify here.
Dropout (p). During training, randomly mask out $p$. It is believed to be an implicit regularizer.
Residual connections. First introduced in ResNet, add back the input to the output, effectively allowing data to skip layers.
Scaling depth/width. For convolutional networks, EfficientNet showed scaling depth/width accordingly is useful.
Approximating constraints. Optimization over constrained spaces can be annoying. It turns out sometimes relaxing constraints, such as birth of the reinforcement learning algorithm PPO as a relaxed and more widely-used version of TRPO.
Cosine Learning Rate Scheduler (with Annealing). In NLP settings, the cosine learning rate scheduler (with annealing) is widely used over other fixed and decaying learning rates.
Loss scaling. To prevent gradients from underflow or overflow (especially for quantization), a lot of optimizers have auto-tuned loss scaling enabled to normalize the gradients, then apply the inverse scaling factor.
ReLU and variants. For a lot of tasks, especially in NLP, ReLU and its smooth variants seem to work very well as activation functions.
Adam & AdamW. These momentum-based optimizers have proven to be the most impactful in deep learning despite a lot of research being done in this field.
Attention. The most famous deep learning mechanism today, attention seems to work very well at interactions over sequential data.
RoPE. Rotary embeddings have similar properties to standard positional encodings, but can be written as matrix multiplications (which we love) and work better in a lot of settings.
ALiBi. Additive attention biases have proven to work pretty well for length generalization.
bfloat16. Low-precision training in general has shown to be practical and useful, and the bf16 datatype, which trades of precision for a wider dynamic range than fp16, has shown to be more stable in deep learning training.
Mixture of Experts. It turns out we can keep scaling our models without all the parameters being active, and we still observe scaling laws.
II.4.b: Searching the space of solutions (meta-optimization)
A lot of traditional machine learning techniques revolve around doing some kind of grid-search and k-folds cross-validation to find the best possible model. In modern deep learning, it’s very hard to do this, especially when a single training run can cost millions of dollars. One of the more interesting spaces is neural architecture search (NAS), where we search a space of model configurations to find models that optimize some metric (e.g. performance, cost, speed) given some set of constraints. NAS isn’t really used in large model training, but it is extremely useful for trying to fit models onto low-cost devices — I’m not sure how much NAS has evolved since 2020, but I would highly recommend reading Lilian Weng’s blog on NAS!
Sakana AI’s Evolutionary Model Merge (Sakana AI, 2024). One of the newer works in NAS for language models is the evolutionary model merge algorithm, which takes components of already trained models and combines them to form various language and multi-modal foundation models. I haven’t played enough with these works to understand how effective they are, but they do demonstrate the ability to create unique models like a Japanese Math LLM with SOTA performance.
Part II.5: Efficient convergence. Optimizers
Recently, I’ve gotten the sense that optimizers are largely overlooked by many people because Adam “just works”. From the perspective of efficiency, if we can 1) compute our optimizers faster, 2) reduce the memory load of stored statistics, and 3) converge faster, then these are all wins to consider. The standard gradient descent update is written as
where $t$ is the iteration, $\eta$ is the learning rate, $\theta$ is the model parameters, $\mathcal{L}$ is the loss function, and $\mathcal{S}$ is the set of training values to use in the update. In standard gradient descent (GD), $\mathcal{S}$ is the entire dataset, in stochastic gradient descent (SGD) it is a randomly sampled $(x,y)$ pair, and in mini-batch gradient descent it is a randomly sampled subset. While GD has some nice and easy-to-prove theoretical guaranteesIt is quite well known, but look up the proofs for convergence for GD, descent lemma, and even the related empirics surrounding the edge of stability., SGD has similar guarantees and is often used in practice because it converges faster and is easier to compute.
Momentum [intro]. Theoretical guarantees for SGD and GD require knowing the smoothness behavior of the loss function, which in practice is not known. In practice, SGD suffers from “steep” regions in the loss curve that cause oscillatory behavior, motivating the use of the descent trajectory as a prior to dampen oscillations. The canonical momentum update is (where $\gamma$ is a constant around $0.9$ according to (Ruder et al. 2016)). The momentum version of SGD introduces a new term that depends on the gradient:
Adam (Kingma and Ba, 2014). It wasn’t mentioned, but Adagrad and RMSprop introduced per-parameter adaptive learning rates and an exponentially decaying average of past gradients. Adam combines these ideas by storing first and second moment estimates of the gradients $g_t$, which is shown in the equations below.The actual Adam also introduces a bias-correcting beta scheduler that modifies the first and second moment estimates slightly. They observed that because the estimates are zero-initialized, they are biased towards 0 if not normalized properly. Furthermore, a variant of Adam, called AdamW, also introduces iterative weight decay and is shown to work well in practice.
From a memory perspective, storing these extra statistics per parameter implies at least an extra 2x the number of model parameters has to be stored in memory during training. For large models, this extra burden is extremely problematic, as we have to figure out 1) how to fit this either into one device’s memory or multiple device’s memory, and 2) if we are using multiple devices, how to move data around effectively. Adam/AdamW is currently the standard for most large language model training as of 2024.
Preconditioning [intro]. Adam has remained the canonical optimizer for a long time, and most people are aware that it is a (stochastic) first-order optimizer. The benefit of a first-order optimizer is that they are relatively quick and only store extra statistics that is linear in the number of learnable parameters. However, it would be a more accurate estimate to use the second, third, etc. order estimates of our loss function Taylor expansion to approximate the correct update. We motivated Adam based on per-coordinate scaling factors, which is basically just applying a diagonal preconditioner to the gradient! Optimizers like Shampoo and Adagrad store preconditioners, but at varying levels of granularity (e.g. block diagonal vs. dense preconditioning matrix). On the AlgoPerf benchmark in particular, Shampoo has been shown to converge quicker than all pre-existing optimizers.
Part II.6: Pause. How much of this scale is really necessary
If you recall how std::vector<T> in the C++ standard library is implemented under the hood, you’ll remember that we have a capacity that marks allocated memory, and a true array size that is the memory that is actually being “used”. This terrible analogy was thought of at 4am just to say that as we continue to scale, a natural question is whether each parameter in the model is really that important.
Figure 7. Iterative pruning cycle for deep learning models. Generally, we train, prune, then re-train while ensuring the model does not collapse [Image Source]
II.6.a: Model Pruning
Learning both Weights and Connections for Efficient Neural Network (Song et al., 2015). One of the first successful pruning works in deep learning was done for convolutional models (e.g. VGG16, LeNet, AlexNet) on ImageNet. The idea was to first train the models, then zero out weights below a certain norm threshold, then fine-tune the pruned model to completion. They motivate this simple strategy as an implicit regularizer for overfitting, and show ~10x model compression rates while preserving 99% of the performance.
The lottery ticket hypothesis (Frankle et al., 2018). The lottery ticket hypothesis (LTH) is a famous theory that states: for every dense, randomly initialized neural network, there exists a sparse subnetwork that accounts for a majority of the performance. In the original paper, they prune the lowest $N\%$ of weights after a certain number of training iterations and show on a variety of image tasks and architectures that performance is preserved. The LTH arguably popularized a lot of derivative works on finding metrics for identifying prunable weights in a network.
SNIP (Lee et al. 2018). The LTH showed that post-training / during-training pruning was more effective than randomly pruning before training, so SNIP proposed a metric to prune “unimportant” weights before training. They first sample a random batch of data $D$ and compute the loss gradients $g_i = \frac{\partial \mathcal{L}(D, \theta)}{\partial \theta_i}$. Then, they compute
This metric measures how sensitive each weight is to a loss, so they prune the smallest $S(\theta_i)$. The authors show that they can prune 99% of a network (LeNet) with a 1% increase in error.
SynFlow (Tanaka et al. 2020). The authors first generalize pruning-at-initialization metrics to what they call “synaptic saliency” as a Hadamard product:
SynFlow was one of the first works to consider pruning from the perspective of “network flow”, as opposed just aggressively pruning weights with a low metric score. They consider scenarios where an entire layer is pruned, leading to a completely redundant network. Their experiments are mainly image models on CIFAR-10/100, but they generally showcase good performance on extreme pruning ratios (on the order of $10^{-3}$).
Are pruned models fast? From a hardware perspective, randomly pruning weights does not provide a large speed-up because operations like weight matrix multiplication rely on locality and targeting blocks of a matrix at one time. The standard implementation is to apply a $0$-mask to each pruned weight – which clearly provides no speed-ups – but clever implementations of pruning can target sparsity-aware kernels like in cuSPARSE and CUTLASSCheck out some of the Han Song lectures like https://www.youtube.com/watch?v=sZzc6tAtTrM&ab_channel=MITHANLab for more information on these topics.. Subsequent works on pruning focus on particular architectures or ensuring hardware-aware speed-ups through structured pruning (e.g. 2:4 pruning). Honestly though, model pruning hasn’t seen that much production-success because 1) many companies can afford to use larger models and 2) pruning generally often is not hardware-friendly, i.e. a 50% pruned model is much slower than a model that is just 50% of the number of parameters.
II.6.b: Embedding Pruning or Hashing
Recommendation systems is a practical field where “pruning” is somewhat applicable. In recommendation systems, users and items are typically represented as an ID that maps to a $O(10)$-dimensional embedding, meaning for social media companies like Meta and Snapchat, they will have on the order of millions or billions of embeddings in their models. For some napkin calculations, a full-precision 1B parameter embedding table with 64-dimensions each is 2 bytes * 64 * 10^9 = 128 GB for the embedding table, which is actually small in production settings! Without going into too much detail about the models themselves (for now, just abstract them as some kind of large transformer model), the embedding tables take up more than 90% of the memory load of learnable parameters.
Intuitively, under a vector space and with some assumptions about constraining the norm of each embedding, it is easy to see that we can probably cluster these embeddings in some meaningful way, and map multiple IDs to the same embedding without incurring much error. Many ideas in RecSys are not shared publicly, but common techniques like double hashing and locality-sensitive hashing are used in practice.
Figure 8. Using an explicit or implicit hash function (DHE shown here) is often used in practice to reduce the memory requirements of huge embedding tables. [Image Source]
Learning to Embed Categorical Features without Embedding Tables for Recommendation (Kang et al. 2020). Deep Hash Embedding (DHE) is a technique to replace an embedding table with a smaller, learnable transformation (e.g. a neural network). In other words, the hashing function is also implicitly learned alongside the embeddings themselves. Surprisingly, computing embeddings on the fly is pretty effective, but the unclear part for me is whether the values of the IDs have some implicit biasing effect on the embeddings produced.
II.6.c: Quantization
Figure 9. Quantization schemes involving working at a lower precision (e.g. 16-bit floating point, 8-bit integer) than the standard 32-bit floating point (FP32). [Image Source]
Quantization basically means instead of storing and using 32-bit floating point values (full-precision), we can use maybe 16-bit (half-precision), or 8-bit, etc. Doing so reduces the memory footprint of the model, but at the cost of precision. But there are actually many considerations, like whether you want to quantize during training or after training, whether you want to maintain model computations in a lower precision, and how to handle gradients in mixed-precision models.
The concept of quantization is not specific to deep learning and is more of a data compression problem. Generally, we are interested in reducing the memory footprint of our models — i.e. if we quantize a model with FP32 parameters to INT8FP32 means 32-bit floating point and INT8 means 8-bit integers. We will talk about this a little bit, but they are represented differently in memory. So even INT32 is quite different than FP32., we reduce the model size by 4x. However, as we will see later, modern hardware like the NVIDIA A100 introduces specialized instructions to significantly speed up lower precision operations. For now, we introduce some basic quantization strategies for transforming a value $X$.
Absmax quantization to INT{b} will map to the closed interval $[- \max |X|, \max |X|]$ then evenly divide up the interval into $2^b - 1$ sections. Each value will get mapped to its closest point in the above mapping, and the quantization range is clearly symmetric.
The danger of the above methods is the presence of outliers, which cause most quantization bins to be unused while increasing the quantization error. There are many other forms of quantization that do not have to be uniform in any way. Codebook quantization, for example, maps pre-defined values to a smaller set of pre-defined values, and the behavior of this map just has to be injective and well-definedI won’t be going into too much depth about the details of quantizing because it’s not that interesting. I also think that it’s better explained visually. I would recommend reading https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-quantization. The above methods quantize to some integer representation because it is quite intuitive, but quantizing from say FP32 to FP16 is not as obvious because these representations do not uniformly divide the range they represent.
IEEE754 and floating point representations. Integers are represented with the two’s complement and are evenly spaced; however, floating point values are not evenly spaced fractions. Instead, the IEEE754 standard uses one bit to determine sign, some of the bits as exponents, and some of them as fractions (called the mantissa), giving usThere are also special representations for values like $0$ of $\infty$, but honestly it’s not that important for us to understand.:
I’ve used the superscript to denote the number of bits used to represent that number. To clarify, the mantissa is the decimal part of the number $1.x$. In other words, in FP32, we have $23$ mantissa bits and $8$ exponent bits. However, other representations also exist to modify the representable range (increase exponent bits) or the precision (increase mantissa bits), which can be beneficial in deep learning applications.
BF16. The IEEE754 standard for FP16 uses 5 exponent bits and 8 mantissa bits. It was discovered by the Google Brain team, however, that using 8 exponent bits, which has the same dynamic range as FP32, was more stable than FP16 due to large gradients in LLM training. Furthermore, BF16 has the benefit of being able to easily convert to and from FP32 — just chop the last 16 bits of the mantissa!
FP8. NVIDIA’s newest H100s have Tensor Core support for 8-bit floating points, which are represented as either E5M2 or E4M3E5M2 meaning 5 exponent bits and 2 mantissa bits, and E4M3 meaning 4 exponent bits and 2 mantissa bits. Notice that with 8 bits, we can never do the FP32 → BF16 trick, but we can go from FP16 to E5M2.. We will talk more about Tensor Cores soon.
Automatic Mixed-Precision training (2018). In 2018, NVIDIA released the Apex extension to PyTorch, which introduced automatic mixed-precision (AMP) training on CUDA devices. The core idea is that lower precision BLAS operations are significantly faster with the introduction of hardware units like NVIDIA Tensor Cores, but not all operations (e.g. logarithms, trig functions) are safe to downcast due to their sensitivity to dynamic ranges / precision. Under the hood, torch.amp has a list of “safe” operations that are downcast to FP16/BF16 to provide essentially free speed-ups to the programmer. In most modern training schemes, you should be using AMP unless you want full control over your model operations.
II.6.d: The Grandfather of Efficient ML and TinyML
Figure 10. Deep Compression multi-stage memory reduction scheme, combining most well known methods of model compression at the time (pruning, quantization, compressing codes) to produce an extremely efficient network. [Image Source]
Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization, and Huffman Coding (Han et al. 2015). Arguably the most influential work in efficient deep learning for its time, this paper showed that combining simple magnitude-based weight pruning and codebook quantization was sufficient for cutting down existing images models like VGG-16 by ~50x while barely affecting model performance, enabling them to fit into on-chip SRAM. I wish there was some more analysis on the properties of these extremely compressed models and how this relates to the data distribution the model was trained on, because we do not see these levels of compression in modern LLMs.
Part II.x: Hardware
If you don’t know anything about a GPU except that it’s really good at parallel workloads, this section is a gold mine of information! I think this section motivates a lot of the future work very well, especially as we begin to consider hardware-aware algorithms for scaling our models. Otherwise, I would skip ahead to Chapter III.
You’ve probably noticed that up until this point, a lot of the aforementioned works were interested in improving and tweaking architectural components for the sake of better convergence behavior and ease of scaling. If your model doesn’t fit on a single GPU, find a way to divvy it up on multiple GPUs — we can sort of ignore optimizing for memory accesses, node-to-node latency, and other systems-y lingo because at this scale, it’s probably fast enoughThis isn’t entirely true, of course. There were definitely people who cared about these kinds of “engineering” problems, but AI wasn’t really a “product” yet. It was cool, and it had a growing list of applications, but nothing at the scale of a Google search engine or a streaming platform. . But as the field began to mature, people began thinking more about hardware-aware algorithms and how to utilize a lot of the new features offered by the CUDA ecosystem and NVIDIA GPUs. We focus a lot on CUDA because of its strong support in most deep learning applications, but also recognize and discuss other alternatives.
II.x.1: NVIDIA GPUs from Tesla (2006) to Ampere (2020)
Figure 11. A comparison of GPU throughput on INT8 tasks over the past 10 years. [Image Source]
Let’s continue where we left off. A lot of this section will appear kind of hand-wavy, but don’t worry — it makes a lot of sense to just assume things are a certain way before digging into why. If you ever become interested in the why, you’ll have to start reading denser sources of information. I recommend the PPMP textbook and the GPU MODE Discord!
Compute Structure. Let’s first talk about why GPUs are so good at parallelized computations. CPUs were designed to handle very complicated logic like branching (think if-else operations), and a large portion of the processor die is dedicated to this. NVIDIA GPUs instead trade off this chip space for more cores and specific hardware units that can perform instructions like small matrix multiplications in very few cycles. It’s like having 100 automatic sewing robots (GPU) vs. a human (CPU). Sure, the human being is smarter and more flexible/capable for general tasks, but if the task is to maximize production of clothes, it is much more useful to have the sewing robots. Starting from the Tesla series GPUs, NVIDIA used many CUDA cores with the SIMT (single-instruction, multiple threads) abstraction, so effectively a GPU really was just a bunch of small processors running in parallel. To understand how this abstraction works together with actual workloads, however, we need to understand how data is moved from the memory to the actual processors.
Hierarchical Memory Structure. The above is an extremely simplified view of how compute and memory are divided in a GPU starting from the Tesla architecture. Let’s assume that performing some kind of memory access from global memory (DRAM) is slow. This design emphasizes data reuse to minimize access to global memory. From Figure 12, we can also observe that different hierarchies of memory are shared across different abstractions (e.g. L2 cache is shared among SMs, but L1 cache is per SM), which is extremely important for optimization.
SMs (streaming multiprocessors) are the individual units that run their own processesThis is not entirely true. SMs actually have their own CUDA cores / streaming processors that get assigned the relevant work, but for our abstraction it suffices not to think about them., and you generally have on the order of $O(100)$ of these. For now, assume that they can run many threads (up to 1024) at the same time.
Each SM has its own registers (256K per SM on an A100), which are the fastest form of memory to access and write to.
L1 and L2 caches are a form of fast (roughly 10x faster than DRAM) but small memory — just assume for now that they are a limited but extremely valuable resource.
DRAM (dynamic random access memory) is the main working memory on a GPU. When you hear the term “A100 40GB”, it means that you are dealing with an A100 GPU with 40GB of DRAM. It is also often labelled as “high-bandwidth memory” (HBM).
Figure 13. Parallel compute hierarchy for modern CUDA devices. [Image Source]
Streaming Multiprocessors (SMs), Thread Blocks, Warps. The CUDA programming model is a bit convoluted at first glance, and it’s hard to motivate the design choices without understanding the hardware. Generally, the most important thing to understand is that:
Kernel/device functions operate at the thread-level, so we have to specify per-thread behavior in our device functions. Variables defined are implicitly accessed through registers.
We mentioned earlier that CUDA is SIMT — groups of threads called warpsshare the same instruction over different data (typically 32 threads per warp). Starting from the Volta architecture, threads actually have their own program counter and call stack and can call different instructions.
Each grid is independent (and run in parallel), and generally cannot communicate. For example, it is often convenient to launch an independent grid for each batch in the forward pass of a network.
We usuallylaunch kernels from the CPU/host. In PyTorch, it is implicit when we define our model code; in CUDA, it is using the triple bracket notation: f<<<<a,b>>>>(**kwargs), where a is the number of grids, and b is the number of thread blocks per grid. The hardware is responsible for scheduling these threads on the relevant devices to maximize device usage, or “occupancy”.
An example template of launching a CUDA kernel from the host is below.
__global__ void func(float *a, float *b) {
// Thread ID
int x = blockIdx.x * blockDim.x + threadIdx.x;
...
}
int main(int argc, char* argv[]) {
float* a, b; // with cudaMalloc, these are device pointers.
// Example of launching a GPU kernel from the CPU.
func<<<blk_in_grid, thr_per_blk>>>(a, b);
}
Compute-bound vs. Memory-bound workloads. In parallel GPU workloads, we are concerned with bottlenecks that limit the throughput of the entire workload. At a high-level, this can either be due to our cores being fed lots of operations, or due to blocking operations from data movement in memory. In most language-based deep learning applications, the latter occurs, and we call these programs “memory-bound”. Note that being compute-bound on an A100 does not imply that you will reach the ~300 TFLOPS advertised by the A100 — certain compute operations like activation functions are slower, as we will soon see. We often estimate these bottlenecks by computing the arithmetic intensity, which is the number of compute operations divided by the bytes accessed in memory. Finally, the CUDA ecosystem features a variety of profilers for developers to use to understand their programs, which we list in the Resources section.
Figure 14. Comparison of tensor core operations vs. non-tensor operations on A100 and H100 GPUs. [Image Source]
GPUs on Steroids: Tensor Cores (2017). If there was any concern about whether vectorized CPU operations could compete with GPUs, you can throw that all out the window due to the introduction of Tensor Cores with the release of the Volta microarchitecture in 2017. Tensor cores are specialized hardware units for performing 4x4 floating point matrix multiplications extremely fastCertain smaller precision data types like FP16 and FP8 are faster on later editions of Tensor Cores.. Because matrix multiplication can be re-written as block matrix multiplication and deep learning consists of a small set of operations, Tensor Cores are extremely useful, and optimizing throughput often comes down to sufficiently feeding the Tensor Cores. See Figure 14 for a comparison of Tensor Core speed on A100/H100 GPUs.
Intra-Device Bandwidth: PCIe vs. SXM & NVLink. When dealing with larger workloads, another bottleneck to consider is device-device and host-device communication bottlenecks. The standard interface is Peripheral Component Interconnect Express (PCIe), which can be used to connect devices to other devices or to the host. PCIe lanes connect your devices, and a larger number of lines provides more (potential) throughput for data movement. Starting from the Pascal microarchitecture, NVIDIA also began selling GPUs with the SXM form factor, which basically means they have specific ports for SXM interconnects and are connected on a specific SXM board (it still communicates to the CPU through PCIe). The SXM GPUs can also use NVLink, which is a special protocol for larger memory bandwidth. Generally, unless you are dealing with huge workloads, the type of intra-device communication will not even be the bottleneck you are looking for. For example, the H100 PCIe device-to-device bandwidth is 2 TB/s, while the H100 SXM5 device-to-device bandwidth is 3.35 TB/s.
Other relevant optimization details you can just assume exist. Understanding how to use these often involves profiling kernels and balancing the limited amount of “fast” memory we have. Many of these optimizations are highlighted in this amazing article on optimizing matrix multiplication in raw CUDA: https://siboehm.com/articles/22/CUDA-MMM. Because our GPU compilers aren’t unbeatable, it is useful to know many of the following details:
Shared memory: I didn’t mention this explicitly in the memory hierarchy above, but shared memoryNot to be confused with OS shared memory. The naming here is kind of confusing I’ll admit… is SRAM that is shared between all threads in a thread block. Many tricks involve using shared memory accesses over HBM accesses.
Thread coarsening: There is overhead for launching threads (it’s not free!) so sometimes it’s actually better to perform sequential operations on the same thread.
Memory coalescing: When we access HBM/DRAM, it is faster to access them in “bursts”, or contiguous chunks. In other words, we like structured accesses.
Constant memory: A small, global read-only memory that is useful when we have to re-use the same data a lot.
Pinned memory: When transferring between CPU RAM and GPU DRAM, NVIDIA GPUs have a Direct Memory Access (DMA) unit that handles the memory transfer to free up compute. Because the DMA uses physical addresses, the OS paging system can accidentally cause the DMA to transfer the wrong CPU memory — pinned memory is a primitive to ensure a chunk of memory will not be paged out, giving up speed-ups on this transfer.
Streams: We can avoid “waiting” sequentially for independent blocking operations by telling the device to put them on different streams, so it is safe to run them concurrently.
Parallel patterns. It is also important to understand what types of operations are known to be parallelizable. In deep learning, we understand that matrix multiplications (matmuls) are extremely efficient, but many other operations are also parallelizable and have well-known design patterns:
A comparison of notable GPU specs over the years. We’ll be using PCIe and not SXM numbers for reference here.
GPU
$\mu$-arch
Year Introduced
Peak Theoretical TFLOPS
Peak Theoretical Bandwidth (GB/s)
Notable inclusion.
GTX 580 3GB
Fermi
2010
1.58
192
Used to train AlexNet (2x).
Tesla P100 16GB
Pascal
2016
21.2
732
First datacenter GPU.
V100 16GB
Volta
2017
28.3 (FP16)
897
Introduced Tensor Cores.
RTX 3090 24GB
Ampere
2020
35.6
936
Popular consumer GPU for deep learning with a lot of VRAM.
A100 80GB
Ampere
2020
312
1935
Huge DRAM pool and very popular choice for clusters.
H100 80GB
Hopper
2022
1600 (FP8)
2040
Introduced new components like the TMA for accelerating LLM inference and training.
Energy costs. The power consumption of these devices is pretty important to know if you are using your own machines / clusters. I don’t have a strong intuition for these numbers, but generally they float around the $O(100)$ watts range for current high-end GPUs. For example, the A100 80GB consumes 250W when fully utilized, so it would come out to 600 kWh a day, which is roughly 40 USD in electricity bills if you live in the US. Tim Dettmers has a useful blog that explains these power considerations when building your own machine.
II.x.2: Google’s Tensor Processing Units (TPUs)
Figure 15. The architecture for a TPUv1 is actually pretty simple, with a strong emphasis on maximizing matrix multiplication throughput. [Image Source]
The CUDA ecosystem is not the only choice for parallel processing. Google’s in-house Tensor Processing Units (TPUs), first introduced publicly in 2016, are a custom application-specific integrated circuit (ASIC) designed for deep learning workloads at Google. TensorFlow and Jax have dedicated compilers for TPUs, making them the standard choice for programming these devices (PyTorch support has been added, but it’s not great).
While NVIDIA and AMD GPUs have features like the texture cache that are designed for gaming applications, TPUs specialize in high-throughput, low-precision matrix multiplication with low energy usage.
TPUs use their own systolic array “Tensor Core”, which handles 128x128 multiply-accumulate operations (compared to the 4x4 for NVIDIA!) in a single instruction cycle. This design favors large matrix computations.
The TPU features special instructions and hardware for activation functions and a super-fast buffer for moving data.
Google has since come out 6 generations of TPUs, with the latest using 256x256 Tensor Cores to accelerate even larger model computations.
You can’t actually buy your own TPUs, and you have to use cloud-provided TPUs (or work at Google) to use them for your own applications.
Similar to the design of SXM boards for NVIDIA GPUs, TPUs also have dedicated “TPU Pods” to connect multiple devices with high-speed communication.
II.x.3: Potpourri of other interesting hardware
The popularity of NVIDIA GPUs is in part due to the success of the Transformer and other parallelizable architectures. However, for different memory access patterns, there exist other hardware alternatives that could later play a pivotal role in the field.
Field-gate Programmable Arrays (FPGA).FPGAs have seen some use in efficient deep learning as a low-cost hardware to target. Because of the availability of GPUs and ASICs like TPUs, it is hard to justify designing and programming these devices for actual workloads. Nevertheless, I wouldn’t write off FPGAs — they have a variety of use-cases in the sciences and low-latency applications, and there is a chance that they will become important in deep learning as well.
Neuromorphic Chips. We know that the human brain is extraordinarily efficient and powerful (except maybe mine), so a natural question is whether we can design computer hardware around the brain. There are some primitives like Spiking Neural Networks that have been designed in the past, but most of this work has not really taken off in “modern deep learning”. There are also some small neuromorphic chips like IBM’s TrueNorth, but I haven’t seen significant progress in this area yet. Like quantum computers, however, I am hopeful that people crack this research direction and apply them to AI!
Etched (2024) [site]. Very recently, a startup company came out with a Transformer-specific ASIC called Sohu that they claim accelerates Transformer workloads (not sure if it’s also training?) by an undefined margin. Little information is known about the underlying hardware and how good it actually is, but a Transformer-specific ASIC itself is not a far-fetched idea.
Part III: The Era of Scale till we Fail (2020-Now)
GPT-3 (OpenAI, 2020). The introduction of GPT-3 was eye-opening for a lot of researchers in the field — simply scaling a Transformer to 175B parameters while maintaining the same tricks used in prior works in the field was sufficient to build a syntactically sound and somewhat semantically reasonable model. Furthermore, while most prior works had been task-specific, GPT-3 was flexible enough to perform reasonably on a wide variety of language tasks.
Figure 16. GPT-3, by design, was nothing complex. At its core, it was simply 96 stacked Transformer layers, an embedding layer for the tokens, and small output heads. [Image Source]
Its successor, GPT-3.5 / ChatGPT would later blow up the field of AI to the public, but these methods would introduce a combination of new post-training tricks (instruction-tuning & RLHF) and better data that are not rigorously understood. Scaling these models became a whole new game than all previous works, with the goal of building general-purpose “foundation models” that could be applied to any task. For this reason, the rest of this post will primarily focus on transformer-based architectures or recent alternatives (e.g. state-space models, Kolmogorov-Arnold Networks). Many of the following ideas certainly apply to existing deep learning methods, and molding these approaches to older algorithms is definitely a useful research direction that may yield meaningful results.
Part III.0: Let’s talk about the H100 GPU
NVIDIA’s Hopwell microarchitecture (2022), along with the H100/H200 GPUs, introduced a few notable new features to accelerate deep learning workloads. In addition to having effectively more/faster memory, higher memory bandwidth, and more CUDA & Tensor Cores than the A100, the H100 also features:
Tensor Memory Accelerator (TMA). The whole concept behind “streams” that we introduced before was to ensure non-overlapping operations like memory movement and using the Tensor Cores were done in parallel. The TMA is a new hardware unit that asynchronously computes memory addresses (this is not a free operation on older devices and had to be done with registers!) for fetching data between shared memory and global memory. In other words, we no longer need to dedicate threads to perform data transfers and can instead focus on feeding the Tensor Cores.
High-speed low-precision. Tensor Cores now support the FP8 data type and can theoretically reach 3300 TFLOPS for FP8 operations.
Thread block clusters. A new level of the CUDA programming hierarchy sits above the thread block — all threads in a thread block cluster are concurrently scheduled onto SMs, making communicating between them more efficient with the CUDA cooperative_groups API.
SM-to-SM shared memory. They formally call this distributed shared memory, but basically a programmer can now access shared memory that sits on other SMs (presumably through a shared virtual address space) without having to move it to the L2 cache / global memory.
DPX instructions. The promotional material for these instructions keeps claiming that they “accelerate dynamic programming (DP) algorithms”, but I’m pretty sure from the Hopper guide that it’s just specialized instructions for min/max and additions that are common in DP algorithms — the actual loop and sequential nature of DP isn’t changed at all.
With the release of the H100, a few interesting developments have been made to target these devices, including FlashAttention3, which we will talk about in the coming section.
WGMMA (Warpgroup Matrix-multiply-accumulate)This blogpost by Colfax is so good: https://research.colfax-intl.com/cutlass-tutorial-wgmma-hopper/. The wgmma.mma_async instruction allows threads to launch matrix multiplication on the Tensor Cores as a non-blocking operation. In other words, they’re free to handle other tasks like data loading to further increase throughput and hide latency.
ThunderKittens (Spector et al., 2024). The H100 has a lot of new features that are really annoying to target yourself. ThunderKittens is a domain-specific language (just an extension on top of CUDA C++ basically) that you can use to abstract away a lot of these features at the warp-level while the compiler handles all of the nitty-gritty details. I haven’t tried it myself because I don’t have an H100, but it looks like a promising library to consider using. I also included the blog in this section because it has some nice details about how they target the H100 that are really well-written!
Part III.1: The Era of Scale (on a single GPU)
By this point, there were clear signs that scaling up the number of parameters in a model and the amount of data was almost purely beneficial for improving model capabilities. The obvious solution to scaling networks was to 1) add more compute and 2) wait for longer training runs. But adding devices is extremely expensive and does not linearly add more memory and training speed as we will discuss in Part III.2, so there was a lot of interest in squeezing out as many FLOPS and bytes out of every GPU as possible. Before it was settled that the attention mechanism was extremely important as is, alternatives with better runtime and memory scaling were first proposed.
III.1.0: Early insights
Activation checkpointing (Chen et al., 2016). One widely used technique for trading speed for memory is to re-compute activations during the backwards pass instead of storing them during the forward pass. This idea is also used to speed up overall training in important works like ZeRO due to the nature of the GPU memory hierarchy, which we will cover in the next section.
KV Caching (2017?).I actually have no idea when this trick was first introduced — my guess is that it was sort of an obvious engineering trick that people knew about for a while, but didn’t really need to talk about in publications until LLM serving became bigger as a field / after ChatGPT came out in 2022. For causal Transformers (upper-triangular mask), a well-known trick for next-token prediction is to store the previously computed keys and values in memory, so we only need to compute $K/V/Q $ for the most-recent token. A large number of works we will discuss deal with the growing KV cache, which takes up a large chunk of valuable DRAM and is not a fixed size.
III.1.a: Shaving complexity through Approximate Methods
Figure 17. Approximate attention through masking patterns introduced in LongFormer. [Image Source]
A long series of works have proposed approximations to the general attention mechanism in hopes of scaling these methods to sub-quadratic memory and runtime. We list some notable examples in chronological orderNot all of the code examples are the official code repos. I referenced lucidrains a lot because his (PyTorch usually) repos are just a lot easier to digest and are stripped down to the important code.:
Sparse Transformers (Child et al., 2019) [Paper] [Code]. Early work on constraining fixed sparse attention patterns (across heads, though this isn’t too relevant anymore) so each query can only attend to $O(\sqrt{N})$ of the keys. They evaluate on a variety of image and audio tasks, although the results aren’t high quality for today’s standards.
Reformer (Kitaev et al., 2020) [Paper] [Unofficial Code] This idea is really cute — they posit that attention weights are largely concentrated on a few elements, so they use a locality-sensitive hashing scheme find the $K=\log(N)$ nearest keys for each query and only compute those for the attention mechanism.
Linformer (Wang et al., 2020) [Paper] [Unofficial Code]. They reason using the Johnson-Lindenstrauss lemmaThere are many variants, but the core idea is that we can (randomly) project points in a high-dimensional normed space to a lower-dimensional normed space such that distances are preserved up to some error that is a function of the number of points in the space. Basically, it’s used a lot whenever we want to analyze whether moving to lower dimensions is “fine”. that when computing the attention matrix, they actually just compute it as a product of two low-rank matrices. Their proposed decomposition is extremely simple, and it literally is just projecting down the key and value matrices to a constant dimension.
Longformer (Beltagy et al. 2020) [Paper] [Code]. Longformer is just an empirically-motivated set of masking patterns over the attention matrix for efficiency. They mainly use a sliding window local attention scheme (see Figure 17), but also allow attending sparsely to global positions.
Performer (Choromanski et al., 2021) [Paper] [Unofficial Code]. Instead of using a low-rank or sparsity assumption, they observe that the attention operation $A(i,j) = \exp(q_i, k_j^T) = K(q_i, k_i)$ is a kernel, which can be written in the form $\phi(q_i)^T \phi(k_i)$. The choice of $\phi$ is motivated to be an unbiased estimator using random featuresSee https://gregorygundersen.com/blog/2019/12/23/random-fourier-features/ for background., and ultimately the decomposition removes the annoying softmax function and reduces the number of operations.
InfiniAttention (Munkhdalai et al. 2024) [Paper] [Unofficial Code]. InfiniAttention avoids sequence-length time/memory complexity by storing a recurrent-style attention matrix that is fixed size, but is updated in memory. They chunk up sequences and sequentially process them, theoretically enabling infinite scaling at the cost of a fixed representation.
While many tricks like sparsity, low-rankness, and kernel decomposition were tried, in the end, most of these methods are unused in modern LLMs. Some of the more practical approximations for the attention mechanism are a lot simpler in practice and provide clear memory or runtime improvements over the original.
Figure 18. Grouped query attention is a simple approximation method to share keys/values across heads. In the diagram above, each “vector” is a head rather than a single key/query/value vector. [Image Source]
Grouped Query Attention (Ainslie et al., 2023). A super simple but widely used approximate attention method is to preserve the standard per-head attention, but instead share keys/values across different heads to reduce the memory footprint. The original work (multi-query attention) re-used the same keys/values across all heads, but in this work they find it better to tune this re-use factor. It turns out that we can get away with this in practice, and from an implementation stand-point there is no hidden drawback to doing this.
III.1.b: Architecture Design
Some architecture choices have been motivated by existing bottlenecks in scaling large models. For language models, the naive approach is to just increase the number of attention blocks, but there are other methods that balance memory and capacity tradeoffs differently.
Figure 19. Mixture-of-Experts layer used in the Switch Transformer to scale LLMs to trillions of parameters without exploding working memory. [Image Source]
Mixture-of-Experts in NLP (Shazeer et al. 2017). Mixture-of-Experts (MoE) is an older techniqueHuggingface has a nice article on the history, which dates back to the 90’s: https://huggingface.co/blog/moe#a-brief-history-of-moes for scaling deep learning models to extremely high parameter counts without needing to access all the parameters at any time. The first interesting application was done on the LSTM architecture, and generally it consists of a small learnable gating network that activates a subset of the parameters sitting on different devices. As we will see, MoE is particularly useful for LLMs, as it enables scaling model capacity without scaling the resource consumption.
Primer: Searching for Efficient Transformers for Language Modeling (So et al., 2021). There are plenty of existing works for tweaking and modifying the attention architecture to “scale” better. I’ve referenced this paper because it is quite simple and is one of the earlier works to propose tricks like ReLU^2 and neural architecture search over Transformers. I’m not entirely sure what is done in practice, but as far as I know, there are generally some “good practices” for Transformer blocks, and it is difficult to perform these architecture search algorithms for extremely large models.
Switch Transformers (Fedus et al., 2021). Their central hypothesis was that scaling model parameters while keeping FLOPS constant was still a useful dimension of scale. They replace the FFN MLP layer in the Transformer with an MoE router that routes each token after the attention block to an expert, while also fixing the maximum number of tokens each expert can process. They also add a super simple load-balancing loss that penalizes non-uniform token routing. As it turns out, MoE enables us to scale our models to upwards of trillions of parameters without actually incurring the cost of a trillion parameter model on each forward/backwards pass! It was rumored last year that GPT-4 was a giant 1T MoE model that used tricks like group-query attention and rotary embeddings (RoPE).
III.1.c: Fine-tuning Large Models Efficiently
It is well known that pre-training large foundation models is way out of the budget of a standard researcherFor example, Llama-3 is known to have cost tens of millions of dollars to pre-train.. Fine-tuning or general post-training (e.g. instruction tuning and RLHF) has become a popular research avenue because it is significantly cheaper and can be task-specific. Researchers began to notice over time that shortcuts could be made to the fine-tuning process to make it feasible for independent researchers to play with.
Adapters (Houlsby, 2019). The distinction between fine-tuning and pre-training is actually indistinguishable from a standard machine learning perspective, unless we specifically constrain the optimization problems to be different. To make fine-tuning computationally cheap, Adapters are learnable functions $f_{\hat{\theta}} : \mathbb{R}^n \rightarrow \mathbb{R}^n$ that can be inserted in between the layers of a model. The idea is that we freeze the original model weights $\theta$, and only update the adapter weights $\hat{\theta}$, significantly reducing the memory and fine-tuning time of a model. Intuitively, adapters make sense in the context of language modeling because we believe that fine-tuning should not alter the weights “that much””that much” is super hand-wavy. I’m not actually sure if there’s a paper out there that uses norms or other metrics to discuss similarity between a fine-tuned and pre-trained model. If not, could be an interesting research question. from the base model.
LoRA (Hu et al., 2021). Given a pre-trained model with parameters $\theta$, the central hypothesis of LoRA is that a fine-tuned model weights can be decomposed into $\theta + \Delta \hat{\theta}$, where $\Delta \hat{\theta} \in \mathbb{R}^{m \times n}$ is low-rank and $\theta$ is frozen. In other words, we can factorize $\Delta \hat{\theta} = AB$ where $A \in \mathbb{R}^{m \times r}$ and $B \in \mathbb{R}^{r \times n}$ and $r \ll \min(m,n)$Strangely, I don’t have a lot of intuition for learned matrix decomposition. This idea is popular in recommendation systems / factorization machines, and is supposedly SVD-esque, but I don’t know what properties you can derive from these factorized matrices. If anyone knows, please tell me! . Furthermore, unlike adaptors, LoRA adds no extra overhead during inference time!
Figure 20. In Q-LoRA, they quantize a Transformer to 4-bit NormalFloat (NF4) and perform LoRA over a larger selection of weights due to the extra allowable memory, which they attribute to its good performance. They demonstrate that fine-tuning a 65B LLM can be done with 48GB of DRAM (on a single device!) with minimal performance degradation. [Image Source]
Q-LoRA (Dettmers et al., 2023). This landmark paper enabled a lot of future work on fine-tuning LLMs, diffusion models, and other foundation models on a single device. They observe that 1) base models are still huge and need to fit in memory when using LoRA, 2) activations/gradients have a large memory footprint in LoRA, which activation/gradient checkpointing can partially solve, and 3) block-wise quantization can have many constants take up significant space in memory.
To solve (1), they introduce the 4-bit NormalFloat type, which quantizes the weights by evenly dividing the range based on the Gaussian measure.
To solve (2), they introduced a paged optimizer based on NVIDIA unified memory to move optimizer states between GPU DRAM and CPU RAM when necessary, as they are only used for backpropagation.
To solve (3), they quantize the quantization constants to a lower precision. Q-LoRA is basically a whole collection of memory reduction techniques for performing LLM fine-tuning on affordable hardware. The LoRA component remains untouched, but the memory reductions allow LoRA to be applied to all layers in a model for better performance.
Combined together, a Q-LoRA tuned layer can be written as:
Huggingface PEFT Library. There are a few other major parameter-efficient fine-tuning (PEFT) works like LoRA and adaptors such as prefix tuning, soft prompts, and $(IA)^3$ that all kind of boil down to “I believe that we can fine-tune a model by slightly adding or injecting information to the pre-trained model”. Honestly, PEFT as a whole is extremely hand-wavy, and a lot of the methods are ways to condition or perturb model weights based on the fine-tuning dataset. HuggingFace has a nice wrapper for running different PEFT methods for your models. For details on specific PEFT variants, I’d suggest reading this survey paper.
Remark. I couldn’t really fit this work in, but I wanted to mention ReFT, which I think is a really cute idea that turns out to work well in practice. Based on the hypothesis that high-level concepts in language model are directions in some representation space, they fine-tune model generations by learning disjoint “interventions” over the model hidden states (i.e. an adapter motivated by interpretability work). I haven’t fully read into the interpretability work that led to DII, but their experiments are pretty convincing.
Eventually, it became clear that cute tricks like sparsity and dimensionality reduction on the attention mechanism were not only hurting model performance, but they weren’t even providing wall-clock speed improvements to these models. You may have heard the term “fused kernel” used to describe an optimization to a deep learning model. The term kernel is overloaded quite often, but in this instance it just refers to a program run on the GPU. We focused a lot in the earlier sections on building up models as modular, stackable components that we could freely optimize, but allowing this flexibility is not necessarily hardware-friendly. Consider the following example for computing the attention operation in PyTorch:
In eager execution mode or without a clever compiler, every assignment $y = f(x_1,x_2,…)$ in the code above will do something like this.
The variable(s) $x_1,x_2,…$ will be sitting in the GPU DRAM/HBM. We first have to load it onto the processors/SMs, which is quite slow.
We perform the transform $f(x_1,x_2,…)$ on device. This operation is relatively fast because the torch functions (e.g. torch.matmul) are heavily optimized.
We store the result $f(x_1,x_2,…)$ which sits on device registers back into DRAM, and point to it with the variable $y$.
If $y$ is ever used in subsequent lines, we have to load it back into registers, and repeat.
Fused kernel implementations usually aim to remove these intermediate stores and loads to DRAM that Python compilers cannot optimize out. Depending on the level of granularity in the language used (e.g. Triton vs. CUDA), we can control data movement at all levels of the GPU memory hierarchy. To get a sense for the relative speeds of each level of the hierarchy, we list some data movement speeds on an NVIDIA H100 GPU found in this microbenchmarking work. For reference, the H100 runs at roughly 1.5 GHz, or $1.5 \times 10^9$ clock cycles per second.
Type of Memory Access
Number of Clock Cycles
HBM Access
~480 clock cycles
L2 Cache Hit
~260 clock cycles
L1 Cache Hit
~40 clock cycles
Shared Memory Access
~30 clock cycles
Register Access
~1 clock cycles
In the following section, we’ll talk a bit about existing fused kernel strategies for attention, followed by some examples in other fields.
Figure 21. Visualization of the original FlashAttention implementation and the associated GPU memory hierarchy that it optimizes. [Image Source]
FlashAttention (Dao et al., 2022). Standard attention implementations, like the PyTorch implementation above, involve several passes to and from GPU DRAM/HBM. The key insight in building the fused attention kernel is computing the softmax block-by-block — however, computing the softmax requires loading all keys into a block, which does not fit into the limited SRAM space. The authors instead minimize accesses to global memory by using a trick called the online softmax while simultaneously loading in the relevant value blocks. Furthermore, they re-compute the attention matrix in the backwards pass. Launched kernels are parallelized over the batch size and the number of heads.
FlashAttention2 (Dao, 2023). The successor implementation of FlashAttention minimizes non-matrix multiplication operations such as the online softmax scaling term, which are significantly slower due to A100 Tensor Cores — while the max throughput for FP16 matmuls is 312 TFLOPS, for standard FP32 operations it is only 19.5 TFLOPS. Furthermore, they avoid intra-warp synchronizationRecall that threads in a warp call the same instructions SIMT-style. However, across warps in the same block, we often will call a block-level synchronization barrier with `__syncthread()` when we need to wait for all previous threads to finish. The authors minimizes these barrier calls in FA2 by changing which warps handle which matrices. If this whole explanation is confusing to you, I totally understand. The original paper has some nice diagrams that explain it better, but it’s definitely a GPU-specific detail. by switching how they loop over the $\mathbf{Q}$ and $\mathbf{K}/\mathbf{V}$ matrices. One particular limitation of these methods is no support for custom attention masks and attention biases, which is now supported in FlexAttention as of August 2024 (I also had written a Triton implementation for FA2).
FlashAttention3 (Shah et al., 2024). The latest version of FlashAttention specifically targets the H100/H200 GPUs, and the focus reads completely differently from v1 and v2. Namely, the new WGMMA instruction we talked about in Part III.0 and the TMA offer essentially free speed-ups. Furthermore, separating data loading (TMA) and computation (WGMMA) in different warps, a technique called warp specialization, is also used to maximize Tensor Core usage. Finally, the authors observe that non-matmul operations like exponentiation in softmax are up to 256x slower than matmuls, so they manually schedule warpgroups in a pipelined fashion to reduce potential bubbles created by these interleaved operations.
xFormers (Facebook Research, 2021) [Repo]. The xFormers repository features a series of CUDA and Triton kernels for various Transformer components like attention, layer norms, dropout, etc. Prior to the release of FlexAttention, the xFormers repo was also the standard for a fast attention algorithm with custom attention biases.
Liger Kernel (Hsu et al., 2024) [Repo]. Recently, a large number of fused kernel implementations for LLM training were released by researchers at Linkedin. In addition to being more memory-efficient and faster than pre-existing Huggingface implementations, they are extremely easy to understand because they were written in Triton.Some of these kernels were featured in depth in one of the GPU Mode lectures: https://www.youtube.com/watch?v=gWble4FreV4&ab_channel=GPUMODE
Other examples. While fused kernels have seen extensive interest in transformer-based LLM applications, there are other areas where fused kernels were critical to their success. We list a few notable examples below.
FlashFFTConv (Fu et al. 2023). It is well known that for functions $u(x), v(x)$ with Fourier transforms $\mathcal{F}(u), \mathcal{F}(v)$, the convolution can be written as $ \{u * v \} (x) = \mathcal{F}^{-1} \{\mathcal{F}(u) \cdot \mathcal{F}(v) \} $. It is also well known that the Fast Fourier Transform can be computed in $O(N \log N)$, so we can compute convolutions for state-space models in $O(N \log N)$ where $N$ is the sequence length! However, despite the better runtime complexity than attention, in practice, Transformers are still faster to train on modern hardware. FlashFFTConv re-writes the FFT into a different decomposition that contains matrix multiplications to take advantage of Tensor Cores.
Mamba: Linear-Time Sequence Modeling with Selective State Spaces (Gu et al., 2023). Prior state-space model methods (e.g. S4) impose a linear-time-invariant (LTI) constraint on the state update matrices so they can be re-written as a convolution to avoid the sequential computation needed for recurrent algorithms. While these models were interesting at the time, Mamba was a huge deal in the community because it removed the LTI constraint and added an input-dependent selection mechanism for its parameters. To remove the LTI constraint, the authors wrote a kernel to keep the recurrent state in fast shared memory to keep the computation fast.
InstantNGP (Müller et al. 2022). The novel view synthesis problemThe novel view synthesis problem is generating unseen views of a scene given a few reference images. With a fine granularity, you can even produce entire videos or interactable scenes from just an image. has mostly been solved using Neural Radiance Fields (NeRFs), but the computational bottleneck of increasing resolution was large. InstantNGP was a hashing scheme for position-dependent features that was entirely written as a fused kernel, and is widely used as a standard in many subsequent NeRF works as well.
MSA Pair Weighted Averaging for AlphaFold3 (Me!). AlphaFold3 is a closed-source scientific breakthrough (most notably winning the 2024 Nobel Prize in Chemistry!) developed by Google DeepMind for predicting generic molecule interactions. While they most likely developed the model in Jax and optimized it for their in-house TPUs, researchers and start-ups outside of Google are interested in using the model for their own biotech use-cases. Ligo Biosciences is a start-up developing an open-source version of this model, but certain algorithms such as the Triangular Multiplicative Update and the MSA Pair Weighted Averaging algorithm have extreme memory bottlenecks when written naively in PyTorch. I was interested in was writing fast and readable kernels for these algorithms (both forward and backwards passes), which I wrote in TritonTriton is a programming language (it’s more of a library for Python) that compiles to an intermediate representation (IR) that NVIDIA GPUs can use. Rather than abstract at the thread-level like we’ve discussed for CUDA, it instead operates at the thread block level, and is far easier to prototype with. We will talk about this later, but torch.jit() compiles to Triton code.. The MSA Pair Weighted Averaging algorithm in particular also has a pesky global softmax operation, and I used tricks similar to FlashAttention2 to minimize HBM accesses. Removing these bottlenecks has helped them feasibly scale their models on more data!
III.1.e: Deep Learning Compilers
Another parallel thread that the community was interested in was building specialized compilersI’m going to assume the reader is at least familiar with what a compiler is useful for. A lot of the optimizations done by programming language compilers like constant folding and register assignment are also done by a deep learning compiler, and LLVM itself is used in this setting for compiling to the instruction-level. for deep learning operations. ML compilers are really annoying to build because 1) there are so many different hardware devices that we can use (e.g. CPU, GPU, TPU, other ASICs), 2) in a standard compiler like gcc, we would normally have access to the entire codebase we are compiling. For ML, a “codebase” is basically the model computation graph, but this isn’t always accessible (i.e. eager mode in PyTorch)On point (2), you probably don’t need a powerful compiler unless you are running production code, in which case you should not be running your models in eager mode. Regardless, as we will see, the PyTorch team still added an option through torch.jit() for compiling parts of your eager execution code..
Figure 22. Deep learning compilers are hard to develop because different devices have completely different memory hierarchies and compute primitives. [Image Source]
Intermediate representations (IR) are a critical element of modern compilers — instead of building a compiler for each pair of (language, hardware), we would ideally like to compile each language into a common intermediate language that can be converted to each specific machine code. Deep learning applications are typically optimized in two steps, namely graph-level optimization of operators, and low-level optimization of the actual device-specific instructions. Below, we discuss some important frameworks and compilers that have evolved throughout the years — the list is not comprehensive (check out https://github.com/merrymercy/awesome-tensor-compilers!), but focuses mainly on applications that have been popular for a while.As I was researching this section, I came to the realization that a lot of it starts to bleed into standard compilers research, which is extensive and difficult for me to motivate. I’ve instead decided to just provide some high-level intuition for what these frameworks do, but I won’t be touching on the exact optimizations and design choices for each of these compilers, which was my original intention.
ONNX (PyTorch Team, 2017). ONNX is not actually a compiler, but an open-source standard format and inference engine (ONNX Runtime) for model computation graphs across different libraries. Most libraries allow you to export your models to ONNX, allowing you to use their optimized runtime engine, as well as convert models easily between libraries. Many of the libraries listed below accept or expect a packaged ONNX model as input.
Figure 23. Most DL compilers first optimize over the compute graph, then target specific devices for a second pass of optimizations. [Image Source]
Agnostic stacks. These frameworks are designed for developers to be able to modify and add certain parts of their compilers stack (e.g. targeting your own edge devices), and are widely used as general purpose compilers. They often features multiple IR conversion and optimization steps, and provide functionality for targeting your own hardware.
TVM (Chen et al., 2018). TVM is an open-sourceend-to-end compiler stack for common deep learning platforms and targets a wide range of hardware. TVM first converts compute graphs into a directed-acyclic graph (DAG) IR called Relay — you may have learned about let-based IRs in your undergraduate compilers class that allow for optimizations like dead-code elimination, and a DAG IR is basically just the equivalent for a graph. The individual tensor operators have a separate optimization step, and TVM uses functional “tensor expressions” to define these operators. TVM has a ton of other really cool features like auto-tuning for specific data/hardware formats that are beyond the scope of what I really understand, but I would highly recommend reading the DL compilers survey for a high-level overview of TVM and other compilers.
MLIR. The Multi-Level Intermediate Representation (MLIR) is an extension to LLVMAgain, sort of assuming you know what it is. In case you don’t, LLVM is a really powerful and language-independent library that features the LLVM IR. You would generally convert your language of choice into the LLVM IR, LLVM would perform a bunch of optimizations, then it would convert the IR into your hardware of choice. Before LLVM, dealing with compilers across different hardware was a pain in the ass. LLVM is also used for these deep learning compilers as well. that essentially allows you to define your own IR / dialect based on existing MLIR dialects — in other words, you don’t have to define an IR completely from scratch. MLIR is extremely useful in the context of deep learning compilers, because we often care about multiple optimization passes at different abstractions, which MLIR gives you the flexibility to define. MLIR works well with a lot of the compilers / tools we will list below — to get started, I found this post pretty helpful: http://lastweek.io/notes/MLIR/.
Examples of prominent specific-compilers. These compilers are technically general-use, but are mostly used to target specific devices or specific libraries. Unlike the frameworks above, they are highly optimized for specific use-cases and are much more useful as tools rather than personal development. If you’re not very interested in compilers, it is nice to know some of the stuff listed below.
nvcc (NVIDIA, 2007). nvcc is NVIDIA’s compiler for CUDA to PTX (NVIDIA GPU’s assembly code). As far as I’m aware, a lot of the details about how what the compiler does under the hood are proprietary.
XLA (Google, 2017). The accelerated linear algebra (XLA) compiler is mainly for linear algebra workloads in TensorFlow/Jax. It also features a just-in-time (JIT) compiler and operates at the computation graph-level. The OpenXLA project designed it to be able to target other non-TPU hardware as well.
TensorRT (NVIDIA, 2019).TensorRT (and now TensorRT-LLM) are inference engines that target NVIDIA devices. Given a computational graph in PyTorch/Tensorflow or ONNX, these libraries apply a set of optimizations (e.g. layer fusion, quantization, kernel selection) on CUDA devices for low-latency inference.
PyTorch’s Compilers over the Years. PyTorch supports both eager execution and graph execution, and it compiles these separately. Recently, PyTorch 2.0 introduced the torch.compile() decorator for easily applying JIT compilation to your code (with some restrictions of course). The PyTorch umbrella includes several different compilers such as the two-phase IR Glow (2018), nvFuser (2022), and the JIT compiler TorchDynamo + TorchInductor.
Triton IR (Philippe Tillet / OpenAI, 2021). Triton is a domain-specific language for programming NVIDIA GPU kernels in PythonIf you’ve used Triton, you’ll notice the compute hierarchy is less granular than CUDA. Kernels operates at the block level, and there are specific functions for loading memory into threads. The other downside is the reliance on the Triton compiler when new hardware comes out, e.g. targeting H100 features like the TMA.. By default, the torch.compile() function generates Triton code using TorchInductor. Triton has its own compiler, which converts Triton code into the MLIR-based Triton IR. The Triton-JIT compiler then optimizes this code and generates PTX code. I have found Sasha Rush’s GPU Puzzles to be quite useful (my solutions). I also found the Liger Kernel repository, which we talked about earlier, to be a well-written set of examples for learning Triton.
Remark. There is honestly a lot more to talk about regarding deep learning compilers, and compilers in general, but it is hard to motivate it at a high-level without going into details. There’s also a lot that goes into the design choices for specific optimizations, and I’m really not an expert on this stuff. I linked this earlier, but I did find The Deep Learning Compiler: A Comprehensive Survey to be extremely informative on the design choices of these compilers.
Part III.2: The Era of Scale (distributed version)
Imagine that you are a {insert big tech company or unicorn startup} in 2020, and you are now a big believer in scale — you want to build, say, a trillion parameter model, but you now have a whole suite of new problems in the distributed setting. I previously mentioned adding more GPUs as an “obvious” solution to scaling models, but doing this is a lot harder than it sounds — a lot of work goes into minimizing various overheads, circumventing communication errors, and building fault-tolerant and stable algorithms for distributed workloads.
Figure 24. Differences between model parallelism and data parallelism. Model parallelism partitions a model across devices, and has potentially blocking operations. Data parallelism partitions along the batch dimension. [Image Source]
III.2.a: Data parallelism
Suppose I have a 1B parameter (~2GB) language model that I want to train on the C4 dataset (~750 GB). One common approach to accelerating training is to increase the batch size to increase the training throughput by taking advantage of the GPU’s parallelism (e.g. Llama 3 uses a batch size of each least 250K). Because we know that models make updates after batches of training, the naive approach is to put a copy of the model on each GPU and distribute the batch across multiple GPUs so it can fit in memory. Certain libraries like PyTorch have wrappers that handle distributing and gathering gradients across GPUs to make sure the model copies on each device are in syncSee the DistributedDataParallel module: https://pytorch.org/docs/stable/generated/torch.nn.parallel.DistributedDataParallel.html. The most common data parallel scheme is to distribute a large batch of samples $B$ across many devices, compute the forward and backwards passes, then sum and broadcast all gradients to all devices in an MPI-allreduceThere are a bunch of collective operations like allreduce that are used to communicate effectively across multiple nodes. For example, the NCCL operations can be found here: https://docs.nvidia.com/deeplearning/nccl/user-guide/docs/usage/collectives.html operation.
Figure 25. Visual example of how sharp minima can be problematic when minimizing the training loss function — these issues can be attributed to a slight mismatch between the testing loss function and training loss function. [Image Source]
On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima (Keskar et al., 2016). Data parallelism effectively provides a linear relationship between the number of available GPUs and the allowable batch size during training. This work empirically show that as we increase the batch size $B$, their models (applied to MNIST and CIFAR-10, both old and relatively small by today’s standards) begin converging to non-general solutions, which they attribute to large-batch solutions converging to sharp minima (e.g. areas of the loss landscape where the eigenvalues of $\nabla^2 f$ are large), and not to overfitting (see Figure 25 above)Computing the eigenvalues of the Hessian is hard, so actually in the original paper they approximate the sharpness measure, which you can read about in the original paper.. So even if your model can fit on a single GPU, the effectiveness of data parallelism saturates as we scale. It has therefore become more interesting to cleverly parallelize our model computations across multiple devices.
III.2.b: Model parallelism
Like data parallelism, model parallelism is not necessarily that technically novel or interesting, but it is still extremely important and relevant today. Data parallelism relies on the model (+ optimizer states and data) fitting on a single GPU, but for large models this may not be possible (e.g. 400B parameter full-precision model is ~800GB just for model weights, far too big to fit on any GPU). AlexNet, for example, split the model across two GPUs in the original implementation, as they only had 3GB of RAM. Model parallelism is far more complex than data parallelism in that there are “blocking” steps — if we have a model with layer A which goes into layer B and we put the layers on different devices, we have to wait for layer A to finish before starting computation in layer B.
Mesh-Tensorflow (Shazeer et al., 2018). The core idea behind data parallelism is to split tensor computations along the batch dimension, which is free because model operations over these dimensions are entirely independent. In Mesh-Tensorflow, they propose an automatic strategy for splitting tensors along arbitrary dimensions (hence generalizing data & model parallelism) and scheduling them across multiple devices. The idea is that we can define a meshgrid of processors to handle tensor transformations in parallel, so this method does not reduce waiting times due to causal sequences of operations.
Another similar term you will probably see a lot is “tensor parallelism”, and it’s basically a form of model parallelism where we partition the weights of a layer along a particular dimension and place them on different devices. Megatron-LM, which we talk about in III.2.d, relies heavily on tensor parallelism.
III.2.c: Pipeline parallelism
Model parallelism & Mesh TensorFlow suffer from significant downtime when dependencies are involved. For example, if we split a model into layer A and B, where the output of A is the input of B, the devices holding layer B are blocked until layer A is finished. Pipeline parallelism is basically like pipelining in computer architecture — we pass partially computed tensors to satisfy dependencies, while also keeping GPU utilization high.
Figure 26. Pipeline parallelism increases GPU utilization for model parallelism schemes and reduces bubbling. [Image Source]
G-Pipe (Huang et al., 2018). One of the first open-source pipeline parallelism works for deep learning, G-Pipe is extremely simple and intuitive. To avoid stalls, they simply schedule sequential “micro-batches” on each device, so if device B has to wait for device A, it can process an earlier micro-batch while waiting for device A to finish its micro-batch. Like pipelining, there are bubbles that occur in this simple process, but compared to model parallelism, it significantly increases GPU utilization. They naively handle the backwards pass by waiting for all forward pass micro-batches to finish, due to the reverse layer-order dependency of the backwards pass. Finally, they perform a synchronous model update across all devices.
PipeDream (Narayanan et al., 2018). PipeDream was a concurrent work that developed a slightly different strategy. In addition to adding pipeline stages, they also interleave available backwards computations (e.g. when the first microbatch finishes its forward pass) with scheduled forwards passes to reduce bubbling caused by the reverse layer-order dependencies of backpropagation. PipeDream also features an automatic work partitioner for roughly dividing each pipeline stage to be equal in computation time. I didn’t talk about this in the context of GPipe, but uneven pipeline stages causes bottlenecks and therefore extra stall time.
Some other follow-up works like PipeDream-2BW (Narayanan, 2020) and WPipe (Yang et al., 2022) essentially minimize the stall / bubble time of the above methods, but are far more specific and still use the core idea that G-Pipe and Pipedream proposed.
III.2.d: Architecture-specific Parallelism
This mini-section is somewhat overlapping with the previous two, as model and pipeline parallelism are not necessarily architecture-agnostic. It should be pretty clear that there are certain considerations like load balancing and how to partition the model that are difficult to optimize when the model architecture is unknown. There are many recent works that focus on parallelizing specific architectures for scale, especially transformers.
Megatron-LM (Shoeybi et al., 2020). The aforementioned distributed training frameworks have pretty complicated implementations, and have evolved over time to include extra optimizations as well. The core thesis of Megatron-LM is to reduce overhead communication costs and assign operators in a Transformer models purely by intuition, and they identify synchronization points (basically where the devices will stall) that they can remove. Since then, Megatron-LM has changed significantly to be a framework for scaling languages, with two subsequent works https://arxiv.org/abs/2104.04473 and https://arxiv.org/abs/2205.05198, as well as a library called Megatron-Core for handling large-scale training.
III.2.e: Multi-node distributed training
We can generally get away with multi-GPU workloads on a single node (e.g. a DGX A100 8x80GB server) without having to deal with a scheduling algorithm or factoring node-to-node network bandwidth as a bottleneck, but as we start scaling even further to pre-training foundation models, we have to consider multi-node multi-GPU training frameworks.
Figure 27. ZeRO-DP features 3 different stages of optimization, each of which partition more data across the devices. The base version of data parallelism makes copies of everything on every device, and each stage of ZeRO-DP partitions different types of data to reduce the overall memory footprint. [Image Source]
ZeRO (Rajbhandari et al., 2020). ZeRO cleans up most of the redundant memory footprint in data-parallel training schemes by partitioning across multiple devices / nodes. ZeRO is a family of optimizations separated into two classes: ZeRO-DP for “states”, and ZeRO-R for “residual memory”The paper introduces residual memory as activations, temporary buffers, and fragmented memory, but this is basically like the constantly changing / temporary data..
ZeRO-DP targets various types of memory such as optimizer states (stage 1), gradients (stage 2), and the actual parameters of the model (stage 3). The general strategy is for each device to be responsible for holding and updating a partition of these components in memory, while requesting certain partitions only when needed (updates are made with a final all-gather or reduce-scatter). For example, when partitioning the model parameters, instead of performing model parallelism, where layer A sits on device 1 and sends its outputs to layer B on device 2, device 1 will instead grab layer B from device 2 and compute it all on device.
ZeRO-R also centers around the partitioning strategy, but instead patches up a lot of the potential redundancies caused by ZeRO-DP. ZeRO-R handles activation checkpointing with a partitioning strategy similar to those found in ZeRO-DP (basically request it when you need it), but also uses a buffer to ensure requests are sufficiently sized while also handling memory fragmentation by pre-allocating contiguous memory chunks as needed.
There are a lot of rich details regarding how each optimization is ZeRO is implemented using node communication primitives that can be found in the original paper. ZeRO has since evolved into a family of optimizations for multi-device deep learning workloads and is directly usable with multi-device deep learning libraries like deepspeed.
Figure 28. An example of how RingAttention partitions query and key/value blocks on different hosts and also how this can result in redundancies with a causal mask. [Image Source]
RingAttention (Liu et al., 2023) [unofficial code]. When we increase the effective context window of a model, we start getting to the regime where a single attention operation has to be split across multiple devices. Recall from our discussion of FlashAttention that we can compute attention by splitting $Q$ and $K,V$ into blocks. The Blockwise Parallel Transformer (BPT) takes this further by also fusing the subsequent feedforward layer with the attention layer, which operates independently on each $Q$ blockAllow me to clarify. When you look at FlashAttention, you’ll notice that the output block $O$ is computed by taking a block $Q$ with all the keys and values. In other words, $Q$ and $O$ are synced, and $K$ and $V$ are synced. Each FFN layer gets applied independently along the sequence dimension of the $O$ block, so we can apply it immediately when any $O$ block is computed.. RingAttention uses the intuition from BPT with one more observation: for every output block $O$, we compute it using a query block $Q$ and all key/value blocks, and the order that we load $K/V$ blocks is entirely permutation invariant! Thus, we can form a “ring” of host devices that each handle one query block, while we move each $K/V$ block from host to host to compute the $O$ block so each query block will see each $K/V$ block exactly once in some arbitrary order. This scheme overlaps the communication cost of moving around the $K/V$ blocks with the BPT computation, effectively hiding most of the latency that a naive distributed Transformer would have.
StripedAttention (Brandon et al., 2023)
StripedAttention is an extension of RingAttention that avoids redundancies caused by causal attention masks — instead of placing contiguous $K/V$ blocks on each device, they shuffle the keys/values to avoid completely masked out blocks (see Figure 28).
III.2.f: Libraries for distributed deep learning workloads.
Multi-GPU and multi-node algorithms like ZeRO have been integrated into libraries for developers to use. The community has moved extraordinarily fast on producing libraries for multi-device training and inference, making it possible for people with no knowledge to use multiple devices. In this section, I want to talk a little bit about those libraries, as well as provide some context for what is going on under the hood. We begin with a simple example of how to run basic distributed training in PyTorch.
PyTorch example. In PyTorch, we start by initializing a process group on each device that defines a master address/port, its device rank, the world size, and a communication backend.
The master address and port from the master node, which generally controls the whole distributed system, is set across all nodes.
The device rank or world rank is a unique identifier in $\mathbb{N}$ for each device in the distributed network. The local rank is the identifier of a process within a node (e.g. gpu:0), and the world size is the total number of devices.
The communication backend is the protocol that defines how messages are sent and received across nodes and devices, as well as the available communication collectives (e.g. send, recv, all_reduce, all_to_all, reduce_scatter, etc.).
Modern libraries like deepspeed will make these primitives a lot easier for you, and will even make launching these applications with their CLI tools a lot simpler (you’ll probably just have to run deepspeed program.py ...). If you were to manually run a distributed workload (e.g. with PyTorch’s DistributedDataParallel or by defining your own sends and receives), you would typically have to run the program on each separate node while specifying their individual ranks.
Node communication backends. Under the hood, multi-node and multi-GPU workloads need to communicate and send data. Most libraries take care of this for you, but they will often have you define a communication backend — each of these serves a slightly different purpose and have various tradeoffs.
nccl. NCCL is NVIDIA’s communication protocol specifically designed for inter-(NVIDIA)GPU communication. It is the recommended backend for most deep learning applications on NVIDIA devices.
gloo. Gloo is more flexible for supporting CPU-GPU communication as well as GPU-GPU communication, and is often noted to be more useful for CPU-intensive distributed workloads.
mpi. MPI has been the standard backend for most high-performance computing (HPC) applications.
Some relevant modern libraries. You can definitely code up a multi-GPU or multi-node job in PyTorch or TensorFlow, and most experienced developers choose to do this in favor of flexibility. However, there are many choices for libraries / CLI tools that handle multi-device training for you, and we list some in A.2: Large training / finetuning frameworks.
Part III.3: Scaling Laws
Characterizing model performance as a function of scale is a useful signal for whether any advances in efficient deep learning are even important. There are even works that look into predicting training curves, but in this section we mainly focus on observed empirical scaling laws and what they imply. All of the following scaling laws focus on characterizing the generalization / test loss in (nats/token), which is just the average negative log-likelihood with respect to the evaluation set. To keep this post focused on efficiency, I will mainly be glossing over results and leaving it to the reader to learn more about specific constant ranges or empirical findings.
Deep learning Scaling is Predictable, Empirically (Hestness et al., 2017). One of the first papers to present empirical scaling laws on a wide range of tasks (image, language, machine translation, speech) as a function of the training set size. They model test loss as a function of dataset size:
$$
\mathcal{L}(D) = C \cdot D^{\alpha} + \gamma
$$
and find that existing theoretical works estimate these constants incorrectly — prior works estimate $\alpha \sim -0.5$, while the empirical ranges they found were in $[-0.35, -0.07]$. Interestingly, they find in their experiments that the power law exponent $\alpha$ changes across tasks, while $C$ changes based on model architecture and choice of optimizers.
Figure 29. Single-variable power-law functions of the test loss align closely with the empirical results in (Kaplan et al., 2020).[Image Source]
Scaling Laws for Neural Language Models (Kaplan et al., 2020). This paper proposes scaling laws across dataset size $D$, model size $N \in [768, 10^9]$, and compute budget $C \in [10^{12}, 10^{21}]$ FLOPS. They focus mainly on Transformer decoders on trained on WebText2, and they first analyze single-variable scaling laws by fixing $2/3$ of the above variables at a “sufficient level” and analyzing the third. They estimate in these models that each parameter costs roughly 6 FLOPS per token in the forward + backwards pass. These scaling laws are a power-law function of the test loss:
They notably discover through experimentation that:
Counting embedding parameters for $N$ does not result in the nice power-law relationship we would expect, but excluding them does.
Performance depends strongly on model scale and weakly on model shape, which is consistent with the findings of (Hestness et al., 2017).
Increasing $N$ and $D$ at a fixed rate $N^{\beta} / D$ is necessary to observe performance gains in the scaling laws.
They also derive test loss as a function of multiple variables, which are consistent analytically when you take the limit of one variable (think of it as a form of marginalization). Using this function, they propose an optimal allocation of resources given a fixed compute budget. For specific coefficients and rationale for their fitting functions, I would highly recommend reading the original paper — they have a lot more conclusions and experiments than what I’ve discussed above!
Chinchilla (Hoffmann et al., 2022). This landmark paper in neural scaling laws for LLMs is a collection of over 400 large-scale experiments (all Transformers with a cosine schedule learning rate and trained on one epoch), entering the foundation model range (70M - 16B parameters, 5B - 500B tokens) that (Kaplan et al., 2020) does not touch on. From an efficiency perspective, they are interested in optimal cost budgets, i.e.
In their experiments, they vary both the number of training examples for a fixed model size and the model size for a fixed FLOP budget, and fit (+ motivate) the scaling law according to the function (with fitting parameters $A_0, A_1, \alpha, \beta, \gamma$).
Under their fitted power law, they set a constraint budget $6ND \leq C$ for their proposed compute-optimal Chinchilla model. In the domain of large language models, scaling law papers are hard to come by because of the sheer cost of running experiments. Other works like Beyond neural scaling laws, Transcending Scaling Laws with 0.1% Extra Compute, and Scaling Data-Constrained Language Models explore how scaling law constants change under different datasets, constraints, and model assumptions. From an efficiency standpoint, there will always be interest in deriving the upper-bound of power law constants $\alpha,\beta$.
Part III.4: Revisiting downwards scaling
A natural analogue for neural scaling laws is the lower bound of compute necessary to achieve some level of model performance. In the era of foundation models and Transformers, model compression methods have evolved to deal with the challenges of large-scale models trained on huge datasets.
III.4.a: Small Language Models (SLMs)
With foundation models getting too large to fit on affordable hardware, there has been a growing interest in how to train a small language model that performs the same as a large language model. A lot of the subsequent sections are relevant to training SLMs from scratch and from an LLM.
The Phi models. The Phi models are a series of open-source SLMs from Microsoft Research designed to emphasize the value of high-quality training data. This idea may contradict the scaling laws we discussed in the previous section, but actually the scaling laws bake in assumptions such as properties of the data distribution, types of models used, etc. that aren’t universally covered.
Phi-1 (Gunasekar et al., 2023). phi-1 is a 1.3B parameter model trained on 6B tokens of high-quality scientific/textbook material for coding. Compared to other models at the time, which were generally 10x bigger and trained on 100x more tokens, it displayed near-SOTA performance on HumanEval (Pass@1) and MBPP (Pass@1), which were the primary coding benchmarks at the time.
Phi-1.5 (Li et al., 2023). As a follow up, they build more 1.3B parameter models trained on “textbook-quality” data generated by LLMs and show near-SOTA performance on reasoning tasks beyond coding! It’s unclear how the learned distribution is affected by this synthetic training data trick, but for Phi-1.5 it seems to work fairly well.
Phi-2, Phi 3, Phi-3.5 (Microsoft, 2024). Subsequent iterations of the Phi models were larger (~2-3B parameters) and trained on significantly more high-quality filtered & synthetic “textbook” data. They demonstrate the capabilities of these models across language, vision, and multi-modal tasks, and also introduce a mixture-of-experts version (~6B params) to compete against models of a similar size like LLaMA 3.1, Mixtral, GPT-4o-mini, and Gemini-1.5-Flash.
Similarly sized models follow the same training recipe (i.e. really “high quality” data seems to affect the power law constants positively), but not all of them are open-source.
Figure 30. In Sheared LLaMa, they preserve locality and dense matmuls while pruning large language models by pruning at a higher abstraction. The diagram above shows an example of pruning out attention heads and hidden dimensions without the need for sparse kernels. [Image Source]
Sheared LLaMA (Xia et al., 2023). Existing pruning techniques mentioned in II.6.a: Model Pruning have found little success in the large language model space due to the lack of hardware-aware structure. Instead, in this work they prune at a higher abstraction such as the number of layers, attention heads, and hidden dimensions to enable hardware-aware structured pruning for language models. They also introduce “dynamic batch loading”, which is an online optimization-style problem for adjusting the proportion of data from each domain that is added to the training batch. I am hopeful that more theoretically motivated versions of this technique will be useful for faster convergence.
Knowledge Distillation (KD).I apologize for keeping this section brief. I think KD is a very rich field, but there just isn’t much to talk about except how to improve matching the distribution of one model to another. In terms of “efficiency”, I don’t have that much to say about the topic. Knowledge distillation emerged around the time when other methods like pruning and quantization were popularized, but the more interesting ideas like black-box knowledge distillation came about due to the closed nature of a lot of large models. Generally, the idea is to start with a large language model (teacher) and produce a small language model (student) by “distilling” the behavior of the large language model into the small language model.
White-box KD means we have access to the logits/distribution of the large teacher model, and our optimization objective is to align the distribution of the student to the distribution of the teacher (e.g. through KL divergence). MiniLM claims that KL is not the right optimization objective for language, but works like Baby LLaMA have shown that standard white-box KD can yield good results.
Black-box KD is interesting in the era of large models because many SOTA LLMs are available through APIs. One of the more interesting techniques is Zephyr, where they fine-tune a small open-source model with SFT + DPO by generating (instruction, response) pairs from a larger closed-source model. Given the fact that people train their models on synthetic model-generated content (e.g. GPT-4), it is not that surprising that black-box KD works in this wayAs a side note, I wonder what this implies about the distribution of “language” we are learning and what kind of space it lies on..
III.4.b: Modern quantization techniques
We revisit the topic of quantization and some popular research directions related to it. Quantization is especially interesting for language models because it can be made efficient for modern hardware without affecting the architecture of the model. However, unless the entire model is quantized, quantization methods still suffer from a lack of hardware support for speed-ups.
Figure 31. In LLM.int8(), the authors observe that when scaling OPT beyond 2.7B, naive post-training 8-bit quantization collapses. They attribute model collapse to outlier features that cause large quantization errors to propagate throughout the model. [Image Source]
LLM.int8() (Dettmers et al., 2022). While FP32 and FP16 (+ mixed precision training) have been shown to work fairly well with LLMs, this work was the first to perform 8-bit (INT) quantization for large-scale LLMs. The authors discover that <1% of input features have a high variance/magnitude, which causes a large quantization error when going down to 8-bit representations. They also find that this “outlier” phenomenon occurs along the same hidden dimensions across most sequences, so they separate these outliers out using an outer-product notation for matrix multiplication. More formally, for outlier dimensions $O$,
Lastly, they assign quantization constants to each row of the input and each column of the weight matrix (vector-wise quantization). Interestingly, they attribute model collapse in Figure 31 to quantization errors propagating across all layers in larger models.The author of LLM.int8() and QLoRA (Tim Dettmers) has also built the [bitsandbytes](https://github.com/bitsandbytes-foundation/bitsandbytes) library for quantizing / fine-tuning LLMs using these techniques. It is an extremely simple and popular wrapper around Huggingface transformers for quantizing your models!
GPT-Q (Frantar et al., 2022). Following the same trend as before, GPT-Q quantizes LLMs to the 4-bit regime while stably reducing generalization perplexity for large models. They focus on layer-wise quantization, meaning they isolate each layer and do not consider layer-to-layer effects. Following the Optimal Brain quantization framework, they minimize the following quantization error:
$$
\text{argmin}_{W^q} \| WX - W^q X \|_2^2
$$
Intuitively, what we’re doing here is quantizing a row of the weights, then adjusting the full precision weights to minimize the error, and iteratively performing this update. There are closed form solutions to this iterative update by Taylor expanding the error above that were originally derived in (Optimal Brain Surgeon, 1992), but GPT-Q modifies/approximates the algorithm to maximize GPU utilization. Like other quantization methods at the time, quantizing the rows at different granularity did not enable any speed-ups on GPUs.
Figure 32. Activation-aware weight quantization (AWQ) is far more effective than naive weight quantization without any fancy machinery.[Image Source]
Activation-Aware Weight Quantization (AWQ) (Lin et al., 2023). The authors observe in experiments that only a small percentage of weights in an LLM are “salient”, meaning they are extremely sensitive to quantization. Furthermore, they observe that the saliency metric is dependent on the input data (i.e. the activation resulting from the weight times the input). Thus, prior to the post-quantization step, they sample a subset of the original data distribution and find the high-variance activations to determine salient weights (see Figure 32.b). Instead of keeping these salient weights at full precisionFrom a hardware perspective it’s always hard to intermix weights at different precisions because 1) you need kernels that can handle this and 2) the way it’s stored in memory is not convenient — imagine implementing a C-array that can take multiple types. Indexing into the array with pointers would be a pain., they find in theory that adding a computed scaling factor can reduce quantization error without affecting the range of representable values (see Figure 32.c). They demonstrate their method by using 4-bit AWQ on LLaMA-2 70B to deploy on a single NVIDIA Jetson Orin 64GB.
Figure 33. The fact that 1-bit/ternary weights have been shown to work for LLMs is cool, but it also features a significantly simplified relationship between the input and the weights — no scalar multiplication! [Image Source]
BitNet (Wang et al., 2023). Another research direction that emerged was quantization-aware training, where a model stores weights and gradient updates in full precision, but computes the forward pass in the quantized regime (a straight-through estimator is used for gradient computation). BitNet replace all linear layers (e.g. nn.Linear or just the $W$ matrices) with rounded 1-bit variants (i.e. $W_{i,j} \in $ { $-1,1$ }) and quantize the activations to 8-bits with absmax quantization. While BitNet was a cool experiment, the results were subpar compared to other existing quantization techniques, and the produced model was not any faster on existing hardware than a standard LLM.
BitNet b1.58 (Ma et al., 2024). A follow-up and arguably more successful variant of BitNet was the ternary version (i.e. $W_{i,j} \in$ { $-1,0,1$ }). The recipe is basically the same, except they compare to a half-precision LLaMA {1.3B, 3B, 7B, 13B, 70B}, and demonstrate better / comparable performance on a wide range of language reasoning tasks, as well as significantly faster throughput (up to 10x) and less active memory usage (up to 4x reduction)I have very little intuition as to why this paper does so much better than BitNet (maybe something key about LLaMA models?) and I think this paper should do a better job of explaining it as well. As much as I want to believe something like this works, it seems almost too good to be true in most practical settings. I hope some more follow ups investigate the “whys” that this paper leaves open.!
SmoothQuant (Xiao et al., 2023). Most of the aforementioned methods focused more on memory reductions rather than speed improvements. Like other papers, the authors observe that outliers cause a lot of problems for quantization schemes. SmoothQuant chooses to work entirely in the quantized regime for both weights and activations without needing to dequantize anything. Because we can’t control outliers in the activations (this is input dependent) but we can control the initial distribution of weights, SmoothQuant adds a per-channel scaling factor based on a calibration setSimilar to what AWQ does (from the same lab), they use calibration sets as an approximation of the data distribution. to scale down outlier activation channels, and a corresponding inverse per-channel scaling factor to the weight matrix. Effectively, they squash outliers in the inputs by introducing some outliers to the weights, which they argue is better than large outliers.
Under this scheme, we never need to go back and forth between different precisions, so we can directly apply low-precision kernels that enable speed-ups!
III.4.c: Sparse Parameters
One research direction that hasn’t really taken off for the past few years is introducing sparsity or sparse decompositions to model parameters. We mentioned in III.1.a: Shaving complexity: Approximate Methods that sparse attention methods were just not efficient on modern parallel processors, which is not entirely true(-ish).
Figure 34. Different attention masks (dense and sparse) that can be written in a fused FlashAttention-like CUDA kernel on parallel processors. [Image Source]
StreamingLLMs with Attention Sinks (Xiao et al., 2023). It should be somewhat clear by now that pre-defined sparsity patterns can be made efficient on GPUs. In this work, they return to window attention masks (causal mask that can only attend back a certain length) and add the ability to attend to a fix (set of) “attention sink” tokens, which they hypothesize contain global information due to the inherent structure of the attention mechanism. Furthermore, the authors develop efficient fused kernels in https://hanlab.mit.edu/blog/block-sparse-attention for efficiently handling these sparse patterns.
Sparse factorizations. One really interesting direction a few years back was factorizing model layers into sparse parameters, but ultimately it didn’t really take off. I am hopeful that people continue working on this direction, because derivable factorizations can say something about how our models work.
Butterfly Matrices (Dao et al., 2019). In this work, they show that a large class of structured matrices (e.g. FFT, DFT live in this family) can be recursively factorized into sparse matrices with a nice block diagonal structure. While the implementations are not hardware friendly, these factorizations theoretically lead to a reduced number of operations and memory-footprint.
Monarch Matrices (Dao et al., 2022). As a follow-up, they derive a less-expressive class of matrices with hardware-friendly factorizations. Despite now being practically interesting, I haven’t seen much follow up work in this area in recently.
Part III.5: What about model inference?
The introduction of ChatGPT (2022) made it clear that building infrastructure to support querying large models ( i.e. model serving) was a necessary research direction. In addition to the compiler optimizations offered by inference engines like TensorRT for speeding up model code, people also began thinking about how to handle and schedule batches of user requests. The primary considerations were minimizing the latency of each user request, and maximizing the throughput of processing all user requests. Furthermore, due to the nature of KV-caching that we discussed in III.1.0: Early Insights, these systems generally have to distinguish between the pre-filling stage, where an initial prompt is fed into the model and all keys/queries/values are computed, and the decoding phase, where cached KVs can be re-used, and only one new query token is considered.
llama.cpp (Gerganov, 2022). One of the coolest solo projects by Georgi Gerganov is a pure C++ implementation of the LLaMA family that optimizes for non-GPU devices (it now supports GPUs). It has since become a standard tool for running model inference on a variety of language models, and is extremely simple to use with its CLI. The downside is that adapting this code for custom LLMs is difficult without a strong understanding of the underlying implementation.
III.5.a: Generative model serving
The most naive form of model serving for generative Transformers is to batch a bunch of requests, process them, then distribute the results back to each user. There are a lot of annoying considerations like non-uniform length prompts, non-uniform length generations, and how to handle the KV cache in memory (which is not small!) that people quickly began figuring out in the past two years.
Figure 35. In order to optimize token-level scheduling, Orca exploits an observation that linear layers can be arbitrarily batched, while attention operations cannot, so they selectively batch operations to enable scheduling requests of different lengths. [Image Source]
Orca (Yu et al., 2022). One of the first open-source engines for model serving optimized for throughput. Given a batch of requests, their scheduler works at the token-level (they call it iteration-level), meaning it doesn’t care if two requests were launched at different times. Furthermore, they notice that certain operations in a Transformer in non-batchable requests (e.g. they’re in different stages or of different lengths) can actually be batched — any linear transforms can be batched regardless of length (see Figure 35).
Figure 36. Prior to vLLM, most serving engines would pre-allocate a buffer in DRAM for the KV cache to live on, resulting in several forms of memory fragmentation and insufficient memory usage. Reserved inefficiency is when a smaller batch request could be using memory that a larger request will later use, but can’t because it’s pre-allocated. Internal fragmentation occurs when memory was pre-allocated but is never used. External fragmentation is your typical malloc memory fragmentation, where small pockets of contiguous memory are free but inaccessible because the KV cache is always larger. [Image Source]
vLLM and PagedAttention (Kwon et al., 2023). Keeping the KV cache on the same device is critical for keeping model throughput high, as it avoids overhead communication costs. However, prior works like Orca handle the KV cache naively — they generally pre-allocate a fixed length memory buffer for the KV cache, which causes several memory inefficiencies highlighted in Figure 36. Furthermore, these methods have no way of sharing KV caches for shared prefixes across multiple requests. PagedAttention mitigates these issues by introducing ideas from virtual memory in an operating system — they block up the KV cache into equal and fixed size chunks and use a translation table to map them to physical DRAM. Equivalent chunks in different requests get mapped to the same physical memory, enabling memory sharing. While the KV blocks are not contiguous in physical memory, the elements in the block are locally contiguous and internal and external fragmentation are significantly reduced. vLLM is a serving engine on top of PagedAttention that operates at the request level (batches according to request arrival) and handles the virtual and physical KV cache for a variety of common decoding methods on single and distributed hardware.
Sarathi-serve (Agrawal et al., 2024). Prefilling (high latency, high GPU utilization) and decoding (low latency, low GPU utilization) are difficult to schedule together, but serving systems will often having many concurrent requests at either stage. The authors observe that when optimizing for throughput or greedily scheduling prefills first, there is a tradeoff between the time-between-token (TBT) chunking prefills to interleave requests at a finer granularity and 2) interleaving ongoing decodes with other requests to prevent stalling ongoing requests. tldr;if you optimize too much for throughput, you’re inevitably going to make some requests really slow. Sarathi-serve tries to make sure no request gets stalled for too long while still maximizing throughput.
III.5.b: Fast decoding strategies
We have mentioned over and over again that many Transformer computations are memory-bound, and this is especially true for model inference. While we can increase inference throughput using the methods in the previous section, the latency is lower-bounded. A new research direction on fast decoding strategies has emerged to push this lower bound down.
Speculative decoding (Leviathan et al., 2022). The core idea is to sample tokens from a cheaper “draft” model $q(x_{<t})$, and use a cute probability trick to make sure the distribution we sample from is actually the large model $p(x_{<t})$Up until now I’ve tried to avoid writing out math because I always recommend reading the original paper if you’re more curious about the “why”, and in this case the original paper is really simple, so I think it’s much easier to just let the math speak.. The savings comes from the fact that we can actually sample multiple sequential tokens from $q(x_{<t})$ while simultaneously computing tokens and the actual distribution from $p(x_{<t})$. We can then perform rejection sampling based on the likelihood of the generated token, and choose up to the first token that was rejected. By using more compute resources, we can speed up decoding by up to how much faster the smaller model is than the larger model. This work was critical for future ideas on using smaller models for faster decoding.
Figure 37. The Medusa heads are small learnable projections that, like the draft models in speculative decoding, are allowed to generate sequences of tokens rather than just a single token. [Image Source]
Medusa: Multiple Decoding Heads (Cai et al., 2024). Instead of using a smaller draft model, which is hard to fit into the GPU memory hierarchy without being slow, Medusa uses multiple prediction heads (each head is just a FFN with a residual connection) at the last hidden state and a sparsely structured attention mask over the predictions (basically to make sure they only attend heads can’t attend to tokens they didn’t generate) which they call “tree attention”. Unlike speculative decoding, the authors argue that matching the original model distribution is unnecessary, as long as the outputs are “reasonable” (they define a rule based on truncated sampling).
Part N: Modern Day and Beyond
We are still in the era of scale. However, in my opinion (not necessarily shared by the community), I don’t find the recent results of “scaling” to be particularly impressive (e.g. in a lot of the domains like decision-making game environments, software engineering tasks, etc. LLMs are still pretty bad). A lot of the prior directions in Part III are still being tackled to this day, so this section will feel a bit all over the place. Here, I will list some interesting on-going threads without a strong answer.
N.1: What’s up with these superclusters?
I recently listened to this Dwarkesh podcast with Leopold Aschenbrenner where they talk in the beginning about the huge cost of building compute clusters that can support scaling model training. They talk about the natural progression of scaling these data centers beyond to 100K H100s, ~150 MW, and then to 1 GW, and beyond. GPT-4, for reference, was rumored to be trained on ≥20k A100s with 13T tokens, or roughly 2e25 FLOPS. It’s also been rumored recently that Microsoft wants to build a 100 billion dollar data center/supercluster for their AI applications.
Obviously we haven’t observed the ceiling of the “scale to model performance” relationship, but I’ve always been a bit irked by the rush to continue scaling to uncharted territory, where the superclusters in AI are finally surpassing the existing institutional superclusters. I get that it has been “working” for a few years, but in some sense it reached a level of performance that I don’t find particularly surprising. LLMs model the distribution of language in its data distribution quite well, and they “generalize” to novel tasks (what does generalization even mean? We can barely characterize the distribution we are feeding as training data so what we think is generalization could be trivial when the model optimizes with respect to the entire Internet). Even more concerning, how did we extrapolate to the idea that these newer models will be superintelligentI’m not claiming AI cannot be dangerous. In fact, existing AI applications are already dangerous in not-so-sci-fi-esque ways. I also am not denying that safety / doomsday preventative research is important. But for “scale-pilled” individuals, the argument for burning billions of dollars seems a bit weak. I wonder if there is some strong prior about the equations or models we’ve been using that people have been seeing., or even that much more useful for that matter? Why is a GPT-7 that much more useful than a GPT-4?
Remark. I’m genuinely just curious what the rationale is, and I wonder if someone has a good answer for me. I would love to see a supercluster get built because I think it’s cool, but realistically there’s a high probability that it turns out to be a massive waste of resources.
N.2: How much bigger are industry resources than academia?
So I graduated from Princeton this past May, and during my undergrad I was part of the Princeton NLP group — now rebranded as Princeton Language and Intelligence (PLI). At the tail end of my time there, it was announced that PLI had purchased 300 H100 GPUs, positioning itself as one of the largest academic clusters for deep learning. The only other comparable academic cluster is UT Austin’s 600 H100 cluster, which most research labs would love to have.
I got curious about these numbers, because Meta’s LLaMA 3.1 family was reportedly trained on16k GPUs on their 24k GPU cluster (I wonder what kind of monstrous network topology they’ve built…) — in this blog, they estimate training to take ~100 days on this cluster (not sure how accurate this estimate is but this ballpark seems somewhat reasonable given the FLOPs range). And this is just on Meta’s LLaMA team — I’m sure they have more compute spread out across the company. In other words, my academic lab doesn’t seem so grand in comparison. That’s not to say that you cannot do good research in academia, but it is pretty funny to me just how much more compute and money these industry labs have over some of the most prestigious academic labs in the world.
N.3: How fast can we train old models with modern techniques?
I’ve always been curious how fast we can train older algorithms on new hardware with all the new fancy tricks we’ve learned throughout the years. Here is a thread of some interesting works in this direction.
Figure 38. Comparison of convergence rates of different iterations of GPT-2, plot taken from [https://github.com/KellerJordan/modded-nanogpt](https://github.com/KellerJordan/modded-nanogpt)
llm.c to speedrunning NanoGPT (Keller Jordan, 2024 - ).
Andrej Karpathy’s super efficient implementation of GPT-2 (124M parameters) called llm.c achieves a validation loss of 3.28 on FineWeb in 45 minutes on an 8xH100. This feat was further pushed by an ongoing Twitter thread on applying modern training techniques to tweak the NanoGPT model to converge faster.
The original thread adding rotary embeddings and an increasing LR. 31.4 min.
Using new muon optimizer, although I don’t fully understand the intuition or what exactly it does (some kind of fast orthogonalization trick applied to the Nesterov momentum update). It does use less memory than AdamW though and is slightly faster! 24.9 min.
The rest of the changes are in the repo/on Twitter, but it’s of the flavor of 1) tuning muon, 2) tweaking activations and layers 3) hardware-aware tricks. Current record: 12.03 min.
Pre-training BERT for under $20 (Mosaic AI, 2024). I really like this blog, as it showcases how far we’ve come in deep learning efficiency. BERT and RoBERTa were some of my first introductions to the field of deep learning, and they were known at the time to be some of the biggest training jobs, costing upwards of $300 and taking >4 days on 16 TPUs! They use a suite of tricks like FlashAttention, ALiBi, and unpadding, as well as the popular C4 corpus for pre-training. Basically, this paper takes the original BERT model and trains it entirely differently while using modern hardware and libraries, and it turns out to work extremely well. I’m excited to see how fast we can train LLaMA 3.1 405B in the future!
N.4: Recent efforts to scale hybrid or non-Transformer.
I sort of briefly mentioned alternatives to Transformers like SSMs and relevant algorithms like FlashFFTConv that are used to accelerate them. Given the existing constraints of Transformers and the attention mechanism, I wanted to discuss some alternatives and roughly why people have been interested in them.
Transformer-SSM Hybrids (e.g. Jamba, Striped Hyena). These models attempt to combine SSM blocks with Transformer blocks to improve long context reasoning capabilities. These models are still in the early stages of research without a key production-level model, but I wouldn’t be surprised if something interesting emerged from them in the future.
RWKW. An open-source effort (led by BlinkDL) to build an RNN that can be trained with parallel algorithms like a Transformer while maintaining constant memory / compute complexity during inference.
RetNet (Sun et al., 2023). Reformulating the attention mechanism with a recurrent formulating to get the benefits of a Transformer-like architecture with constant compute complexity during inference. It aims for similar guarantees to RWKV but the approach is entirely different.
Linearizing Transformers (e.g. Distilling Transformers into RNNs, Linearizing LLaMA 3). These methods attempt to take pre-trained Transformers and somehow distill or convert them into a different model with better inference-time guarantees. Unfortunately, the performance hit seems to be pretty significant in a lot of these.
N.5: Model efficiency Benchmarks
We have a lot of benchmarks for evaluating model performance, but not as many for evaluating efficiency. The most comprehensive benchmark available is the MLPerf benchmarks, which features inference, training, and HPC tasks across a wide range of modalities. In most instances, we can directly just compare algorithms on specific hardware, but I would be interested in more rigorous benchmarking in the future.
N.6: Startups in the Efficient Deep Learning Space
I have no affiliation to any of these startups — I just came across these at some point in the last year and felt they were interesting enough to save in my Notes app. I have no way of verifying if the work they’re doing is legit or even useful, so take it all with a grain of salt.
Etched. An ASIC specialized for Transformers. At the time of writing, little information is known about their chip.
Cerebras. Develop specialized chips for AI applications, with gimmicks like lots of on-device memory and super-fast inference for large models.
Together.ai. They’re pretty well known for their open-source work and research on fast inference methods and Transformer-SSM hybrids, but they also have a cloud platform for fine-tuning and using a wide variety of large models.
Groq. An ASIC specialized for language (basically big model) AI applications. They remove a lot of the complexity with CUDA’s hierarchy, and instead focus on being super low-latency and energy efficient. As far as I understand, they’ve mostly been used for model inference, like a lot of the other ASICs mentioned.
Tenstorrent. They develop a lot of custom hardware from chips to workstations specifically for AI applications. From what I can tell, they’re trying to build out a whole CUDA-like ecosystem, but I’m guessing they’ll need some kind of breakthrough performance to attract more interest.
Resources
A.1: Where to access “free” GPUs?
There are plenty of services like Amazon AWS, Google GCP, Microsoft Azure, etc. that offer cloud GPUs, but if you’re not rich like me, you may also be interested in what free options are currently availableGradient by Paperspace used to be my go-to, but I can’t seem to find what happened to it..
Google Colab. You can get access to a free Tesla T4 16GB when using their notebooks, but the time limits are not consistent and you’ll have to use multiple emails to get consistent usage.
Lightning.ai. You get 22 free GPU hours every month without needing to put in a credit card, and you also get a vscode-like interface so you can just plop in your codebase and run what you need.
Kaggle. Kaggle gives access to free NVIDIA K80s with a weekly limit. I’m not sure what it is anymore, but it used to be 30 hours/week.
A.2: Large training and finetuning frameworks.
There are many options for handling large-scale training jobs other than PyTorch/TensorFlow’s in-house wrappers and distributed modules. A lot of these examples use config files or YAML file configurations for defining your desired job. We list some useful libraries below.
torchtune. Torchtune is PyTorch’s newest module for fine-tuning large language models. They’ve heavily modularized their code and have some nice recent examples with LLaMA 3.
HuggingFace PEFT. PEFT integrates most of the existing parameter-efficient fine tuning (recall from III.1.c) methods to work with models loaded from the Huggingface transformers library.
accelerate. A super-thin wrapper around your PyTorch models, dataloader, and optimizer for launching multi-GPU jobs without a lot of extra code.
deepspeed. A library around PyTorch for reducing multi-GPU workloads automatically. It notably integrates ZeRO optimizations, and works really well with / similarly to accelerate.
axolotl. A fine-tuning library that sits on top of libraries like deepspeed and accelerate. It’s basically like a code-free tool and works entirely in config files and the CLI.
A.3: Model compression frameworks.
A lot of model inference libraries like TensorRT do auto-tuned quantization under the hood, but for research purposes, there are other frameworks where you have better control over the weight / activation quantization.
torch.ao.quantization(2022). Quantization used to be quite annoying to implement because it modifies how we represent our data in memory. The PyTorch team has done a lot of work
bitsandbytes(2023). A wrapper around your optimizers that allows you to use llm.int8() and Q-LoRA. It works very well with HuggingFace and PyTorch.
TensorRT Model Optimizer. This library is like an intermediate step between converting from PyTorch / ONNX and TensorRT. It runs a bunch of optimizations like pruning, quantization, and distillation to your model to prepare it for inference, but it works at the computational graph level.
A.4: Profiling Tools.
For any kind of efficient deep learning work, it is always important to profile your models at all levels of the compute hierarchy. Check out the GPU Mode lecture on profiling, which is a nice introduction to profiling in PyTorch, Triton, and CUDA. Here, we provide some useful tools for profiling your code.
nvitop. You can always just use nvidia-smi to view the memory / power usage of your GPUs, but there are some cool alternatives that are prettier and more customizable. I pretty much use nvitop as an nvidia-smi replacement, but there are a lot of other features they have in their GitHub that you can play with.
Pytorch Profiler. PyTorch has a simple profiler that you can wrap around your code for viewing the individual kernels / CPU calls. It also has peak memory usage / compute time statistics that it prints out for you, and is relatively simple to insert into your code for debugging.
Nsight Compute and the Nsight Compute CLI (ncu) are excellent profiling tools for your CUDA kernels. It provides analysis on potential bottlenecks, as well thread, memory, and kernel call information at a very fine granularity. It also provides thorough analysis and recommendations for fixing bottlenecks in your kernels.
Nsight Systems is designed for profiling entire workloads (CPU, GPU), and is more similar to the PyTorch profiler tool.
A.5: “From scratch”-style tutorials.
It was always nice to get your hands dirty when learning a new topic. The machine learning community has made a lot of nice libraries for practitioners to use that lets you load and use a powerful LLM with a few lines of code. However, because the field moves so fast, it is a valuable skill to know what’s going on under the hood. Here, we list many useful resources for learning from the ground up (many of which come from Andrej Karpathy).
Karpathy’s Neural Networks: Zero to Hero Playlist. Probably one of the most information-dense tutorials for how LLMs are coded from the ground up. I find his teaching style quite fun, and I think these are worth following in your free time.
Programming Massively Parallel Processors Lectures. The PMPP book is one of the most iconic for understanding common GPU programming primitives. The lectures are from one of the authors, and they’re extremely well-made. Most of the examples are in CUDA, which is perfect for getting into efficient deep learning.
PyTorch internals. I’m not sure how much PyTorch has changed since this blog came out (there’s slides out there for PyTorch 2.0), but this blog has a lot of nice visuals that explains how PyTorch implements tensors, autodifferentiation, and kernel dispatches.
Optimizing CUDA Matmul from Scratch. I love this blog — the goal is to get to CuBLAS-level performance with raw CUDA, and they use a lot of the tricks and primitives you learn from the PMPP book. I found this blog to be one of the most helpful hands-on tutorials for getting started with CUDA.
Colfax CUTLASS. Colfax has a bunch of nice blogs on GPUs, but their CUTLASS GEMM series is extremely new and well-made. This resource is probably the most up-to-date out of the ones listed so far.
Han Song’s Efficient ML Lectures. Professor Han Song is one of the leading figures in efficient ML, and his course is freely available on YouTube. I watched the 2023 iteration of the course, but a lot of the topics center around his research which is pretty cool!
A.6: Designing deep learning clusters and network topology.
We can design all the algorithms we want for working with multiple nodes, but if our cluster is poorly designed, we are strictly bottlenecked by speed. Ideally, we would want every device and node to share the same pair-wise communication latency, but in practice this is almost impossible.
NVIDIA DGX servers. NVIDIA has packaged up their GPUs nicely into these super expensive multi-GPU servers that you can plug into your cluster. They handle stuff like optimizing the inter-GPU interconnects and attaching a host processor for youA lot more details about each generation of these servers can be found here: https://training.continuumlabs.ai/infrastructure/servers-and-chips/nvidia-dgx-2. While researching this topic (e.g. when someone says they’re using a 8xH100, what else is there other than the H100s), I came across a bunch of other bundled up servers like Arc Compute and Lambda Hyperplane from third-party distributors.
Network topology. I heard this work thrown around a lot, and it sort of confused me what the relation was to say point-set topology. But network topology is literally the physical connections between nodes and devices within a cluster. Unfortunately, I know little about the design decisions here other than something of the form “node A has a limited number of lanes/ports, so we can’t just jam all the nodes together”. I hope to expand this section and add it to Part III!
A.7: Useful surveys on efficiency.
Part of the difficulty of research in this field is sifting through the sheer number of different papers. This post hopefully serves as a strong filter for many of these works, but perhaps for some readers it is too strong of a filter. Below, I list some comprehensive surveys to find more interesting works related to efficiency.
Lil’log. (https://lilianweng.github.io/). Just the absolute GOAT with lots of topics on deep learning in general.
Acknowledgements
I am open to suggestions and edits, even those that are critical. I want to log these edits and changes made over time in this section to give credit where credit is due!
Eddy Wu for finding typos in the quantization and sparsity sections.
Citation
Just as a formality, if you want to cite this for whatever reason, use the BibTeX below.
@article{zhang2024efficientdl,
title = "A Meticulous Guide to Advances in Deep Learning Efficiency over the Years",
author = "Zhang, Alex",
year = "2024",
month = "October",
url = "https://alexzhang13.github.io/blog/2024/efficient-dl/"
}
]]>Alex ZhangThe Annotated Kolmogorov-Arnold Network (KAN)2024-07-01T00:00:00+00:002024-07-01T00:00:00+00:00https://alexzhang13.github.io/blog/2024/annotated-kanif the LaTeX is not loading, refresh the page.
This post is analogous to and heavily inspired by the Annotated Transformer but for KANs. It is fully functional as a standalone notebook, and provides intuition along with the code. Most of the code was written to be easy to follow and to mimic the structure of a standard deep learning model in PyTorch, but some parts like training loops and visualization code were adapted from the original codebase. We decided to remove some sections from the original paper that were deemed unimportant, and also includes some extra works to motivate future research on these models.
The original paper is titled “KAN: Kolmogorov-Arnold Networks”, and the authors on this paper are: Ziming Liu, Yixuan Wang, Sachin Vaidya, Fabian Ruehle, James Halverson, Marin Soljačić, Thomas Y. Hou, and Max Tegmark.
Introduction
Deep neural networks have been the driving force of developments in AI in the last decade. However, they currently suffer from several known issues such as a lack of interpretability, scaling issues, and data inefficiency – in other words, while they are powerful, they are not a perfect solution.
Kolmogorov-Arnold Networks (KANs) are an alternative representation to standard multi-layer perceptrons (MLPs). In short, they parameterize activation functions by re-wiring the “multiplication” in an MLP’s weight matrix-vector multiplication into function application. While KANs are not nearly as provably accomplished as MLPs, they are an exciting prospect for the field of AI and deserve some time for exploration.
I have separated this article into two sections. Parts I & II describe a minimal KAN architecture and training loop without an emphasis on B-spline optimizations. You can use the minimal KAN notebook if you’re interested in KANs at a high-level. Parts III & IV describe B-spline specific optimizations and an application of KANs, which includes a bit of extra machinery in the KAN code. You can use the full KAN notebook if you want to follow along there.
Background and Motivation
Before jumping into the implementation details, it is important to take a step back and understand why one should even care about these models. It is quite well known that Multi-layer Perceptrons (MLPs) have the “Universal Approximation Theorem”, which provides a theoretical guarantee for the existence of an MLP that can approximate any functionThis is a very strong guarantee that usually isn't actually true. Generally, we have some provable guarantee for a class of functions that we actually care about approximating, like say the set of functions in L1 or the set of smooth, continuous functions. up to some error \(\epsilon\). While this guarantee is important, in practice, it says nothing about how difficult it is to find such an MLP through, say, optimization with stochastic gradient descent.
KANs admit a similar guarantee through the Kolmogorov-Arnold representation theorem, though with a caveatSee section [Are Stacked KAN Layers a Universal Approximator?]. Formally, the theorem states that for a set of covariates \((x_1,x_2,...,x_n)\), we can write any continuous, smoothSmooth in this context means in $C^{\infty}$, or infinitely differentiable. function \(f(x_1,...,x_n) : \mathcal{D} \rightarrow \mathbb{R}\) over a bounded domain \(\mathcal{D}\)Because it is bounded, the authors argue that we can normalize the input to the space $[0,1]^{n}$, which is what is assumed in the original paper. in the form
where \(\Phi_{q,p}, \Phi_{q}\) are univariate functions from \(\mathbb{R}\) to \(\mathbb{R}\). In theory, we can parameterize and learn these (potentially non-smooth and highly irregular) univariate functions \(\Phi_{q,p}, \Phi_{q}\) by optimizing a loss function similar to any other deep learning model. But it’s not that obvious how one would “parameterize” a function the same way you would parameterize a weight matrix. For now, just assume that it is possible to parameterize these functions – the original authors choose to use a B-spline, but there is little reason to be stuck on this choice.
What is a KAN?
The expression from the theorem above does not describe a KAN with $L$ layers. This was an initial point of confusion for me. The universal approximation guarantee is only for models specifically in the form of the Kolmogorov-Arnold representation, but currently we have no notion of a “layer” or anything scalable. In fact, the number of parameters in the above theorem is a function of the number of covariates and not the choice of the engineer! Instead, the authors define a KAN layer \(\mathcal{K}_{m,n}\) with input dimension \(n\) and output dimension \(m\) as a parameterized matrix of univariate functions, \(\Phi = \{\Phi_{i,j}\}_{i \in [m], j \in [n]}\).
It may seem like the authors pulled this expression out of nowhere, but it is easy to see that the KAN representation theorem can be re-written as follows. For a set of covariates \(\boldsymbol{x} = (x_1,x_2,...,x_n)\), we can write any continuous, smooth function \(f(x_1,...,x_n) : \mathcal{D} \rightarrow \mathbb{R}\) over a bounded domain \(\mathcal{D}\) in the form
The KAN architecture, is therefore written as a composition of stacking these KAN layers, similar to how you would compose an MLP. I want to emphasize that unless the KAN is written in the form above, there is currently no provenI suspect that there are some provable guarantees that can be made for deep KANs. The original universal approximation theorem for MLPs refers to models with a single hidden dimension, but later works have also derived guarantees for deep MLPs. We also technically don't have very strong provable guarantees for mechanisms like self-attention (not to my knowledge at least), so I don't think it's that important in predicting the usefulness of KANs. theoretical guarantee that there exists a KAN represents that approximates the desired function.
Are Stacked KAN Layers a Universal Approximator?
When first hearing about KANs, I was under the impression that the Kolmogorov-Arnold Representation Theorem was an analogous guarantee for KANs, but this is seemingly not true. Recall from the Kolmogorov-Arnold representation theorem that our guarantee is only for specific 2-layer KAN models. Instead, the authors prove that there exists a KAN using B-splines as the univariate functions \(\{\Phi_{i,j}\}_{i \in [m], j \in [n]}\) that can approximate a composition of continuously-differentiable functions within some nice error marginThis article serves mainly as a concept to code guide, so I didn't want to dive too much into theory. The error bound that the authors prove is quite strange, as the constant $C$ is not *really* a constant in the traditional sense (it depends on the function you are approximating). Also, the function family they choose to approximate seems pretty general, but I'm actually not that sure what types of functions it cannot represent well. I'd recommend reading Theorem 2.1 on your own, but it mainly serves as justification for the paper's use of B-splines rather than a universal approximation theorem for generic KAN networks. . Their primary guarantees are proven to justify the use of B-splines as their learnable activations, but other works have recently sprung up that propose different learnable activations like Chebyshev polynomials, RBFs , and wavelet functions .
tldr; no, we have not shown that a generic KAN model serves as the same type of universal approximator as an MLP (yet).
Polynomials, Splines, and B-Splines
We talked quite extensively about “learnable activation functions”, but this notion might be unclear to some readers. In order to parameterize a function, we have to define some kind of “base” function that uses coefficients. When learning the function, we are actually learning the coefficients. The original Kolmogorov-Arnold representation theorem places no conditions on the family of learnable univariate activation functions. Ideally, we would want some kind of parameterized family of functions that can approximate any function, whether it be non-smooth, fractal, or some other kind of nasty property on a bounded domainNot only is the original KAN representation theorem over a bounded domain, but generally in most practical applications we are not dealing with data over an unbounded domain..
Enter the B-spline. B-splines are a generalization of spline functions, which themselves are piecewise polynomials. Polynomials of degree/order \(k\) are written as \(p(x) = a_0 + a_1x + a_2x^2 + ... + a_kx^k\) and can be parameterized according to their coefficients \(a_0,a_1,...,a_k\). From the Stone-Weierstrass theorem , we can guarantee that every continuous function over a bounded domain can be approximated by a polynomial. Splines, and by extension B-splines, extend this guarantee to more complicated functions over a bounded domain. I don’t want to take away from the focus on KANs, so for more background I’d recommend reading this resource.
Rather than be chunked explicitly like a spline, B-spline functions are written as a sum of basis functions of the form
where \(G\) denotes the number of grid points and therefore basis functions (which we have not defined yet), $k$ is the order of the B-spline, and \(c_i\) are learnable parameters. Like a spline, a B-spline has a set of $G$ grid pointsThese are also called knots. B-splines are determined by control points, which are the data points we're trying to fit. Sometimes knots and control points can be the same, but generally knots are fixed beforehand and can be adjusted. \((t_1,t_2,...,t_G)\). In the KAN paper, they augment these points to \((t_{-k}, t_{-k+1},...,t_{G+k-1},t_{G+k})\) to account for the order of the B-spline Read https://web.mit.edu/hyperbook/Patrikalakis-Maekawa-Cho/node17.html for a better explanation for why you need to do this. It is mainly so the basis functions are well defined. to give us an augmented grid size of \(G+2k\). The simplest definition for the grid points is to uniformly divide the bounded domain into $G$ equally spaced points – from our definition of the basis functions, you will see that the augmented points just need to be at the ends. The Cox-de Boor formula characterizes these basis functions recursively as follows:
We can plot an example for the basis functions of a B-spline with $G=5$ grid points of order $k=3$. In other words, the augmented grid size is $G+2k=11$:
Matplotlib plot of B-spline basis functions. Notably, the basis functions, like spline polynomials, are $0$ on most of the domain. But they overlap, unlike for splines. I generated this graph by adapting code from https://github.com/johntfoster/bspline/.
When implementing B-splines for our KAN, we are not interested in the function \(f(\cdot)\) itself, rather we care about efficiently computing the function evaluated at a point \(f(x)\). We will later see a nice iterative bottom-up dynamic programming formulation of the Cox-de Boor recursion.
Part I: The Minimal KAN Model Architecture
In this section, we describe a barebones, minimal KAN model. The goal is to show that the architecture is structured quite similarly to deep learning code that the reader has most likely seen in the past. To summarize the components, we modularize our code into (1) a high-level KAN module, (2) the KAN layer, (3) the parameter initialization scheme, and (4) the plotting function for interpreting the model activations.
Preliminaries
If you’re using Colab, you can run the following as if they were code blocks. This implementation is also quite GPU-unfriendly, so a CPU will suffice.
# Code was written in Python 3.11.9, but most usable versions of Python and torch suffice.
!pip install torch==2.3.1
!pip install numpy==1.26.4
!pip install matplotlib==3.9.0
!pip install tqdm==4.66.4
!pip install torchvision==0.18.1
In an attempt to make this code barebones, I’ve tried to use as little dependencies as possible. I’ve also included type annotations for the code.
# Python libraries
import os
from typing import List, Dict, Optional, Self
import random
import warnings
# Installed libraries
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import datasets, transforms
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdm
The following config file holds some preset hyperparameters described in the paper. Most of these can be changed and may not even apply to a more generic KAN architecture.
class KANConfig:
"""
Configuration struct to define a standard KAN.
"""
residual_std = 0.1
grid_size = 5
spline_order = 3
grid_range = [-1.0, 1.0]
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
The KAN Architecture Skeleton
If you understand how MLPs work, then the following architecture should look familiar. As always, given some set of input features \((x_1,...,x_n)\) and a desired output \((y_1,...,y_m)\), we can think of our KAN as a function \(f : \mathbb{R}^{n} \rightarrow \mathbb{R}^{m}\) parameterized by weights \(\theta\). Like any other deep learning model, we can decompose KANs in a layer-wise fashion and offload the computational details to the layer class. We will fully describe our model in terms of a list of integers layer_widths, where the first number denotes the input dimension \(n\), and the last number denotes the output dimension \(m\).
class KAN(nn.Module):
"""
Standard architecture for Kolmogorov-Arnold Networks described in the original paper.
Layers are defined via a list of layer widths.
This minimal implementation doesn't include optimizations used specifically
for B-splines.
"""
def __init__(
self,
layer_widths: List[int],
config: KANConfig,
):
super(KAN, self).__init__()
self.layers = torch.nn.ModuleList()
self.layer_widths = layer_widths
# If layer_widths is [2,4,5,1], the layer
# inputs are [2,4,5] and the outputs are [4,5,1]
in_widths = layer_widths[:-1]
out_widths = layer_widths[1:]
for in_dim, out_dim in zip(in_widths, out_widths):
self.layers.append(
KANLayer(
in_dim=in_dim,
out_dim=out_dim,
grid_size=config.grid_size,
spline_order=config.spline_order,
device=config.device,
residual_std=config.residual_std,
grid_range=config.grid_range,
)
)
def forward(self, x: torch.Tensor):
"""
Standard forward pass sequentially across each layer.
"""
for layer in self.layers:
x = layer(x)
return x
The KAN Representation Layer
The representation used at each layer is quite intuitive. For an input \(x \in \mathbb{R}^{n}\), we can directly compare a standard MLP layer with output dimension \(m\) to an equivalent KAN layer:
$$
\begin{aligned}
h_{MLP} = \sigma (W \boldsymbol{x} + b) \quad \quad &\text{ where } \quad \quad \forall i \in [m], (W\boldsymbol{x})_{i} = \sum_{k=1}^n W_{i,k} x_k
\\
h_{KAN} = \Phi \boldsymbol{x} + b \quad \quad &\text{ where } \quad \quad \forall i \in [m], (\Phi \boldsymbol{x})_{i} = \sum_{k=1}^n \Phi_{i,k} (x_k)
\end{aligned}
$$
In other words, both layers can be written in terms of a generalized matrix-vector operation, where for an MLP it is scalar multiplication, while for a KAN it is some learnable non-linear function \(\Phi_{i,k}\). Interestingly, both layers look extremely similar! Remark. As a GPU enthusiast, I should mention that while these two expressions look quite similar, this minor difference can have a huge impact on efficiency. Having the same instruction (e.g. multiplication) applied to every operation fits well within the warp abstraction used in writing CUDA kernels, while having a different function application per operation has many issues like control divergence that significantly slow down performance.
Let’s think through how we would perform this computation. For our analysis, we will ignore the batch dimension, as generally this is an easy extension. Suppose we have a KAN layer \(\mathcal{K}_{m,n}\) with input dimension\(n\) and output dimension \(m\). As we discussed earlier, for input \((x_1,x_2,...,x_n)\),
The observant reader may notice that this looks exactly like the $Wx$ matrix used in an MLP. In other words, we have to compute and materializeFor convenience sake, we will materialize the matrix of values below all at once. I suspect that, similar to matrix multiplication, there may be a way to avoid materializing the full matrix all at once, but this requires a clever choice of the family of functions for $\Phi$. each term in the matrix below, then sum along the rows.
$$
\text{The terms we need to compute are }
\begin{bmatrix}
\Phi_{1,1}(x_1), \Phi_{1,2}(x_2), ..., \Phi_{1,n}(x_n) \\
\Phi_{2,1}(x_1), \Phi_{2,2}(x_2), ...,\Phi_{2,n}(x_n) \\
\vdots \\
\Phi_{m,1}(x_1), \Phi_{m,2}(x_2), ..., \Phi_{m,n}(x_n) \\
\end{bmatrix}
$$
To finish off the abstract KAN layer (remember, we haven’t defined what the learnable activation function is), the authors define each learnable activation function $\Phi_{i,j}(\cdot)$ as a function of a learnable activation function $s_{i,j}(\cdot)$ to add residual connections in the network:
We can modularize the operation above into a “weighted residual layer” that acts over a matrix of \((\text{out_dim}, \text{in_dim})\) values. This layer is parameterized by each \(w^{(b)}_{i,j}\) and \(w^{(s)}_{i,j}\), so we can store \(\boldsymbol{w}^{(b)}\) and \(\boldsymbol{w}^{(s)}\) as parameterized weight matrices. The paper also specifies the initialization scheme of \(w^{(b)}_{i,j} \sim \mathcal{N}(0, 0.1)\) and \(w^{(s)}_{i,j} = 1\).For all the code comments below, I notate `bsz` as the batch size. Generally, this is just an extra dimension that can be ignored during the analysis.
class WeightedResidualLayer(nn.Module):
"""
Defines the activation function used in the paper,
phi(x) = w_b SiLU(x) + w_s B_spline(x)
as a layer.
"""
def __init__(
self,
in_dim: int,
out_dim: int,
residual_std: float = 0.1,
):
super(WeightedResidualLayer, self).__init__()
self.univariate_weight = torch.nn.Parameter(
torch.Tensor(out_dim, in_dim)
) # w_s in paper
# Residual activation functions
self.residual_fn = F.silu
self.residual_weight = torch.nn.Parameter(
torch.Tensor(out_dim, in_dim)
) # w_b in paper
self._initialization(residual_std)
def _initialization(self, residual_std):
"""
Initialize each parameter according to the original paper.
"""
nn.init.normal_(self.residual_weight, mean=0.0, std=residual_std)
nn.init.ones_(self.univariate_weight)
def forward(self, x: torch.Tensor, post_acts: torch.Tensor):
"""
Given the input to a KAN layer and the activation (e.g. spline(x)),
compute a weighted residual.
x has shape (bsz, in_dim) and act has shape (bsz, out_dim, in_dim)
"""
# Broadcast the input along out_dim of post_acts
res = self.residual_weight * self.residual_fn(x[:, None, :])
act = self.univariate_weight * post_acts
return res + act
With these operations laid out in math, we have enough information to write a basic KAN layer by abstracting away the choice of learnable activation \(s_{i,j}(\cdot)\). Note that in the code below, the variables spline_order, grid_size, and grid_range are specific to B-splines as the activation, and are only passed through the constructor. You can ignore them for now. In summary, we will first compute the matrix
following by the weighted residual across each entry, then we will finally sum along the rows to get our layer output. We also define a cache() function to store the input vector \(\boldsymbol{x}\) and the \(\Phi \boldsymbol{x}\) matrix to compute regularization terms defined later.
class KANLayer(nn.Module):
"Defines a KAN layer from in_dim variables to out_dim variables."
def __init__(
self,
in_dim: int,
out_dim: int,
grid_size: int, # B-spline parameter
spline_order: int, # B-spline parameter
device: torch.device,
residual_std: float = 0.1,
grid_range: List[float] = [-1, 1], # B-spline parameter
):
super(KANLayer, self).__init__()
self.in_dim = in_dim
self.out_dim = out_dim
self.grid_size = grid_size
self.spline_order = spline_order
self.device = device
# Define univariate function (splines in original KAN)
self.activation_fn = KANActivation(
in_dim,
out_dim,
spline_order,
grid_size,
device,
grid_range,
)
# Define the residual connection layer used to compute \phi
self.residual_layer = WeightedResidualLayer(in_dim, out_dim, residual_std)
# Cache for regularization
self.inp = torch.empty(0)
self.activations = torch.empty(0)
def cache(self, inp: torch.Tensor, acts: torch.Tensor):
self.inp = inp
self.activations = acts
def forward(self, x: torch.Tensor):
"""
Forward pass of KAN. x is expected to be of shape (bsz, in_dim) where in_dim
is the number of input scalars and the output is of shape (bsz, out_dim).
"""
# Compute each s_{i,j}, shape: [bsz x out_dim x in_dim]
spline = self.activation_fn(x)
# Form the batch of matrices phi(x) of shape [bsz x out_dim x in_dim]
phi = self.residual_layer(x, spline)
# Cache activations for regularization during training.
self.cache(x, phi)
# Really inefficient matmul
out = torch.sum(phi, dim=-1)
return out
KAN Learnable Activations: B-Splines
Recall from the section on B-splines that each activation $s_{i,j}(\cdot)$ is a sum of productsWe can equivalently think of this as a dot product between two vectors $\langle c_{i,j}, B_{i,j} (x_j) \rangle$. of $G + k$ learnable coefficients and basis functions \(\sum_{h=1}^{G} c^{h}_{i,j}, B^h_{i,j} (x_j)\) where $G$ is the grid size. The recursive definition of the B-spline basis functions requires us to define the grid points $(t_1,t_2,…,t_G)$, as well as the augmented grid points \((t_{-k},t_{-k+1},...,t_{-1},t_{G+1},....,t_{G+k})\)In the original paper, you may have noticed a G + k - 1 term. I don't define $t_0$ here, and opt to not include it for indexing sake, but you can basically just shift everything by $1$ to achieve the same effect.. For now, we will define them to be the endpoints of $G+1$ equally-sized intervals on the bounded interval [low_bound, up_bound]I mentioned this earlier, but you may notice that the augmented grid points go out of the bounded domain. This is just for convenience, but as long as they are at the bounds or outside them in the right direction, it doesn't matter what they are. You can also just set them to be the boundary points. but you can also choose / learn the grid point positions. Finally, we note that we need to use the grid points in the calculation of each activation $s_{i,j}(x)$, so we broadcast into a 3D tensor.
def generate_control_points(
low_bound: float,
up_bound: float,
in_dim: int,
out_dim: int,
spline_order: int,
grid_size: int,
device: torch.device,
):
"""
Generate a vector of {grid_size} equally spaced points in the interval
[low_bound, up_bound] and broadcast (out_dim, in_dim) copies.
To account for B-splines of order k, using the same spacing, generate an additional
k points on each side of the interval. See 2.4 in original paper for details.
"""
# vector of size [grid_size + 2 * spline_order + 1]
spacing = (up_bound - low_bound) / grid_size
grid = torch.arange(-spline_order, grid_size + spline_order + 1, device=device)
grid = grid * spacing + low_bound
# [out_dim, in_dim, G + 2k + 1]
grid = grid[None, None, ...].expand(out_dim, in_dim, -1).contiguous()
return grid
Again recall the Cox-de Boor recurrence from before.
As a general rule of thumb we would like to avoid writing recurrent functions in the forward pass of a model. A common trick is to turn our recurrence into a dynamic-programming solution, which we make clear by writing in array notation:
The tricky part is writing this in tensor notationI'd recommend drawing this out yourself. It's quite hard to explain without visualizations, but quite simple to reason about. . We take advantage of broadcasting rules in PyTorch/Numpy to make copies of tensors when needed. Recall that to materialize our activation matrix \(\{s_{i,j}(x_j)\}_{i \in [m], j \in [n]}\) we need to compute the bases for each activation, i.e. \(\{B^{(i,j)}_{h,k} (x_j)\}_{h \in [G+k], i \in [m], j \in [n]}\).
The following explanation is a bit verbose, so bear with me. Our grid initialization function above generates a rank-3 tensor of shape (out_dim, in_dim, G+2k+1) while the input $x$ is a rank-2 tensor of shape (batch_size, in_dim). We first notice that our grid applies to every input in the batch, so we broadcast it to a rank-4 tensor of shape (batch_size, out_dim, in_dim, G+2k+1). For the input $x$, we similarly need a copy for every output dimension and every basis function to evaluate over, giving us the same shape through broadcasting. We can align the in_dim axis of both the grid and the input because $j$ aligns in $s_{i,j}(x_j)$. The $i$ indexes over the basis functions, or the last dimension of our tensors. We write out the vectorized DP in this form, as we note that we can fix $j$. Finally, we perform DP over our $j$ index based on the recurrence rule, yielding the B-spline basis functions evaluated on each input dimension to be used for each output dimension. This notation may be confusing, but the operation is actually quite simple – I would recommend ignoring the batch dimension and drawing out what you need to do.
tldr; we need to compute something for each element in a batch, for each activation, for each B-spline basis. we can use broadcasting to do this concisely, from the code below
# Helper functions for computing B splines over a grid
def compute_bspline(x: torch.Tensor, grid: torch.Tensor, k: int, device: torch.device):
"""
For a given grid with G_1 intervals and spline order k, we *recursively* compute
and evaluate each B_n(x_{ij}). x is a (batch_size, in_dim) and grid is a
(out_dim, in_dim, # grid points + 2k + 1)
Returns a (batch_size, out_dim, in_dim, grid_size + k) intermediate tensor to
compute sum_i {c_i B_i(x)} with.
"""
grid = grid[None, :, :, :].to(device)
x = x[:, None, :, None].to(device)
# Base case: B_{i,0}(x) = 1 if (grid_i <= x <= grid_{i+k}) 0 otherwise
bases = (x >= grid[:, :, :, :-1]) * (x < grid[:, :, :, 1:])
# Recurse over spline order j, vectorize over basis function i
for j in range (1, k + 1):
n = grid.size(-1) - (j + 1)
b1 = ((x[:, :, :, :] - grid[:, :, :, :n]) / (grid[:, :, :, j:-1] - grid[:, :, :, :n]))
b1 = b1 * bases[:, :, :, :-1]
b2 = ((grid[:, :, :, j+1:] - x[:, :, :, :]) / (grid[:, :, :, j+1:] - grid[:, :, :, 1:n+1]))
b2 = b2 * bases[:, :, :, 1:]
bases = b1 + b2
return bases
Computing the B-Spline Activations
With the B-spline logic out of the way, we have all of our intermediate computation logic done. We still have to define our parameters \(c_i\) and compute the B-splines from the basis functions, but this is just a simple element-wise multiplication and sum. We can now pass the B-spline output into the weighted residual layer defined earlier and compute our output vector. In summary, we are computing
class KANActivation(nn.Module):
"""
Defines a KAN Activation layer that computes the spline(x) logic
described in the original paper.
"""
def __init__(
self,
in_dim: int,
out_dim: int,
spline_order: int,
grid_size: int,
device: torch.device,
grid_range: List[float],
):
super(KANActivation, self).__init__()
self.in_dim = in_dim
self.out_dim = out_dim
self.spline_order = spline_order
self.grid_size = grid_size
self.device = device
self.grid_range = grid_range
# Generate (out, in) copies of equally spaced control points on [a, b]
grid = generate_control_points(
grid_range[0],
grid_range[1],
in_dim,
out_dim,
spline_order,
grid_size,
device,
)
self.register_buffer("grid", grid)
# Define the univariate B-spline function
self.univarate_fn = compute_bspline
# Spline parameters
self.coef = torch.nn.Parameter(
torch.Tensor(out_dim, in_dim, grid_size + spline_order)
)
self._initialization()
def _initialization(self):
"""
Initialize each parameter according to the original paper.
"""
nn.init.xavier_normal_(self.coef)
def forward(self, x: torch.Tensor):
"""
Compute and evaluate the learnable activation functions
applied to a batch of inputs of size in_dim each.
"""
# [bsz x in_dim] to [bsz x out_dim x in_dim x (grid_size + spline_order)]
bases = self.univarate_fn(x, self.grid, self.spline_order, self.device)
# [bsz x out_dim x in_dim x (grid_size + spline_order)]
postacts = bases * self.coef[None, ...]
# [bsz x out_dim x in_dim] to [bsz x out_dim]
spline = torch.sum(postacts, dim=-1)
return spline
If you’ve gotten to this point, congratulations! You’ve read through the hardest and most important part of this article. The rest of this post talks about a generic model training loop, visualization functions, and optimizations that can be made to B-spline specific KANs. If you’re interested in future directions for these models, I’d recommend reading into Awesome-KAN and getting started! Otherwise, if you’d like to have a deeper understanding of the original KAN paper, keep reading!
Sparsity through Regularization
Rather unsurprisingly, regularization is an important component of KANs. The authors of KAN motivate two types of regularization – L1 regularization to limit the number of active activation functions, and entropy regularization to penalize duplicate activation functions.
L1 regularization for a weight matrix \(W\) in an MLP is straightforward – just take the Frobenius norm of the matrix. However, for activation functions, using the parameters of the function are not necessarily a good choice. Instead, the magnitude of the function evaluated on the data is used. More formally, suppose we have a batch of inputs \(\{x^{(b)}_1,...,x^{(b)}_n \}_{b \in \mathcal{B}}\) into a KAN layer $\mathcal{K}_{m,n}$. The L1 norm of an activation from input node $j$ to output node $i$ is defined as the absolute value of the mean of that activation on $x_j$, averaged over the batch. In other words,
def l1_regularization(model: KAN):
"""
Compute L1 regularization of activations by using
cached activations. Must be called after KAN forward pass
during training.
"""
reg = torch.tensor(0.)
# regularize coefficient to encourage spline to be zero
for i in range(len(model.layers)):
acts = model.layers[i].activations
l1_activations = torch.sum(torch.mean(torch.abs(acts), dim=0))
reg += l1_activations
return reg
In addition to wanting sparse activations for better interpretability and performanceIn our implementation, sparsification does not yield performance benefits because we do not take advantage of any kind of efficient sparse kernels, at least not explicitly. While this post is mainly designed to be readable, an efficient implementation of KANs is very important for attempts to scale these models., we generally want to ensure we do not have duplicate activation functions. Another form of regularization is naturally entropy, which is defined as
def entropy_regularization(model: KAN):
"""
Compute entropy regularization of activations by using
cached activations. Must be called after KAN forward pass
during training.
"""
reg = torch.tensor(0.)
eps = 1e-4
# regularize coefficient to encourage spline to be zero
for i in range(len(model.layers)):
acts = model.layers[i].activations
l1_activations = torch.sum(torch.mean(torch.abs(acts), dim=0))
activations = (
torch.mean(torch.abs(l1_activations), dim=0)
/ l1_activations
)
entropy = -torch.sum(activations * torch.log(activations + eps))
reg += entropy
return reg
The regularization term is just a weighted sum of the two terms above. These regularization expressions are not specific to the B-splines representation chosen by the authors, but their effect on other choices of learnable activation functions is underexplored at the moment.
def regularization(
model: KAN,
l1_factor: float = 1,
entropy_factor: float = 1,
):
"""
Regularization described in the original KAN paper. Involves an L1
and an entropy factor.
"""
return l1_factor * l1_regularization(model) + \
entropy_factor * entropy_regularization(model)
Part II: Model Training
In this section, we will discuss the basic training loop for a KAN, including a script for visualizing the network activations. As you will notice, the framework for training a KAN is almost identical to a standard deep learning train loop.
Training Loop
Despite the extra machinery necessary to apply our model parameters to our input, it is easy to see that the operations themselves are differentiable. In other words, barring some extra optimization tricks that we will discuss in Part III, the training loop for KANs is basically just a generic deep learning train loop that takes advantage of autodifferentiation and backpropagation. We first define a function for generating training data for a function \(f(x_1,...,x_n)\) over a bounded domain \(\mathcal{D} \in \mathbb{R}^{d}\).
As the reader will see below, the KAN training loop is extremely simple, and uses the familiar zero_grad(), backward, step() PyTorch loop. We do not even use the L-BFGS optimizer specified in the original KAN paper to highlight the similarities, and opt to use the widely used Adam optimizer instead. In our code, we also store and load the best validation checkpoint after training.
# Adapted from https://github.com/KindXiaoming/pykan
def train(
model: KAN,
dataset: Dict[str, torch.Tensor],
batch_size: int,
batch_size_test: int,
device: torch.device,
reg_lambda: float = 0.1,
steps: int = 10000,
loss_fn=None,
loss_fn_eval=None,
log: int = 20,
lr: float = 3e-5,
save_path: str ='./saved_models/',
ckpt_name: Optional[str] = 'best.pt',
):
"""
Train loop for KANs. Logs loss every {log} steps and uses
the best checkpoint as the trained model. Returns a dict of
the loss trajectory.
"""
if not os.path.exists(save_path):
os.makedirs(save_path)
pbar = tqdm(range(steps), desc="KAN Training", ncols=200)
if loss_fn is None:
loss_fn = lambda x, y: torch.mean((x - y) ** 2)
if loss_fn_eval is None:
loss_fn_eval = lambda x, y: torch.mean((x - y) ** 2)
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
results = {}
results["train_loss"] = []
results["test_loss"] = []
results["regularization"] = []
results["best_test_loss"] = []
train_size = dataset["train_input"].shape[0]
test_size = dataset["test_input"].shape[0]
best_test_loss = torch.tensor(1e9)
for step in pbar:
train_id = np.random.choice(train_size, batch_size, replace=False)
test_id = np.random.choice(test_size, batch_size_test, replace=False)
x = dataset["train_input"][train_id].to(device)
y = dataset["train_label"][train_id].to(device)
x_eval = dataset["test_input"][test_id].to(device)
y_eval = dataset["test_label"][test_id].to(device)
pred = model.forward(x)
train_loss = loss_fn(pred, y)
ent_l1_reg = regularization(model)
loss = train_loss + reg_lambda * ent_l1_reg
optimizer.zero_grad()
loss.backward()
optimizer.step()
test_loss = loss_fn_eval(model.forward(x_eval), y_eval)
if best_test_loss > test_loss:
best_test_loss = test_loss
if ckpt_name is not None:
torch.save(model.state_dict(), os.path.join(save_path, ckpt_name))
if step % log == 0:
pbar.set_description(
"train loss: %.2e | test loss: %.2e | reg: %.2e "
% (
train_loss.cpu().detach().numpy(),
test_loss.cpu().detach().numpy(),
ent_l1_reg.cpu().detach().numpy(),
)
)
results["train_loss"].append(train_loss.cpu().detach().numpy())
results["test_loss"].append(test_loss.cpu().detach().numpy())
results["best_test_loss"].append(best_test_loss.cpu().detach().numpy())
results["regularization"].append(ent_l1_reg.cpu().detach().numpy())
if ckpt_name is not None:
model.load_state_dict(torch.load(os.path.join(save_path, ckpt_name)))
return results
We can also define a simple plotting function that takes the results dictionary from above.
def plot_results(results: Dict[str, List[float]]):
"""
Function for plotting the interior of a KAN, similar to the original paper.
"""
for key, value in results.items():
plt.plot(value)
plt.title(key)
plt.show()
Network Visualization
We mostly adapt the network visualization code from the original repository. While the code is quite dense, all we need to do is plot our stored activations per layer, save the plots, then draw out the grid of network connections. You can mostly skim this code unless you’re interested in prettifying the visualizations.
def plot(model: KAN, folder="./figures", scale=0.5, title=None):
"""
Function for plotting KANs and visualizing their activations adapted from
https://github.com/KindXiaoming/pykan/blob/master/kan/KAN.py#L561
"""
if not os.path.exists(folder):
os.makedirs(folder)
depth = len(model.layer_widths) - 1
for l in range(depth):
w_large = 2.0
for i in range(model.layer_widths[l]):
for j in range(model.layer_widths[l + 1]):
rank = torch.argsort(model.layers[l].inp[:, i])
fig, ax = plt.subplots(figsize=(w_large, w_large))
plt.gca().patch.set_edgecolor("white")
plt.gca().patch.set_linewidth(1.5)
color = "black"
plt.plot(
model.layers[l].inp[:, i][rank].cpu().detach().numpy(),
model.layers[l].activations[:, j, i][rank].cpu().detach().numpy(),
color=color,
lw=5,
)
plt.gca().spines[:].set_color(color)
plt.savefig(
f"{folder}/sp_{l}_{i}_{j}.png", bbox_inches="tight", dpi=400
)
plt.close()
# draw skeleton
width = np.array(model.layer_widths)
A = 1
y0 = 0.4
neuron_depth = len(width)
min_spacing = A / np.maximum(np.max(width), 5)
max_num_weights = np.max(width[:-1] * width[1:])
y1 = 0.4 / np.maximum(max_num_weights, 3)
fig, ax = plt.subplots(figsize=(10 * scale, 10 * scale * (neuron_depth - 1) * y0))
# plot scatters and lines
for l in range(neuron_depth):
n = width[l]
for i in range(n):
plt.scatter(
1 / (2 * n) + i / n,
l * y0,
s=min_spacing**2 * 10000 * scale**2,
color="black",
)
if l < neuron_depth - 1:
# plot connections
n_next = width[l + 1]
N = n * n_next
for j in range(n_next):
id_ = i * n_next + j
color = "black"
plt.plot(
[1 / (2 * n) + i / n, 1 / (2 * N) + id_ / N],
[l * y0, (l + 1 / 2) * y0 - y1],
color=color,
lw=2 * scale,
)
plt.plot(
[1 / (2 * N) + id_ / N, 1 / (2 * n_next) + j / n_next],
[(l + 1 / 2) * y0 + y1, (l + 1) * y0],
color=color,
lw=2 * scale,
)
plt.xlim(0, 1)
plt.ylim(-0.1 * y0, (neuron_depth - 1 + 0.1) * y0)
# -- Transformation functions
DC_to_FC = ax.transData.transform
FC_to_NFC = fig.transFigure.inverted().transform
# -- Take data coordinates and transform them to normalized figure coordinates
DC_to_NFC = lambda x: FC_to_NFC(DC_to_FC(x))
plt.axis("off")
# plot splines
for l in range(neuron_depth - 1):
n = width[l]
for i in range(n):
n_next = width[l + 1]
N = n * n_next
for j in range(n_next):
id_ = i * n_next + j
im = plt.imread(f"{folder}/sp_{l}_{i}_{j}.png")
left = DC_to_NFC([1 / (2 * N) + id_ / N - y1, 0])[0]
right = DC_to_NFC([1 / (2 * N) + id_ / N + y1, 0])[0]
bottom = DC_to_NFC([0, (l + 1 / 2) * y0 - y1])[1]
up = DC_to_NFC([0, (l + 1 / 2) * y0 + y1])[1]
newax = fig.add_axes((left, bottom, right - left, up - bottom))
newax.imshow(im)
newax.axis("off")
if title is not None:
plt.title(title)
plt.show()
For example, we can visualize the base network activations with the script below.
f = lambda x: (torch.sin(x[:, [0]]) + x[:, [1]] ** 2)
dataset = create_dataset(f, n_var=2, train_num=1000, test_num=100)
# Initialize and plot KAN
config = KANConfig()
layer_widths = [2, 1, 1]
model = KAN(layer_widths, config)
model(dataset["train_input"])
plot(model)
Visualizing the activations of a randomly initialized KAN network.
Synthetic Example
We can put this all together with a simple example. I would recommend scaling this further to a more interesting task, but for now you can verify that the model training is correct. Consider a function of the form \(f(x_1,x_2) = \exp \left( \sin(\pi x_1) + x_2^3 \right)\). We are going to learn this function using a KAN of the form \(f(x) = \mathcal{K}_{1,1} \left( \mathcal{K}_{1,2} \left( x_1, x_2 \right) \right)\).
Visualizing the activations of a trained KAN network. As expected, the activations learn (affine transformation of) the correct symbolic functions compose to form the original desired function.
Part III: KAN-specific Optimizations
The attentive reader may have noticed that the choice of B-spline is somewhat arbitrary, and the KAN itself is not necessarily tied to this choice of function approximator. In fact, B-splines are not the only choice to use, even among the family of different spline regressors. https://stats.stackexchange.com/questions/422702/what-is-the-advantage-of-b-splines-over-other-splines
A large portion of the original paper covers computation tricks to construct KANs with B-splines as the learnable activation function. While the authors prove a (type of) universal approximation theorem for KANs with B-splines, there are other choices of parameterized function classes that can be explored, potentially for computational efficiency.B-splines are defined over an interval, and evaluating B-spline functions on an input $x$ inherently requires branching logic because the basis functions are only non-zero over a certain interval. To take advantage of modern deep learning hardware, we would ideally like to use a representation that uses a minimal number of the same type of instruction (e.g. multiplication for MLPs) to compute the layer forward pass.
Remark. Because we are modifying the code from Part I, I’ve tried to keep the code compact by only including areas where changes were made. You can either follow along, or use the full KAN notebook.
B-Spline Optimizations: Grid Extension
Recall that the flexibility of our B-splines are determined by the number of learnable coefficients, and therefore the number of basis functions that it has. Furthermore, the number of basis functions is determined by the number of knot points \(G\). Suppose now that we want to include \(G'\) knots for a finer granularity on our learnable activations. Ideally, we want to add more knot points while preserving the original shape of the function. In other words, we want
We can tensorize this expression with respect to a batch of inputs $(z_1,…,z_b)$You may be confused why I use the variable $z$. Recall that we have a unique B-spline for every activation, or $m \times n$ of them. For edge $j \rightarrow i$, each $z_1,...,z_b$ would be each $x_j$ in the batch. Using $x_1,...,x_b$ would conflate the input vector $x$ and an individual coordinate of the input.
which is of the form $AX = B$. We can thus use least-square to solve for $X$, giving us our new coefficients on our finer set of knot points.
def grid_extension(self, x: torch.Tensor, new_grid_size: int):
"""
Increase granularity of B-spline activation by increasing the
number of grid points while maintaining the spline shape.
"""
# Re-generate grid points with extended size (uniform)
new_grid = generate_control_points(
self.grid_range[0],
self.grid_range[1],
self.in_dim,
self.out_dim,
self.spline_order,
new_grid_size,
self.device,
)
# bsz x out_dim x in_dim x (old_grid_size + spline_order)
old_bases = self.univarate_fn(x, self.grid, self.spline_order, self.device)
# bsz x out_dim x in_dim x (new_grid_size + spline_order)
bases = self.univarate_fn(x, new_grid, self.spline_order, self.device)
# out_dim x in_dim x bsz x (new_grid_size + spline_order)
bases = bases.permute(1, 2, 0, 3)
# bsz x out_dim x in_dim
postacts = torch.sum(old_bases * self.coef[None, ...], dim=-1)
# out_dim x in_dim x bsz
postacts = postacts.permute(1, 2, 0)
# solve for X in AX = B, A is bases and B is postacts
new_coefs = torch.linalg.lstsq(
bases.to(self.device),
postacts.to(self.device),
driver="gelsy" if self.device == "cpu" else "gelsd",
).solution
# Set new parameters
self.grid_size = new_grid_size
self.grid = new_grid
self.coef = torch.nn.Parameter(new_coefs, requires_grad=True)
I wanted to mention that for the driver parameter in torch.linalg.lstsq, there are certain solvers like QR decomposition that require full-rank columns on the basis functions. I’ve chosen to avoid these solvers, but there are several ways to go about solving the least-squares problem efficiently.
We can visually evaluate the accuracy of our grid extension algorithm by simply looking at the activations before and after a grid extension.
You will notice in the generated plot above that the KAN learns the correct function $$f(x_1,x_2) = (x_1^3 + x_2^2)$$. Grid extending from a grid size of 5 (left) to 50 (right) using least-squares. You can see some poor fitting behavior on the right activation, possibly due to an insufficient spread of data sampled for grid extension.
Activation Pruning
Pruning network weights is not unique to KANs, but they help the models become more readable and interpretable. Our implementation of pruning is going to be extremely inefficient, as we will mask out activations after they are calculated. There is already a large body of works for neural networks dedicated to bringing about performance benefits through pruningThere are both memory footprint and computation benefits to pruning. On the memory side, reducing the number of parameters is a clear benefit. On the compute side, specific pruning patterns like 2:4 pruning can be made into efficient kernels. Our implementation yields none of these benefits, and is only useful for interpreting the model. so we choose to make the code simple. To begin, we can first define a mask over the activations \(\mathcal{M}_{i,j} \in \{0,1\}^{m \times n}\) that zeros out activations belonging to pruned edges. In practice, we would want to prune before the computation, but tensorizing this process efficiently is not clean.
class KANLayer(nn.Module):
"Defines a KAN layer from in_dim variables to out_dim variables."
"Updated to include pruning mechanism."
def __init__(self, ...)
self.activation_mask = nn.Parameter(
torch.ones((out_dim, in_dim), device=device), requires_grad=False
) # <-- added mask
...
def forward(self, x: torch.Tensor):
...
# Form the batch of matrices phi(x) of shape [batch_size x out_dim x in_dim]
phi = self.residual_layer(x, spline)
# Mask out pruned edges
phi = phi * self.activation_mask[None, ...] # <-- added mask logic
...
We also need to define a metric for pruning. We can define this function at the high-level KAN module. For every layer, each node is assigned two scores: the input score is the absolute value of the maximum activation averaged over the training batch inputIdeally we want to pass in the entire training dataset when computing this, but it seems costly. For now, we just assume a large batch of data can sufficiently approximate the whole dataset., while the output score is computed the same, but for its output activations. More formally,
If \(\text{score}^{(\ell, \text{in})}_{i} < \theta \lor \text{score}^{(\ell, \text{out})}_{i} < \theta\) for some threshold $\theta = 0.01$, then we can prune the node by masking its incoming and outgoing activations. We tensorize this operation as a product of two indicators below.
class KAN(nn.Module):
...
@torch.no_grad
def prune(self, x: torch.Tensor, mag_threshold: float = 0.01):
"""
Prune (mask) a node in a KAN layer if the normalized activation
incoming or outgoing are lower than mag_threshold.
"""
# Collect activations and cache
self.forward(x)
# Can't prune at last layer
for l_idx in range(len(self.layers) - 1):
# Average over the batch and take the abs of all edges
in_mags = torch.abs(torch.mean(self.layers[l_idx].activations, dim=0))
# (in_dim, out_dim), average over out_dim
in_score = torch.max(in_mags, dim=-1)[0]
# Average over the batch and take the abs of all edges
out_mags = torch.abs(torch.mean(self.layers[l_idx + 1].activations, dim=0))
# (in_dim, out_dim), average over out_dim
out_score = torch.max(out_mags, dim=0)[0]
# Check for input, output (normalized) activations > mag_threshold
active_neurons = (in_score > mag_threshold) * (out_score > mag_threshold)
inactive_neurons_indices = (active_neurons == 0).nonzero()
# Mask all relevant activations
self.layers[l_idx + 1].activation_mask[:, inactive_neurons_indices] = 0
self.layers[l_idx].activation_mask[inactive_neurons_indices, :] = 0
In practice, you will call the prune(...) function after a certain number of training steps or post-training. Our current plotting function does not support these pruned activations, but we add this feature in the Appendix.
Fixing Symbolic Activations
A large selling point of the original paper is that KANs can be thought of as a sort of “pseudo-symbolic regression”. In some sense, if you know the original activations before-hand or realize that the activations are converging to a known non-linear function (e.g. $b \sin(x)$), we can choose to fix these activations. There are many ways to implement this feature, but similar to the pruning section, I’ve chosen to favor readability over efficiency. The original paper mentions two features that are not implemented below. Namely, storing coefficients affine transformations of known functions (e.g. $a f(b x + c) + d$) and fitting the current B-spline approximation to a known function. The code below allows the programmer to directly fix symbolic functions in the form of univariate Python lambda functions. First, we provide a function for a KAN model to fix (or unfix to the B-spline) a specific layer’s activation to a specified function.
class KAN(nn.Module):
...
@torch.no_grad
def set_symbolic(
self,
layer: int,
in_index: int,
out_index: int,
fix: bool,
fn,
):
"""
For layer {layer}, activation {in_index, out_index}, fix (or unfix if {fix=False})
the output to the function {fn}. This is grossly inefficient, but works.
"""
self.layers[layer].set_symbolic(in_index, out_index, fix, fn)
We first define a KANSymbolic module that is analogous to the KANActivation module used to compute B-spline activations. Here, we store an array of functions \(\{f_{i,j}(\cdot)\}_{i \in [m], j \in [n]}\) that are applied in the forward pass to form a matrix \(\{f_{i,j}(x_j)\}_{i \in [m], j \in [n]}\). Each function is initialized to be an identity function. Unfortunately, there is not (to my knowledge) an efficient way to perform this operation in the general case where all the symbolic functions are unique.
class KANSymbolic(nn.Module):
"Defines and stores the Symbolic functions fixed / set for a KAN."
def __init__(self, in_dim: int, out_dim: int, device: torch.device):
"""
We have to store a 2D array of univariate functions, one for each
edge in the KAN layer.
"""
super(KANSymbolic, self).__init__()
self.in_dim = in_dim
self.out_dim = out_dim
self.fns = [[lambda x: x for _ in range(in_dim)] for _ in range(out_dim)]
def forward(self, x: torch.Tensor):
"""
Run symbolic activations over all inputs in x, where
x is of shape (batch_size, in_dim). Returns a tensor of shape
(batch_size, out_dim, in_dim).
"""
acts = []
# Really inefficient, try tensorizing later.
for j in range(self.in_dim):
act_ins = []
for i in range(self.out_dim):
o = torch.vmap(self.fns[i][j])(x[:,[j]]).squeeze(dim=-1)
act_ins.append(o)
acts.append(torch.stack(act_ins, dim=-1))
acts = torch.stack(acts, dim=-1)
return acts
def set_symbolic(self, in_index: int, out_index: int, fn):
"""
Set symbolic function at specified edge to new function.
"""
self.fns[out_index][in_index] = fn
We now have to define the symbolic activation logic inside the KAN layer. When computing the output activations, we use a similar trick to the pruning implementation by introducing a mask that is $1$ when the activation should be symbolicRemember that this solution has the same inefficiencies as the pruning solution. We end up computing activations for both the B-splines and the symbolic activations. For readability, we've chosen to implement it this way, but in practice you will probably want to change this. and $0$ when it should be the B-spline activation. We also add the function for setting an activation to be a symbolic function and modify the forward pass to support this operation.
We learn a [2,1,1] KAN for the function $$f(x_1,x_2) = \sin(x_1) + x_2^2$$, but we fix the first layer to have symbolic activations using a lambda function.
Part IV: Applied Example
This section will be focused on applying KANs to a standard machine learning problem. The original paper details a series of examples where KANs learn to fit a highly non-linear or compositional function. Of course, while these functions are difficult to learn, the use of learnable univariate functions makes KANs suitable for these specific tasks. I emphasized the similarities between KANs and standard deep learning models throughout this post, so I also wanted to present a deep learning example (even though it doesn’t work very well). We will run through a simple example of training a KAN on the canonical MNIST handwritten digits dataset to show how easy it is to adapt these models for standard deep learning settings. We first download the relevant data.
# Run these without ! in terminal, or run this cell if using colab.
!wget www.di.ens.fr/~lelarge/MNIST.tar.gz
!tar -zxvf MNIST.tar.gz -C data/
In the interest of reusing the existing train logic we created earlier, we write a function to turn a torch.Dataset with MNIST into the dictionary format. For general applications, I recommend sticking with the torch Dataloader framework.
def split_torch_dataset(train_data, test_data):
"""
Quick function for splitting dataset into format used
in rest of notebook. Don't do this for your own code.
"""
dataset = {}
dataset['train_input'] = []
dataset['train_label'] = []
dataset['test_input'] = []
dataset['test_label'] = []
for (x,y) in train_data:
dataset['train_input'].append(x.flatten())
dataset['train_label'].append(y)
dataset['train_input'] = torch.stack(dataset['train_input']).squeeze()
dataset['train_label'] = torch.tensor(dataset['train_label'])
dataset['train_label'] = F.one_hot(dataset['train_label'], num_classes=10).float()
for (x,y) in test_data:
dataset['test_input'].append(x.flatten())
dataset['test_label'].append(y)
dataset['test_input'] = torch.stack(dataset['test_input']).squeeze()
dataset['test_label'] = torch.tensor(dataset['test_label'])
dataset['test_label'] = F.one_hot(dataset['test_label'], num_classes=10).float()
print('train input size', dataset['train_input'].shape)
print('train label size', dataset['train_label'].shape)
print('test input size', dataset['test_input'].shape)
print('test label size', dataset['test_label'].shape)
return dataset
Finally, like all previous examples, we can run a training loop over the MNIST dataset. We compute the training loss using the standard binary cross-entropy loss and define the KAN to produce logits from 0-9. Due to restrictions in our train() function, we define our test loss as the total number of incorrectly marked samples out of $100$ validation samples.
You may notice that the training is significantly slower even for such a small model. Furthermore, the results here are not good as expected. I’m confident that with sufficient tuning of the model you can get MNIST to work (there are examples of more sophisticated KAN implementations that perform extremely well), but the above example raises questions about the efficiency of the original implementation. Before we are able to properly scale these models, we need to first study the choice of parameterization and whether we should even treat KANs the way we treat MLPs.
Conclusion
I hope this resource was useful to you – whether you learned something new, or gained a certain perspective along the way. I wrote up this annotated blog to clean up my notes on the topic, as I am interested in improving these models from an efficiency perspective. If you find any typos or have feedback about this resource, feel free to reach out!
Appendix
I may re-visit this section in the future with some more meaningful experiments when I get the time.
Plotting Symbolic and Pruned KANs
The plotting function defined in Network Visualization doesn’t include logic for handling the pruned activation masks and the symbolic activations. We will include this logic separately, or you can follow the rest of the visualization code in the original repository.
Open Research: Making KANs Efficient
It is known that these models currently do not scale well due to both memory and compute inefficiencies. Of course, it is unknown whether scaling these models will be useful, but the authors posit that they are more parameter efficient than standard deep learning models because of the flexibility of their learned univariate functions. As you saw in the MNIST example, it is not easy to scale the model even for MNIST training. I sort of avoided this question before, but I want to highlight a few reasons for these slowdowns.
We fully materialize a lot of intermediate activations for the sake of demonstration, but even in an optimized implementation, some of these intermediate activations are unavoidable. Generally, materializing intermediate activations means lots of movement between DRAM and the processors, which can cause significant slowdown. There is a repository called KAN-benchmarking dedicated to evaluating different KAN implementations. I may include an extra section on profiling in the future.
Each activation \(\Phi_{i,j}\) or edge in the network is potentially different. At an machine instruction level, this means that we cannot take advantage of SIMD or SIMT that standard GEMM or GEMV operations have on the GPU. There are alternative implementations of KANs that were mentioned earlier that attempt to get around these issues , but even then they do not scale well compared to MLPs. I suspect the choice of the family of parameterized activations will be extremely important moving forward.
B-Spline Optimizations: Changing Knot Points
A natural question is whether we have to fix the knot points to be uniformly spaced, or if we can use the data to adjust our knot points. The original paper does not detail this optimization, but their codebase actually includes this feature. If time permits, I may later include a section on this – I think it may be important for performance of KANs with B-splines, but for general KANs maybe not.
Citation
Just as a formality, if you want to cite this for whatever reason, use the BibTeX below.
@article{zhang2024annotatedkan,
title = "Annotated KAN",
author = "Zhang, Alex",
year = "2024",
month = "June",
url = "https://alexzhang13.github.io/blog/2024/annotated-kan/"
}
]]>Alex ZhangHighlights of NeurIPS 2023 from Reading All 3584 Abstracts2024-01-09T00:00:00+00:002024-01-09T00:00:00+00:00https://alexzhang13.github.io/blog/2024/neurips2023Introduction
To celebrate the end of my graduate school application deadlines and finals week disaster, I decided
to spend my winter break going through and reading every single abstract of the accepted papers
in the NeurIPS 2023 (which I unfortunately couldn’t attend). It was a long and sometimes mind-numbing process (especially since the TeX wasn’t rendering on the neurips.cc website), but it was really cool to see all these works and ideas that I had no idea were being done. Luckily, I am somewhat familiar with quite a number of these papers because they popped off on arXiv or
Twitter when they were first announced, so I wasn’t discovering every
single paper for the first time. Here is just a highlight of what I found interesting and the
general vibes I had while reading over the last two weeks, but keep in mind that I am an
undergraduate student that has not worked with or spent a lot of time with a variety of popular
topics (e.g. federated learning, differential
privacy, causal
inference). I’ve structured this post into a
high-level overview for each topic of what I observed, followed by short discussions on papers I
found interesting. Each discussion is loaded with references to the relevant NeurIPS papers, and I’ve tried to ensure that almost every citations in this post are from NeurIPS 2023.
If you want to read the abstracts on your own, they’re available publicly at
https://neurips.cc/virtual/2023/papers.html. Finally,
I ended up searching up so many terms, I eventually started keeping track of them in case the
curious reader wants to know at the bottom of this post.
2023 was a great year for AI (generative models especially), and the number of submissions to
NeurIPS 2023 reflects that. This year, there were 3584 accepted papers out of an astonishing 12345 submissions. Honestly, I expected to go into this process marking only my top 10 or 20 favorite papers, but I discovered so many absolutely fascinating works on the most random things like applying 3D neural rendering methods to Unreal Engine. By the end of this process, I ended up reading or skimming probably 50 or so of the papers (excluding the ones that I had seen before). Of course, from the abstract alone, it is not possible to grasp the quality or impact of a work, and in an ideal world I would have read each paper in their entirety and tried their code as well. Regardless, after reading through, these are some things that stuck out to me this year:
Multimodal is the new “thing”. Rather unsurprisingly, combining vision and language is a hot topic . With LLMs demonstrating impressive performance in the past few years, leveraging these models to reason over visual data is a natural progression of the technology.
In-context Learning (ICL) belongs everywhere. Anything that even resembles a transformer should exhibit in-context learning, whether its a diffusion model , for RL , or even for generic regression . I wonder what’ll happen when more gradient-free learning methods like hyperdimensional computing https://arxiv.org/abs/2111.06077 take off…
Diffusion models are really good at generating things. Diffusion models are getting so good at generating stuff, it seems like people are confident that they can be used for synthetic data. There is a lot of exploration into using diffusion for more than just de-noising and text-to-image generation .
Leveraging model priors. Foundation models are a blessing because they contain so much information about a specific domain. Leveraging these models beyond just in-domain downstream tasks is going to be extremely important to understand for the next few years, especially concerning data multiple modalities . We also want to understand how to use the information present in these models in an interpretable way.
Model robustness. We want to be able to trust our models, and this means that our models behave according to our expectations. These models should also be robust to malicious actors and data, and should not leak our information, especially if we continue to feed them with our data. There are many tradeoffs and metrics for model robustness, so identifying the upper bounds both theoretically and empirically are important.
What does it mean to be similar? How do we measure similarity being two “concepts”? Or even just semantics? An intuitive way is to use similarity metrics like inner products over an embedding space, but how do we know that this embedding space is truly representative of the data ? Do we measure similarity in terms of probability distributions, or do we use mutual information ?
When are inductive biases useful? We don’t necessarily always have the luxury of being able to scale our models and datasets for every domain, and we don’t know whether or not our models should not use inductive biases . We want to understand whether we can leverage our own understanding of problems to introduce effective inductive biases like symmetry to solve problems .
Large Language Models
This is the section of papers I was most familiar with before reading through the abstracts.
Generally, there have been a lot of works exploring the reasoning capabilities of LLMs through
prompting or fine-tuning. I think the LLM papers at this conference reflect the
interests of the NLP community for the past year even though a lot of these works can be considered
at least a year old at this point (which in this field is old!). One general gripe I have with these works is that they often like to make claims about general LLM behavior, but often evaluate on an arbitrary LLM of their choosing. It would be nicer if there was some consistency here, but it’s probably because the field is so fast-moving combined with the fact that many models are just inaccessible to 95% of labs. There is also this interesting interplay of whether data purity or extra machinery is the driving factor towards improving performance. These are the general themes that I’ve noticed:
Reasoning. How can we apply algorithms or intuitions to fine-tune
LLMs to be better planners, reasoners, etc. like in ? Furthermore, how can we explicitly improve their reasoning capabilities without gradient updates like in ?
Logical Reasoning. Can LLMs be used for logical tasks like mathematics and coding ? What are the pitfalls and potential solutions? We are interested in analyzing the limits of their abilities, as well as understand why and when they fail .
Agents. Can LLMs be considered cognitive agents? That is, can we
equip them with capabilities (tools, externals APIs , etc.) such that they can interact with environments through text generation? Furthermore, can they interact, think, and reflect in an anthropomorphic way?
Efficiency. A key bottleneck in autoregressive LLM inference on GPUs is data movement, so research into circumventing this issue by exploiting parallelism and cached data is key (e.g. speculative decoding) . Furthermore, can we improve the speed and cost of both training and inference on LLMs at both a systems-level (e.g. take advantage of properties of GPU memory footprints and throughput speeds) and model-level (low-rank fine-tuning, adaptors, sparsity, etc.) ?
Scaling and Fine-tuning Models. What advances can we make to push the capabilities of foundation models (e.g. MoE) ? What procedures can we use to efficiently fine-tune these models for downstream tasks or direct their generations towards user-aligned behavior (also can we do this without reinforcement learning (RL) ) ? Or, what techniques can we use to bridge the gap between smaller models and huge models? Also, what kind of scaling laws can we identify between model parameters and data ?
Memory and Context Windows. The context window of an LLM is inherently limited by memory constraints and the quadratic runtime of the standard attention mechanism. How do we increase the size of the input context window without degrading performance? The primary methods that are being investigated are external memory stores in LLMs to process huge chunks of texts like a book and summarization tokens .
Emergent Capabilities. It has been observed that LLMs seem to be suddenly able to perform tasks after scaling up to a certain point. Can we characterize these emergent abilities of LLMs effectively and why we observe them ?
Controlling Generation. Can we 1) hard constrain the outputs and 2) steer LLM generations to be what we want? Typically (2) has been done with instruction-tuning and RLHFReinforcement Learning with Human Feedback, an application of reinforcement learning to further fine-tune language models to better reflect our human preferences. Recommend reading this source: https://huggingface.co/blog/rlhf, but methods like modify activation patterns in the model during inference while learns a smaller auxiliary model to edit the prompt of the larger model, which we can effectively treat as a set of parameters. Furthermore, what methods can we come up with to ensure preference-based alignment is accurate and robust
LLMs can do [insert task]. How far can we go with zero-shot, few-shot, and in-context
learning (ICL) to mimic known algorithmic procedures entirely through prompting? For example, policy iteration from RL or time-series forecasting .
Evaluating Language Models. What kind of metrics and
benchmarks are needed to effectively evaluate the abilities of different LMs? Is it by using a strong LLM as a judge ? Also, we generally just want more benchmarks for evaluating abilities like factuality , coding , and domain-specific information .
[LLM] Interesting Papers
Below is a list of papers I particularly liked and think are worth reading in their entirety. Of course, there were plenty of other extremely interesting and useful works at this conference, so please do not take this as some kind of definitive ranking of papers. Also, I’m mainly going to be giving a brief sentence about why I think each paper is cool/important and not a tldr, as I think you can get a lot more out of just reading it yourself. I have included this type of subsection at the end of every topic, so enjoy!
Tree-of-Thoughts: A simple yet highly useful idea,
tree-of-thoughts (ToT) is simply an extension of chain-of-thoughts where a model can now traverse
through its own “thought” chains as a tree. This simple application of graph traversal to CoT
(which also gives beam search vibes) has been used extensively for prompting in the last year. This paper actually came from my PI’s lab :)
Toolformer: Another well-known and simple
approach, Toolformer is an extremely general framework for fine-tuning a model to be able to use
user-specified APIs like a calculator or a search engine. It’s really practical and their
experiments use GPT-J https://huggingface.co/docs/transformers/model_doc/gptj, so it’s quite easy to replicate for your own use cases.
Are Emergent Abilities of Large Language Models a Mirage?: I remember this paper being widely debated when it came out, with many arguing that the author’s conclusion was not indicative of anything useful. I think this paper makes a great point, in that emergent capabilities are a consequence of the evaluation metrics we choose to measure abilities, even if these evaluation metrics are natural (e.g. % of math questions answered). The problem with relying on intuitive of pre-existing metrics is that they don’t tell the full picture about scale vs. performance. I’ll put it like this. Suppose our LLM has never been able to solve task A. No matter how we have scaled it so far, it can never solve A. Scaling is expensive, so an important question is whether scaling will lead to emergent capabilities on A. Instead, if we have an auxiliary task B that is indicative of solving A, we can measure the relationship between scale and performance on A by looking at performance on B. The usefulness of reframing is to hopefully find metrics that show linear relationships between things like scale and downstream task performance, but this is still hard to do.
SPRING: Studying Papers and Reasoning to Play Games: This paper is exciting to me because I am very interested in models that can utilize external sources of information in an intuitive way. Outside of their reasoning module, they read information using an LLM from a game manual (honestly I don’t really get why they use the LaTeX source though, maybe for equations?) and store it as context for their agent (also an LLM). The point is that an LLM can act as a retriever and can intuit about what information is relevant. I think that this work is in a very preliminary stage though, and there is a lot of future research to be done in generalizing this type of framework.
RapidBERT: Pretraining BERT from Scratch for $20: This paper is kind of crazy… With lots of modern tricks (FlashAttention, ALiBi, low-precision layernorm, etc.) they can pre-train a BERT with the same performance as the original in just 9 hours on an A100. I think it goes to show far how we’ve gone in optimizing our language models. It is also important to note that they use a more modern scraped dataset in this paper (C4 https://github.com/allenai/allennlp/discussions/5056) for pre-training.
Scaling Data-Constrained Language Models: Understanding the relationship between model scale and data scale is important, and this paper looks into scaling laws under limited amounts of unique data. In their experiments, they found that repeating data during training works but diminishes in performance compared to using completely unique data. As an aside, their results focus on cross-entropy loss, but with any work that focuses on CE loss, it is important to distinguish inherent entropy in the data and the actual performance gap you want to mitigatehttps://arxiv.org/abs/2307.15936.
Collaborative Alignment of NLP Models: We have been conditioned to use single, huge foundation models because they work well in practice, but this paper looks into whether the learning of several, concept-aligned models with some meta-chooser on top actually works just as well. The primary benefit is the ability to modularize and parallelize LLMs, making them more flexible and also potentially faster.
Hard Prompts Made Easy: Gradient-Based Discrete Optimization for Prompt Tuning and Discovery.: You can sort of think of (hard) prompts as parameters to an LLM that transferrable to other LLMs (e.g. If I prompt GPT-4 with “Explain Newton’s laws like I’m 5”, I expect LLAMA 2 to answer similarly). In the case of text-to-image models, the images we get are often not exactly what we want (there are various reasons for this we discuss in the multi-modal section!). This work is basically a way to steer text prompts with gradient-based optimization so they generate the images you want.
OpenAssistant Conversations - Democratizing Large Language Model Alignment: So I actually followed this project on YouTube through Yannic Kilcher’s channel https://youtube.com/yannickilcher, and the central idea is to open-source the data required for RLHF because its extremely expensive to curate 60k+ human preference samples. I believe that open-source communities are extremely important for AI, and it’s exciting to see them produce extremely useful projects like this one. Because it is open-source, a large chunk of the paper discusses quality control and reducing “bad” or “toxic” data.
Direct Preference Optimization: Your Language Model is Secretly a Reward Model: For a while, the standard preference-alignment approach was to learn a reward model over preference data and fine-tune an LLM with RL on this reward model (RLHF). The issue with this approach is that RL is generally quite unstable and hard to work with, so this paper first motivates re-parameterizing the RLHF objective into a new objective that we can directly minimize. I’m not actually sure how well this works relative to RLHF in practice because I’ve never had access to these tools, but it is an RL-free alternative to preference-based alignment.
Multi-modal Learning
This year had a heavy focus on multimodal (mostly vision + language) models, with many companies/labs introducing their own shiny foundation models and associated datasets to compete with GPT-4. A lot of the desirable features in large multimodal models parallel that of large language models, so many of the research questions and themes are quite similar. In my mind, a core difference is the combinatorially larger amount of paired or associated data required to build a model that can interchangebly handle two different modalities. The obvious direction is to continue to scale the size of visual-language datasets with the size of new models, but I suspect that fundamentally answering how to “ground” two different modalities from a representation learning perspective may be able to reduce the necessary scale. At the end of the day though, this is still an open research question which I don’t know the answer to. The general themes I observed were
New Foundation Models. Large multimodal models, specifically vision-language, are the logical next progression to LLMs. Thus, it’s rather unsurprising that many research groups are racing to build the next big model with the same capabilities of LLMs like being instruction-tuned and in-context learning. However, it looks like the training mechanisms for making these models robust are still pretty elementary. For example, , they simply treat everything as a token, but use a special embedding token for images and attentive pooling to reduce the complexity of these embeddings, then use the interleaved text and image data for standard log-likelihood optimization. At this conference, I didn’t see many actual models being showcased (although I’ve seen them over time on Twitter), but the large number of datasets seem to indicate that this is a growing direction.
Datasets and Benchmarks. We’ve observed several instances of “good” data being key to getting LLMs to work better. The same logic applies to multi-modal models, except because there generally is no 1-1 mapping between tokens in each modality, this is quite hard. Regardless, there are lots of multi-modal datasets and benchmarks being curated, either by scraping and filtering data on the internet or by curating the data .
The Shared Representation. As far as I’m aware, the two main ways of building a multi-modal learning model are to tokenize each modality and train it as a decoder model on negative-log-likelihood loss or train it CLIP-styleCLIP or Contrastive Language-Image Pre-Training is an contrastive learning-based encoding method for embedding images and language into the same embedding space. The benefit is that we can query into this embedding space using text or images, and query from this embedding space to generate either text or images. The idea was popularized from its used in DALL-E, and is the standard for text-to-image models. Read more here: https://openai.com/research/clip as an encoder model. In both cases, we want to understand this latent representation embedded either in the model layers or in the embedding space to see if we can exploit its properties .
Complex text prompts. It is known that text-to-image models often exhibit bag-of-words behavior, which means it lacks a strong understanding of syntax and logical quantifiers in a sentence. If you’ve ever played with Midjourney A popular text-to-image generator: https://www.midjourney.com/home?callbackUrl=%2Fexplore or DALL-E2 A popular text-to-image generator by OpenAI: https://openai.com/dall-e-2. Several works attempt to inject compositional reasoning in these models to solve this .
Multi-modal video understanding. Processing videos adds a temporal dimension to these models that is quite difficult. Even standard video understanding models have been difficult to get right for a while now. The naive approach is to concatenate frames and pass them into a image-language model, so there has been some interest in making the language component temporally aware .
All the same questions for LLMs. Fundamentally, these models are just huge transformers. Even the vision components are basically just LLMs where the vocabulary is image patches (although the vocabulary is much bigger and not fixed I suppose). Regardless, any open problem for an LLM (efficiency , robustness, fine-tuning algorithms ) is essentially also a problem for multi-modal models. The difference though, is that we can assume that we are given a model that is good at each modality, so “bridging” the modalities is what we need to actually solve.
[Multimodal] Interesting Papers
There are a lot of what I like to call low-hanging fruit in multi-modal models that have been solved, and while they are still interesting and definitely more applicable to most problems, I wanted to focus on some works that I thought were cool.
4M: Massively Multimodal Masked Modeling: Apple doesn’t usually publish in machine learning conferences (e.g. they didn’t let me publish or extensively discuss my work when I was there), but I have to say, I thought this paper was pretty cool. I mentioned in point (3) that a lot multi-modal models are either decoder-based (token-style) or encoder-based (embedding-style), but the authors of this work discretize the shared embedding space and embed using tokens instead of a continuous embedding.
Connecting Multi-modal Contrastive Representations: The idea here is that as we continue adding modalities to a shared representation space, we ideally want to use as little paired data as possible (for $N$ modalities, you would need $\binom{N}{2}$ sets of paired data). So we want to leverage pre-existing multimodal models, say a visual-language and a language-audio, and combine their representations without the need for visual-audio data. They effectively learn the projection function from both pre-trained models to the shared representation space, and motivate the loss required to align semantically similar embeddings.
A Theory of Multimodal Learning: This is an interesting paper on trying to formalize multimodal learning, although I don’t exactly understand how this differs from standard unimodal training. My understanding is that the primary limitation is data, and we can basically treat two modalities as distinct subspaces in some larger “unimodal” space. But regardless, they provide a formal differentiation between multimodal and unimodal learning and prove some standard ML theory bounds for an empirical risk minimization (ERM) algorithm.
VLAttack: Multimodal Adversarial Attacks on Vision-Language Tasks via Pre-trained Models: They use some cute tricks for developing black-box adversarial attacks on vision-language models by considering perturbations for both modalities in isolation, as well as for image-text pairs. Similar to above, it’s not clear exactly why we need a distinct “multimodal” strategy for this kind of stuff, but perhaps more works into this area will provide more insight.
Geodesic Multi-Modal Mixup for Robust Fine-Tuning: We
want to understand the landscape of multi-modal embeddings and see if we can impose nice
properties of this space like making it isotropic. In this paper, they first propose that CLIP
embeddings (ZS) and naively fine-tuned embeddings (FT) have an inherent uniformity issue that
distinctly separates “text” and “images” into different subspaces. Ideally though, they argue
that we want the distribution over the space (they constrain it to be a hypersphere) to be based
on the semantics. Their method proposes to mold this space by generating “mixed” hard-negative
samples to use with the standard contrastive loss during fine-tuning.
I’m curious because in the past, isotropic properties of “word embeddings” was thought to be a
necessary thing, but it turns out we don’t really care, and a lot of methods that try to
constrain this didn’t turn out to be that useful. I wonder how that applies here.
Transformers
With the Transformer module being the standard building block for scalable models, it is important that progress is made on improving their usage as a whole. Just as a side note, I think generally the term “transformer” is now overloaded to mean any structure using positional encodings plus an attention-mechanism, feedforward layers, and normalization in some repeated fashion, and does not necessarily refer to the original Transformer architecture. Interestingly, one thing I didn’t really find at this conference was investigating the enforcement of constraints or inductive biases like equivariance to Transformers, which may be an indicator of Sutton’s Bitter Lesson http://www.incompleteideas.net/IncIdeas/BitterLesson.html. The general themes were
Studying Transformer Models. Are there provable or empirically well-understood limitations of Transformers that may be severely limiting for future research directions? We know that Transformers seem to excel at reasoning but also frequently fail in simple cases, so argue through a series of compositional tasks that these models (GPT-3,4) tend to pattern match reasoning chains. Furthermore, in , they try to examine the function classes that Transformers can efficiently approximate, which is especially important for upper bounding the representational capacity of models as they scale. Finally, there are works that examine/ablate features of the Transformer to study their impact.
Efficiency. How do we modify parts of the transformer to be more efficient to 1) scale them for bigger models and 2) use them on low-compute devices? In , they selectively act on a fixed block of the embeddings at any layer to increase model capacity while keeping inference latency fixed. In , they train layers to selectively drop tokens by imposing a sparsity constraint that affects their modified attention mechanism. Meanwhile, works like focus on preserving performance for quantized transformers and focus on deploying transformers on microcontrollers.
Modifications to Attention. Can we make attention mechanisms more efficient ? As in sub-quadratic runtime ? Sparse ? Or can we even replace attention ?
Memory. Can we increase context-window lengths or add external memory for transformers? This question is tied heavily to LLMs, and hence the methods (external memory source or summarization) are similar. Other than the works tied to LLMs, I only really found , which basically learns to compress token sequences into “VIP”-tokens that represent what’s most important. My only concern is whether these tokens are domain-specific and how a fully-trained model fairs for transfer learning to other modalities.
[Transformers] Interesting Papers
Faith and Fate: Limits of Transformers on Compositionality: It has always unclear how good Transformers are at compositional reasoning, and this paper tries to uncover this question in a systematic way. As in, they literally break down each task (they are mostly computational tasks like multiplication and dynamic programming puzzles) into a computation graph and train their models in a bunch of different ways, ultimately concluding that Transformers are good at pattern matching reasoning chains, but not necessarily extrapolating reasoning itself.
Geometric Algebra Transformer: This paper is super cool and really well written. It’s a fairly non-traditional work that enforces equivariance with respect E(3) https://en.wikipedia.org/wiki/Euclidean_group, which is all linear combinations of translations, rotations, and reflections of 3D Euclidean space. This is particularly useful for learning representations of geometric data, and they apply their Transformer to a downstream planning task and demonstrate that it still works even when we don’t want to enforce this constraint.
Pretraining Task Diversity and The Emergence of Non-Bayesian In-context Learning for Regression: We’ve always been curious how well models generalize to information not present in the training data, but this paper takes this question with a bit more abstraction, examining the effectiveness of in-context learning on tasks not present in the training data. They propose a “task diversity threshold” and claim that in-context learning emerges if the pre-training data is sufficiently diverse.
Fast Attention Requires Bounded Entries: Theoretically-motivated result on why we want entries in the attention matrix to be relatively small with respect to the matrix size if we want to speed up computations through approximation algorithms. It’s a pretty neat work, and I don’t necessarily think it’s intuitively obvious why this holds.
When Do Transformers Shine in RL? Decoupling Memory from Credit Assignment: Since Transformers are now appearing in almost every non-compute-sensitive task, it’s interesting to understand why they work so well. This paper looks into the performance model-free RL agents on specific tasks designed to evaluate long-term memory and the efficiency of credit assignment. They find that (rather unsurprisingly), Transformers are useful for storing in-episode memory, but they do not solve the long-standing credit assignment problem, which means they are not the key to solving RL.
MotionGPT: Human Motion as a Foreign Language: We have generally settled on the notion that discrete tokenized representations are quite nice for Transformers, and this paper takes that one-step further by tokenizing human motion frames. The use-case is interesting, but I’m also interested in extending this kind of tricks for arbitrary modalities. Maybe we can see Transformers used for just about any kind of prediction!
Reinforcement Learning
Reinforcement Learning was a huge topic this year, with many papers discussing RL in the context of other works like diffusion models or in-context learning . There is a distinction between classical RL works and deep RL works, the former of which are primarily theoretical, and the latter of which are primarily empirical. The main difference is the use of a neural network to approximate tabular mappings, especially in settings involving an infinite or combinatorially large state and/or action space. I’m not entirely sure what direction the field has been in the past few years because it is so broad, but I have noticed an emphasis on sample efficiency and the utilization of priors to accelerate RL exploration. This is probably because earlier successes in deep RL have primarily been through OpenAI or DeepMind brute forcing domain-specific trajectories into a model, so we have proven that deep RL works and can focus on efficiency. Lastly, I noticed a lot of papers related to offline RL , where models make updates without interacting with the environment.
Robustness. I’m specifically referring to the robustness of RL training algorithms and preventing failure modes. It is fairly well-known that RL is quite delicate and requires a lot of tricks to get working in practice, so it is unsurprising that a lot of work goes into improving the robustness of these algorithms. There are many failure modes of RL that are addressed in this conference, and I highlight them below:
Balancing the ratio of updates to timesteps is important for trading off convergence and sample efficiency. To prevent primacy bias (favoring early explorations), deep RL methods often perform a “reset” of their weights while storing the transition data in a replay buffer. Doing this can cause the model to diverge on reset, so attempt to circumvent this issue by using an ensemble of agents and perform random resets so at least one agent is not reset.
We often want RL agents to act conservatively, so when they reach an unseen state, they do not act wild. In , they add penalties to out-of-distribution states and prove that in an offline RL setting, they achieve a conservative estimation of the expected value function.
Deploying RL in realistic settings often implies the need for safety constraints to avoid exploring unsafe states. Works like look into imposing these constraints with high probability.
There are many tricks involved in RL training, many of which are problem-dependent. For example, importance weighting over the training dataset in offline RL to prevent being influenced by low-reward trajectories . Or reducing variance in the learning process with multi-step surrogate rewards . In , they analyze why augmenting visual observations leads to better sample efficiency. Some works even investigate tricks from other models like reward scaling and regularization schemes and apply them more generally .
Improving Exploration by Leveraging Priors. Reward functions play a huge role in the convergence of RL training. In most settings, the only “true” reward is a sparse reward given for achieving a goal (e.g. winning a chess game). However, propagating this sparse reward through a combinatorially large state and transition function space is fundamentally difficult, so people often design intrinsic reward functions to better guide an agent towards maximizing the true reward. Some methods attempt to generally identify good transitions and states to explore by looking for state diversity and orthogonality, while other methods focus on automating a reward designer’s intent by conditioning on images, videos, or language through some pre-trained embedding space and push exploration in a certain direction using these exploration “hints” . Meanwhile, propose that even with sufficient exploration, a model may not learn a good policy, so dynamically modifying the model during training may fix that!
Learning World Models for Model-based RL (MBRL). If you’re familiar with the basic formulation for the dynamic programming update functions used in RL, you’ll know that knowing the transition function, or the model of the environment dynamics, is an extremely powerful guarantee that you generally do not have. However, it is possible to try and “learn” this model to apply MBRL methods. One of my research interests as of late is learning and editing world models using language, so it is pretty exciting to see these works. A central theme in the use of world models is learning and acting “in imagination”, which means treating the world model itself as an environment that the agent can interact in, which is especially useful for environments where interacting is costly or dangerous. In , they use the world model as a way for the model to “think” before it generates an action. In , they learn strictly formatted world models in a standardized language https://en.wikipedia.org/wiki/Planning_Domain_Definition_Language that models can interact with. Furthermore, many world models use an recurrent neural network (RNN) as the backbone for historical reason, so in , they experiment with different models for the world model backbone and propose their own with better empirical performance.
Multi-agent RL. Multi-agent RL (MARL) involves multiple learning agents in the same environment, with most papers I’ve found generally focusing on cooperative or mixed-sum games. A lot of similar research themes in RL apply here as well, but there is also room for game-theoretic analysis. A core limitation in prior MARL work is the assumption of a fixed task and fixed environment, so works like extend standard frameworks to a multi-task learning setting. There are also works regarding how to leverage reward signals that apply to the team of agents versus a singular agent which is not obvious and directly influences the learned policy of each agent. Finally, because MARL is inherently expensive (you’re launching several agents at once!), creating environments that are compute-friendly is a topic of interest .
Goal-conditioned RL. Goal-conditioned RL (GCRL) is a class of algorithms or problems where decisions are conditioned on both a state and a goal. There were only a few GCRL papers at this conference with an emphasis on offline RL strategies such as using sequence modeling over trajectories as a goal , but I did find an interesting work on using the distance (they define their own metric) between the goal distribution and state visitation distribution as an extra reward signal for exploration .
Theoretical Analysis. There were a lot of papers on bandit problems (especially adversarial or contextual bandits) and provable regret/convergence bounds , most of which I was not really able to understand. While I think following the math itself and reading through it is quite fun, I’m just not familiar with what problems people are interested in and what is unsolved, so it’s hard to gather from the abstracts or even a quick skim of the papers what the immediate impact is. That’s not to say that these works are not interesting or useful, but I am going to be careful not to say something false about their results. However, I did find two works that prove convergence guarantees for deep RL!. In , they prove convergence guarantees for deep Q learning using $\epsilon$-greedy exploration under accelerated gradient descent (momentum) under some pretty minimal assumptions. In , they limit their analysis to linear MDPs and simplified neural networks, but show convergence guarantees for actor-critic and proximal policy optimization (PPO) methods respectively.
[RL] Interesting Papers
Conditional Mutual Information for Disentangled Representations in Reinforcement Learning: I haven’t really seen prior works in RL that try to tackle disentanglement in feature representations, but the motivating factor here is that the exploring RL agent does not sufficiently capture the environment dynamics and instead learns spurrious feature correlations. I’m not sure if the technique they used was done for image/video works in the past, but it makes sense to me that this is not an RL or agent-specific technique.
Creating Multi-Level Skill Hierarchies in Reinforcement Learning: When I was playing around with PySC2 (Starcraft II RL environment), I used to always be confused how an RL agent would feasibly learn these complex chains of actions (turns out the answer was tons of data). Another approach outlined in this paper is to explicitly map out hierarchical skill trees, where the lowest levels are explicit actions and higher levels are more abstract, learnable skills. I’ve seen a similar idea applied to LLMs where you can explicitly query the LLM to reason about what it should do, but in RL its more robust but less interpretable.
Efficient RL with Impaired Observability: Learning to Act with Delayed and Missing State Observations: An interesting question in RL is how much “error” is induced by a partial loss in observability. They bound the worst-case performance on control systems depending on the expected percentage of missing states and show that RL is still applicable to this class of problems in an efficient way (which generally means poly() any environment parameters).
Learning to Influence Human Behavior with Offline Reinforcement Learning: I feel like in any multi-agent or game theoretic setup, we always assume other players are playing optimally. This paper is unique in that they try to learn a policy in a cooperative multi-agent setup that assists the other agent towards a certain desirable behavior. The environment is a grid-world version of Overcooked https://www.team17.com/games/overcooked/ which I find really funny, as this is the perfect environment for this kind of model.
Is RLHF More Difficult Than Standard RL?: They reduce RLHF and general preference-based reward signals to different classes of known problems in RL, motivating how RLHF is not inherently more difficult than standard RL problems. The paper goes into quite a few instances of preferenced-based RL, and is fully theoretically motivated.
A Theoretical Analysis of Optimistic Proximal Policy Optimization in Linear Markov Decision Processes: I’ve understood PPO as a series of empirical tricks and approximations to the theoretically motivated Trust Region Policy Optimization (TRPO), so I always thought that studying its theoretical properties to provably converge has been lacking. Even if this study is applied to a simple RL setting, it’s an important first step towards theoretically motivating PPO.
Generative AI
Generative AI as a whole has also been booming through 2023, especially as a marketable product. Given how accessible and easy to customize they have gotten, I think that the common layperson should understand at a high-level what kind of generative AI is out there. I should note that I structured this section to mostly exclude large language models or language as a modality altogether. These papers have mostly been targeted towards diffusion models, although there were still a few works at NeurIPS 2023 that focused on GANs like . The general themes I’ve observed are as follows:
Pre-trained Foundation Models. Generative models rely on a large backbone model that encodes the knowledge base of the domain that it acts on . I do wish there were some papers discussing techniques for scaling models robustly and efficiently, but perhaps it comes with experience.
2D to 3D View Synthesis. 2D generative models are at a pretty decent state, so extending their abilities to create 3D generative models is an open research question. Prior work on novel view synthesis encode scenes in the weights of the model, but recent work has looked models that can generalize to different scenes. For example, in they train a signed-distance function (SDF) based reconstruction model to generate 3D meshes from generic 2D image views at inference time. In this field, spatial hash encodings have proven to be effective on GPU hardware for drastically speeding up 3D generative models, so enables dynamic scenes (basically add time) to be encoded by learning to selectively employ different hash encodings for static and dynamic parts of the scene. Finally, with Segment Anything (SAM) https://segment-anything.com being an extremely powerful 2D vision-language foundation model capable of accurate semantic image segmentation, presents a way to extend this to 3D. This process involves generating view-conditioned prompts to generate views of an image and properly inverse projecting these 2D masks back to a 3D voxelized space. This work is exciting and the results are very noisy and not great, but it’s definitely an open research problem that will make significant progress soon!
Single-image 3D Reconstruction. An alternative to novel view synthesis is take a single image and try to extrapolate using domain knowledge what the 3D model looks like. Most of these methods leverage some kind of pre-trained 2D diffusion model to generate the alternate views, but they are distinct in how they choose to do this. Some do it by inferring 3D projective geometry and others try optimizing directly with generations from a multi-view 3D diffusion model .
Generating on new Modalities. Generative AI is not limited to language and vision. Audio and speech generative models have found that tokenized representations of other modalities can be used in Transformers. Of course, the details are not that simple, and from my understanding encoding the tokens requires working over a spectrogram representation that is non-trivial.
Text-to-video. I’m sure you may have seen some clips of text-to-video AI on social media, and while it is impressive, it is far from being as robust as the text-to-image models. A lot of work goes into ensuring causal and cross-frame temporal consistency in these generations . While these models have an obvious use case for generating videos, I did find an interesting use-case of these models as a form of planning for policy generalization .
Diffusion Models
I decided to add a separate subsection on diffusion models with a focus on techniques that improve the base diffusion model process As a sidenote, check out my roommate's repository on a really simple and intuitive implementation of diffusion models: https://github.com/edogariu/nice-diffusion. Honestly, there were so many diffusion model papers (also applied to other fields like RL ) that this subsection alone is more rich than most of the other sections. From my understanding, diffusion models can be viewed from several different “lenses”, with one being as a Gaussian process and another being through Langevin dynamics. You can even view diffusion models as a sequence of Variational Autoencoders (VAE). For a bit of perspective, I had the opportunity to speak with Jascha-Sohl Dickstein Jascha was first-author of the original diffusion models paper: https://arxiv.org/abs/1503.03585 through the AI Tiger Trek trip I helped organize last April, and he said that various practical formulations of the diffusion model implementation had sprung up at around the same time from these different viewpoints. There is a lot of ongoing research into using these models effectively, but here is what I noticed from this conference:
Inference-speed. There have been strides by labs to make the training and fine-tuning process of diffusion models cheaper https://www.mosaicml.com/blog/stable-diffusion-1, but inference remains quite expensive. In , they motivate a training-free sampling method for performing an extremely low number of sampling steps (<10) while maintaining generation quality (for comparison, the standard amount is ~1000 steps and ~20 is considered low from prior works), while in they motivate stochastic sampling solvers and relate them to other popular solvers like the previously mentioned one.
Interpreting the Latent feature representation. Can we understand the features that are learned by a diffusion model? This is generally done by probing the embedding space and clustering or checking if classes are linearly separable , where they find Stable Diffusion features exhibit good spatial information but worse semantic understanding compared to another popular embedding method. Another step is to investigate and probe the latent seed space used to condition the generator, as done in .
Multi-input. Similar theme to multi-modal models in general since they are so closely related, but can we develop diffusion models that take both text and visual data as input and produce any desired output? Can we also make it robust to composition and more complicated prompting ?
Filling missing information. Can we leverage diffusion models to fill in the missing gaps of information in an image or a dataset label ? This is actually really cool, because the implication is that unlabelled or noisy images contain enough structure to reconstruct the unknown parts without the model just making things up.
[Gen AI + Diffusion] Interesting Papers
Tree-Rings Watermarks: Invisible Fingerprints for Diffusion Images: Copyright and generative AI identification is going to become increasingly more important as the technology gets more accurate. This technique slowly applies an invisible watermark during the diffusion sampling process that is easy to recover when inverting the diffusion process. I have a feeling that similar to works on adversarial attacks, there is going to be a constant chase between watermark and watermark removal works in the near future.
Generator Born from Classifier: Can you take a trained image classifier and use it to generate images with minimal extra learning? We have seem class-conditional works like in diffusion models, but this work is trying to do something much stronger. This work is a first-step into leveraging a classifier for image generation, and they use the theory of Maximum-Margin Bias to extract training data information from the parameters of a classifier.
CL-NeRF: Continual Learning of Neural Radiance Fields for Evolving Scene Representation: NeRFs implicitly store the scene they are rendering in their weights, but they are generally fixed. But what if we want to capture an ever-changing scene? It seems natural to imply concepts in continual learning, as we mainly want to 1) not forget important static elements of the scene during weight updates and 2) dynamically add components to the scene through weight updates, and this work is a first step into solving this problem.
UE4-NeRF:Neural Radiant Field for Real-Time Rendering of Large-Scale Scene: As an avid fan of Unreal Engine and the games that have been produced by it, this is a really exciting work to me. There are companies like Luma and Volinga.ai that have a closed-source proprietary software for NeRF rendering in Unreal Engine, but this is the first work that open-sources it. I should note that their rendering process involves rendering sub-NeRFs in a partionined volume for efficiency purposes, but otherwise it follows a ray-marching procedure (ish).
Computer Vision
Computer vision (CV) was the field that introduced me to the world of machine learning, and I had a glimpse when I was a little boy building robots with my Arduino of what it looked like pre-AlexNet. Perhaps because NeurIPS itself is not focused on CV, I was rather surprised by the themes I noticed. There seems to be a much larger emphasis on video understanding and human-centric perception, although fairness and bias still remains an issue that has yet to be addressed.
Open vocabulary methods for segmentation and understanding of semantics in images involves being able to adapt to labels unseen during training. In essence, we want to be able to generalize our models past fixed class labels so they don’t have to be re-trained every few months. My understanding is that with vision-language models being a thing now, these methods only need to generate suitable embeddings use with these methods . A lot of works now focus on extending to 3D models as well . I’m curious though how these methods handle language ambiguity and different abstractions of describing something, and whether or not this limitation is bottlenecked by the model’s language capabilities. I did find that tries to address this in a hierarchical way.
Video understanding. I worked on a video understanding benchmark so I’m somewhat aware of the limitations in the field. Generally, video labels are quite difficult to procure, as they’re far more compositional and free-form, and they just take longer. At the same time, having models that can reason over videos is extremely useful because videos are the primary form of media consumed on the internet these days.Compared to language, videos take up much more memory, and finding associated labels through online scraping is hard. So an important work is to build up datasets and benchmarks. Additionally, even with multi-modal models, they have not been sufficiently trained to understand temporal aspects of a video like actions and long-term causal reasoning, which works like make first steps towards addressing.
Human Data and Perception.
I noticed some interest in human-centric perception, as we ideally want vision models to understand similarity the way we intuitively perceive it. In , they propose a margin loss that shapes the embedding space based on human similarity judgement data. Meanwhile, in , they focus on ego-centric data (video footage from the perspective of a human). We also want models to be more accurate when perceiving humans, which argues starts at the pre-training level. Lastly, there were a few papers on human-pose estimation, mainly for robustness on expressive poses and for improving accuracy on reconstructing the poses in 3D .
Fairness. Fairness and bias is a long-standing issue in computer vision that is primarily rooted in dataset selection. A key research question is understanding which factors like human appearance or geographical location are biased in our data. A further question is how to augment our data in the short term to mitigate these biases .
[Computer Vision] Interesting Papers
Segment Everything Everywhere All at Once: This is Microsoft’s alternative to Meta’s Segment Anything (SAM) model, with a focus on semantic-oriented text prompting for segmentation. I haven’t had the opportunity to compare the two, but they claim that their method captures semantics more accurately.
Diversifying Spatial-Temporal Perception for Video Domain Generalization: When you build a video understanding model, you of course want it to generalize to unseen domains. For video domains, however, which are high-dimensional and contain a lot of complicated structure, unless the data is perfectly diverse (requiring a lot of video data), you want to be able to filter out domain-specific cues from your training data and identify domain-invariant cues that will help as a prior for generalization. This work attempts to motivate how to identify these cues at a spatial and temporal level, and I think ideas from this work can be extended to other fields as well.
DropPos: Pre-Training Vision Transformers by Reconstructing Dropped Positions: Empirically, we have found that Vision Transformers (ViT) kind of suck at understanding positional encodings, i.e. they are sort of position invariant. In some cases this is a desirable property, but we do want these Vision Transformers to be spatially aware, so this paper offers a simple fix: in addition to standard ViT training, add a secondary objective to predict the position of the token/patch.
Patch N’ Pack: NaViT, A Vision Transformer for Any Aspect Ratio and Resolution: They train with token packing strategies used for language models, which involves feeding in multiple images (in tokenized patches) with varying resolutions during train time. They claim it works for arbitrary image resolutions, but I’m pretty sure it’s the resolution change they used during training. Regardless, it is an extremely useful work that applies to a wide range of visual tasks.
Color Equivariant Convolutional Networks: I’m a big fan of equivariance as an inductive bias, and this paper is no exception. We generally want to separate geometry and color in visual models, and this work builds a plug-in block for common convolutional neural network architectures to add color equivariant convolution operations. These layers are not insensitive to color variation; rather, they allow for sharing information about visual geometry across different colors.
Adversarial Attacks and Model Poisoning
Generally, adversarial attacks can be partitioned into two main classes: white box, where an attacker has access to the model weights (e.g. for any open-source models), and black-box, where an attacker can only use model outputs (e.g. attacking GPT4). I still think that most attacks are pretty domain-specific, so I’ve decided to generally separate the themes based on domain (e.g. language, vision, RL) rather than the type of attack (e.g. red-teaming, gradient-based, etc.) Lastly, this section is primarily dedicated to attacks that alter or manipulate the outputs of a model to be harmful or incorrect. There is another class of attacks that try to reconstruct training data using model outputs, but I decided to move that to the section on Privacy and Federated Learning.
Robustness vs. Performance & Speed is an important tradeoff when developing models and considering defense mechanisms against attacks. Adversarial defenses have extra overhead, especially those with certification (provable robustness within $\epsilon$-ball), so it is important to understand this tradeoff. I was only able to recall in this conference that tackles this issue.
Model Poisoning. Distinct from the other attacks, model poisoning involves slightly editing the training data to plant exploits or backdoor triggers into a model . It is possible that poisoned models are deployed in the wild, so you may not even have access to modify its internals. So essentially, you can either fine-tune the model or directly augment its outputs with noise to remove the poisoning.
Attacks on LLMs. Given the theme of multi-modal models, there has been a few works examining defenses for vision-language models against known attacks for language or vision models . However, given the discrete nature of token representations, simple black-box attacks using seemingly harmless tokens like an exclamation point are possible . Lastly, attacks and defenses against model poisoning were discussed .
Attacks on Images. Unlike language, raw image representations are high-dimensional and therefore easily susceptible to noise and perturbation effects. In , they propose a noise generator that transfers black-box attacks from one image model to another. These attacks and defenses have evolved over the years, but it’s still an open research question even on older datasets like ImageNet .
As an aside, there were lots of adversarial attack papers this year using specific attacks, targetting specific models (e.g. MARL , federated learning , graph neural networks ), or proposing specific defenses that are not reflected in the points above. I had a lot of trouble trying to categorize this section properly because of how diverse it is. This field is naturally reactive, as when someone comes up with a defense, someone will come up with an exploit (e.g. ), and vice-versa. Some works even try to theoretically motivate the nature and existence of completely robust models like , but overall, it was hard for me to pinpoint the direction of these works at this conference.
[Adversarial Attacks and Model Poisoning] Interesting Papers
Setting the Trap: Capturing and Defeating Backdoors in Pretrained Language Models through Honeypot: The strategy in this paper is really cool: basically, they first notice that backdoor triggers in poisoned models are “obvious”, in the sense that they appear in lower layers of the model in an obviously linearly separable way. Intuitively, this makes sense, as poisoned outputs are structurally out-of-distribution from “human language”. From here, they basically add these small “honeypot” layers (just a 1-layer transformer) with a classification head that purposefully get “poisoned” early on, and they use this auxiliary loss to weight the actual cross entropy loss. I think that is a really neat example of exploiting structure and abstract representations of data to achieve an effect.
Neural Polarizer: A Lightweight and Effective Backdoor Defense via Purifying Poisoned Features: Poisoned data generally looks like a regular image with some small perturbations or tiny trigger features, so this work looks into inserting learnable filters into a trained model that reverses and removes these features while acting as an identity map for everything else. The main issue I see with this approach is that you have to know the type of adversarial attacks against the model a priori, so a fixed filter needs to be updated when new attacks arise, i.e. there are no provable guarantees against general adversarial perturbations.
Knowledge Distillation and Memory Reduction Schemes
As much as we like scaling models, building smaller models that can run on accessible hardware is extremely important for the growth of our community. This section is mostly referring to scaling down models so they can run on inference time on smaller hardware, which is a matter of memory efficiency. TinyML A whole field of study is on ultra-low power ML: https://www.tinyml.org works take it a step further and try to deploy these models on embedded systems and micro-controllers . The three primary methods are weight quantizationWeight quantization involves using a lower-precision datatype for representing weights, which can reduce memory complexity by a multiplicative factor., pruningThere is extensive literature on network pruning, and it is actually quite complex. Pruning is literally taking out parts of the network (hence the name), but choosing what to take it is important. It is also important to select the time that you prune (before training, during training, after training), as this affects the performance and overhead of the pruning process. , and knowledge distillationKnowledge distillation involves taking a larger model and cloning its behavior in a smaller model, also known as "distilling". The idea is that a large models are often over-parameterized (there are benefits for training in this way), so once we have the model trained, we can cut down on its capacity by training a smaller model..
Memory Reduction Techniques. We generally are intered in tradeoffs for different memory reduction schemes such as pruning and quantization. In , they claim that quantization is almost always better unless you care about extreme compression. Similar to older work doing weight quantization for MLPs and CNNs, newer works at this conference do it for transformers .
Lottery Ticket Hypothesis (LTH)The lottery ticket hypothesis is the notion that dense neural networks contain a much smaller subnetwork that accounts for most of the performance. Finding these subnetworks through pruning would, in theory, preserve performance while significantly reducing memory. Read more from the original paper: https://arxiv.org/abs/1803.03635 . Following the original LTH, we want to understand what metrics (e.g. weight magnitude, gradient flow) and structure are useful for pruning modern architectures like LLMs, but this also depends on what we are pruning for. In they prune LLMs based on run-time bottlenecks for inference speed-ups, while in they focus on shrinking the model. Meanwhile, in convolutional neural networks, pruning based on empirics has been widely studied, so provide some theoretical motivation into better pruning based on the structure of the model.
Knowledge Distillation. Knowledge distillation (KD) is an approach for trying to force a small student model to mimic the output probabilities of a larger teacher model. KD has seen a wide array of techniques being used to preserve functionality of the teacher in the student, and many empirical experiments have been done in the past to evaluate the lower-bound capacity of student models. Nevertheless, the works at this conference were pretty unique. In they observe that student models have noisier features and attempt to de-noise them using diffusion. In , they motivate “concepts” in intermediate layers as an auxiliary signal for distillation. Finally, investigates whether properties like adversarial robustness, invariances, and generalization are transferred effectively during distillation.
[Memory Reduction] Interesting Papers
MCUFormer: Deploying Vision Transformers on Microcontrollers with Limited Memory: They push the modern limits of Vision Transformers on ultra-low cost systems, using neural architecture search (NAS) to search for a compute-optimal architecture while also writing a library for performing each inference-level computation in a Vision Transformer efficiently. I’m not that aware of the pre-existing literature in this space, but this is one of the first papers I’ve seen do it for Vision Transformers.
What Knowledge Gets Distilled in Knowledge Distillation?: Knowledge distillation is sort of this black-boxy approach where we try to get a small student model to be the same as a larger teacher model. It would be nice to know what kind of information easily transfers and even nicer to understand why, which this paper attempts to do. Most surprisingly, they find that white-box vulnerabilities in a teacher model transfer over to a student model despite being a different parameterization, which might be indicative of some structural similarities inherent to networks (it is inconclusive in this paper though). They try to motivate this transfer by a dimensionality argument to argue that the student model solution is unique, but honestly the argument is pretty weak because the assumptions are just generally untrue in almost any realistic problem where knowledge distillation is applied.
Polynomially Over-Parameterized Convolutional Neural Networks Contain Structured Strong Lottery Tickets: So I was really curious about this paper after reading through the abstract, because was is completely unclear to me how the Random Subset Sum problem Subset sum is a classic NP-hard problem in CS theory where a program must decide if there exists a subset of a set of integers that sums to a number $T$. The randomized version is a set of random variables, and the sum can now be off by an error $\epsilon$ with high probability. has anything to do with the existence of strong lottery tickets in an over-parameterized convolutional neural network.
Graph Neural Networks
Graph neural networks (GNN) were really popular this year! I wish I had a stronger understanding overall of GNNs, but unfortunately I just haven’t found any specific use cases for them in my own research. I am aware of their use-cases in structured prediction (e.g. molecular dynamics , social networks) but their unique design and the prevalence of graph problems has allowed this field of research to grow steadily. I couldn’t really pinpoint the major themes at this conference, but I learned a few things about what people are interested in.
Heterophily vs. Homophily. Earlier works with GNNs worked under the assumption of graph homophily, meaning similarly labelled nodes tend to be linked. This assumption neatly allows for even unsupervised methods to exploit graph structure when making predictions, but it is unclear what the impact of graph heterophily is on GNN performance . Thus, there has been work towards solving graphs under heterophily by focusing on non-local structure . In , they even try to rigorously characterize the properties and effects of these node-level relationships.
Unsupervised graph learning. Unsupervised learning is natural in graph problems because regardless of the problem domain, the graph itself provides extremely useful structural information that can be leveraged for a prediction. There is still a lot ongoing research into identifying and targetting useful structure in graphs, which includes (1).
Spatio-temporal prediction involves time-series forecasting over spatially-varying data. This problem is significantly harder than stock prediction type forecasting over tabular data because of the inherent high dimensionality and structure (local vs. global) present in spatial data. Thus, a class of works this year have emerged to study these problems using GNNs.
Encoding representations in graphs. Typically GNN methods represent nodes or links with some kind of embedding representation, so understanding the mechanisms that shape these representations is important .
Broadly speaking, a lot of advances in other fields that were discussed above are also active areas of research in GNNs (e.g. adversarial robustness , interpretability , multimodal ), so I expect to see a lot more advancements and use-cases of GNNs in the near future.
[GNN] Interesting Papers
Zero-One Laws of Graph Neural Networks: Zero-one laws generally study the limiting behavior of probabilities and show that they converges to $0$ or $1$. This paper proves equivalent zero-one laws for the outputs of certain classes of GNNs (e.g. boolean graph convolutional classifiers) as they get larger and larger. Practically speaking, I don’t currently see a use case for this kind of analysis, but it is cool nonetheless.
Unsupervised Learning for Solving the Travelling Salesman Problem: They use a simple unsupervised graph neural network with surrogate loss objectives that provably move towards the objective, that being minimizing the path cost and ensuring the path is a Hamiltonian cycle. I’m really curious to see future GNN works on approximating solutions to NP-hard/NP-complete problems based on derived surrogate objective functions.
Lovász Principle for Unsupervised Graph Representation Learning: Math researchers have done lots of incredible work in study global and local properties of graphs, and I expect that we will continue to see these results be useful in GNNs. Unsupervised learning for graph neural networks makes so much sense, because so much structure comes from the graph itself regardless of the domain it is describing. Having learned about Lovász numbers in an extremal combinatics course taught by Professor Alon Noga himself, it was cool to see them re-appear in an ML setting.
Privacy and Federated Learning
Trust in AI and the companies that build these AIs is extremely important. This year’s conference had a strong emphasis on privacy and data protection methods, as well as federated learning methods I would recommend read a survey paper or some online notes for a better explanation, but the basic idea behind federated learning is that in a distributed or cloud setting, we often want to use training data from clients (e.g. data on your mobile device), but we don't want to actually transfer this data to a centralized server for privacy reasons. Instead, we train a copy of the mobile locally, then transfer the gradients over to a server. Doing this at scale is quite difficult, as we are essentially doing sequences of delayed gradient updates. . Privacy is a fairly math-heavy topic (especially outside of ML) because it often considers worst-case scenarios with high probability, so a lot of the papers in this domain are quite technical.
Differential Privacy. Data privacy and anonymity can be mathematically guaranteed under differential privacy (DP) constraints, so adding these DP mechanisms to deep learning models with minimal overhead is an active area of research. Because DP is so mathematically sound, some work goes into studying DP under conditions common in machine learning while others go into applying DP to machine learning problems .
Machine Unlearning looks into removing sensitive information that was present in a trained model’s training distribution, effectively wiping the information from a model altogether . These techniques are useful for combatting copyright issues, but they are not well understood and can even lead to exploits .
Client attacks on Federated learning. Federated learning involves lots of gradient information from different worker sources. If an attacker got a hold of some workers (e.g. a malicious mobile device user), they could, in theory, inject harmful information into a federated learning system (similar to an adversarial attack, formally called a Byzantine attack). It is far easier in a federated learning setting for attackers to become clients, so many studies look into poisoning attacks and robust defenses against them through things like trust scores , zero order optimization with DP guarantees , and measuring divergence from the average .
Failure modes of federated learning. Federated learning does gradient updates out of sync, which means 1) theoretical analysis is a serious pain and 2) failure modes are more apparent. Furthermore, with extra mechanisms for privacy, an open research question is understanding the convergence guarantees of federated learning under various techniques and mechanisms .
[Privacy and Fed. Learning] Interesting Papers
Privacy Auditing with One (1) Training Run: We generally have to prove that an algorithm is differentially private (which is too hard in most cases!), but there are ways to audit or inspect empirically if an algorithm is differentially private. The problem is that DP is a probabilistic guarantee about the inclusion and exclusion of any data point, so we have to sample taking out data points. But sampling in the DP sense means re-training with or without data, which is extremely expensive. This work remarkably shows that they can audit with O(1) training runs under provable guarantees, which is a huge step from prior works. I skimmed the theoretical work, and it seems that they show the desired concentration bound of their method by showing that their process is stochasticly dominated by a binomial (a trick which appeared on my probability theory PSET!), and I’m excited to sit down and go through the math when I get the chance. Oh also, this paper won Outstanding Paper at this year’s conference.
Lockdown: Backdoor Defense for Federated Learning with Isolated Subspace Training: In federated learning, we want to defend against bad actors. But because we are adding gradients from many different sources to a centralized model, it is often hard to identify the source of these bad actors. In this work, they explicitly put sparsity constraints on the client to enforce training over a subspace of their data. The hope is that because these subspaces are generally disjoint, bad actors will not make updates in subspaces that good actors work over, making them easier to identify because they are isolated.
Training Private Models That Know What They Don’t Know: I think this paper is a pretty simple example of the type of performance and computational overhead that privacy constraints can induce. I’m hoping to see these kinds of works extended to larger models and more modern datasets, but they’re nonetheless very important.
Datasets, Benchmarks, Challenges
As NeurIPS is an AI-centric conference, there were datasets, benchmarks, and challenges for every topic above. There’s even a Datasets and Benchmarks track at NeurIPS. The more popular topics had more datasets (multimodal, LLM, etc.) and the datasets reflect the current needs of each field. A lot of the references put in earlier sections are dataset papers, so this section is going to be dedicated instead to some interest datasets I found while going through.
One thing I noticed though was a few papers on using synthetic data! While these are not dataset papers, they seem to imply that synthetic data works well enough for training! I’m curious to see if synthetic datasets will become more prevalent, especially given how easy they are to scale.
Interesting Datasets
Multimodal C4: An Open, Billion-scale Corpus of Images Interleaved with Text: This is the multi-modal variant of the original C4 dataset, which has been a standard in LLM pre-training since its release. Because of how prevalent this dataset is going to be, I think it’s at worth at least taking a look at the data that’s going to be a part of most of our generative AI in the near future.
BEDD: The MineRL BASALT Evaluation and Demonstrations Dataset for Training and Benchmarking Agents that Solve Fuzzy Tasks: MineRL is really cool. If you haven’t seen it already, I highly recommend taking a look, as Minecraft is the type of game that you would expect to be extremely complex for an AI to understand, but also simple enough that it seems feasible to eventually solve. This dataset provides a suite of labelled frame-action pairs and human labels that have been collected over the past two years and is extremely valuable for researchers working on this challenge.
GenImage: A Million-Scale Benchmark for Detecting AI-Generated Image: This is the closest thing to a synthetic dataset that I found at this year’s conference, but their focus was explicitly on creating AI-generated discriminators. I’m actually really curious to see if someone completely AI-generated a copy of the ImageNet dataset and trained models on it, how good would these models be? What kind of special differences, if any, could we find with these models and the originals?
Other Topics
The following sections are dedicated to topics that were either not as popular this year but are still broadly relevant or where I could not really get a sense of the central themes surrounding them. The main issue boils down to not having enough background on the topic, so I have to go through a few papers on the subject before comprehensively understanding what they’re doing. Regardless, they each had some interesting papers to highlight.
Interpretability and Explainable AI
Interpretability and explainable AI is really hard. We know that deep learning models tend to be a black box, and it’s generally because their inner mechanisms are too deep and intertwined with non-linearities that unless we make strong assumptions . I’d highly recommend going through the https://transformer-circuits.pub posts (start from the bottom), as they are extremely thorough and have been updated over time as well.
On the topic of mechanistic interpretabilityMechanistic interpretability is breaking down and reverse engineering a network to completely understand the inner workings and structure. Networks are often viewed as a computational graph composed of "circuits" that perform a specific function. I highly recommend looking at https://www.neelnanda.io/mechanistic-interpretability/quickstart, I don’t necessarily think the works at NeurIPS 2023 are reflective of all that is going on in the community, but there were some interesting papers to share nonetheless.
Scan and Snap: Understanding Training Dynamics and Token Composition in 1-layer They analyze 1-layer transformers without positional encoding or residual connections, so their analysis is a bit different than some earlier transformer mechanistic interpretability works that focus on residual streams. I haven’t gotten the chance to read through their analysis carefully, but they claim that under these conditions, the attention mechanism initially attends to “distinct” (uncommon among many pairs) key tokens and continues putting weight on the highest co-occuring distinct tokens, but eventually these weights get fixed after a certain time in the training process. The idea is that common tokens (i.e. words that probably don’t really add to the semantics) are not attended, naturally filtering them out as dataset sizes increase.
Reverse Engineering Self-Supervised Learning: They do self-supervised learning over CIFAR-100 and attempt to probe the intermediate layers, using the performance of probes over the course of training to justify their claims. Their conclusion is that self-supervised learning algorithms learn intermediate representations that are clustered based on semantic classes, and they show this using the performance of probes after accurate model performance, citing regularization constraints as the key driver.
The geometry of hidden representations of large transformer models: This work attempts to uncover common geometrical patterns, mainly intrinsic dimensionIntrinsic dimension is the lowest dimension manifold that can approximate a dataset up to some error. The reason why we care about intrinsic dimension is that high-dimensional data is very hard to work with and significantly increases the complexity and failure modes of a learning algorithm. In practice, however, high-dimensional data like images often contain structure that leads to a low intrinsic dimension. and a metric they call “neighborhood overlap”, across layers in transformer models. I am not familiar with the tool they use to measure intrinsic dimensionality and how accurate it is, but Figures 1 and 2 in their paper are pretty telling of the conclusions they draw.
Towards Automated Circuit Discovery for Mechanistic Interpretability: There has been quite a lot of work on studying toy networks in mechanistic interpretability, and this paper attempts to write out a concrete framework for doing mechanistic interpretability research. They then attempt to automate one of the steps, which is activation patching (varying inputs to an activation) to find circuits that exhibit a particular behavior.
Explaining Predictive Uncertainty with Information Theoretic Shapley Values: Shapley values https://en.wikipedia.org/wiki/Shapley_value are the solution to a cooperative game theory problem that satisfy a set of axioms. Informally (and related to explainable AI), they are a way of rigorously identifying which features contributed to a certain model prediction (although it is very expensive and scales poorly with training dataset sizes). In this paper, they motivate using a similar framework for measuring how training data features affect conditional entropy, which is directly linked to model uncertainty.
Theoretical and Practical Perspectives on What Influence Functions Do: Influence Functions (IF) measure the change in a model prediction when re-weighting training examples, effectively relating a model’s output behavior to the training data. More formally, for a training dataset $\mathcal{S}$, suppose we perturb the weighting of data point $x$ by $\delta$. Let $\mathcal{L}(x,\theta)$ be the loss of a model with parameters $\theta$ on datapoint $x$, and let $\theta_{x,\delta}$ be the minimizer of the perturbed dataset. For a test data point $z$, the influence function $I(z,x,\theta^*)$ is defined as
which is precisely the change in test loss through perturbation. Of course, this expression is not that interesting, but through Taylor expansion and assumptions about the loss function, it has an even nicer closed form solution (albeit with an inverse Hessian) in terms of $z,x$ and $\theta^*$, the minimizer of the original unperturbed dataset. For the aforementioned closed form solution to make sense, a lot of assumptions have to be made, which this paper tries to break down and explain why it may fail on real problems.
Implicit Bias
From a statistical learning perspective, overparameterized neural networks under gradient descent should exhibit overfitting. However, it has been shown empirically that overparameterization is generally helpful and leads to good generalization ability. Additionally, it is well known that there are many machine learning algorithms that provably generalize well on certain domains (e.g. support vector machines on linearly separable data). Implicit bias is the notion that overparameterized deep neural networks tend towards solutions that are similar to algorithms that generalize well as an explanation for their generalization ability. There has been some nice theoretical work in the field, some of which was present at NeurIPS 2023.
The Double-Edged Sword of Implicit Bias: Generalization vs. Robustness in ReLU Networks: Usually implicit bias is understood as a net positive for pushing models to generalize better, but this paper rigorously shows convergence towards solutions that are weak to adversarial $\ell_2$ perturbations. The analysis is limited to logistic loss or exponential loss on 2-layer ReLU networks but is entirely theoretical.
Implicit Bias of Gradient Descent for Logistic Regression at the Edge of Stability: If you’ve ever done the proof of gradient descent for $L$-smooth convex functions, you’re probably aware of the Descent Lemma and the $<1/L$ step size requirement. The edge of stability is this step-size range where this monotonicity guarantee is broken, but empirically models still seem to be able to converge. Interestingly, they show superiority of logistic loss over exponential loss theoretically in that at regardless of the step size chosen, logistic loss will converge eventually while exponential loss will diverge from the implicit bias using gradient descent.
Training Dynamics
For generic gradient-based learning in neural networks, we are often interested in understanding common patterns that emerge during different phases of the training process. Grokkinghttps://openreview.net/pdf?id=9XFSbDPmdW is an example of one type of phenomena, where (Nanda et al. 2023) show that in the overparameterized regime, models exhibit clear generalization behavior later into training despite maintaining low train error for a long time. Training dynamics that generalize across a certain class of models are difficult to identify, but discovering them will significantly improve our understanding of how to train models efficiently.
Phase Diagram of Early Training Dynamics in Deep Neural Networks: Effect of The Learning Rate, Depth, and Width: They motivate a bit about why sharpness matters as a metric for training dynamics, an analysis of how different hyperparameter choices affect how loss and sharpness over time. It’s a pretty interesting set of experiments in a toy setting, but I don’t know how observable the phases they observe are when you add all the tricks and complexities of modern deep learning.
Training shallow ReLU networks on noisy data using hinge loss: when do we overfit and is it benign?: Similar to the work above, it’s again a rigorous empirical analysis on a toy problem, but it’s important progress towards understanding what our models are learning during training.
Efficient Bayesian Learning Curve Extrapolation using Prior-Data Fitted Networks: I remember laughing when I first found this paper because it is literally inferencing what the training dynamics of another model will look like. It’s not the first work of its kind, but they incorporate the prior training curve data to do Bayesian inference of the training dynamics. I’m honestly also curious why regression doesn’t suffice.
Embodied AI
Embodied AI is a nascent field, but it focuses on building agents that can utilize multiple modalities. The field is set up to be a pre-cursor to the fabled AGI, but progress on this field hinges on the success of other fields like NLP, multi-modal learning, RL (although this is debated frequently). I didn’t see many works directly focusing on embodied AI, but I’m sure there will be many in the future.
Egocentric Planning for Scalable Embodied Task Achievement: This was the winning agent for the ALFRED challenge at CVPR 2023https://embodied-ai.org, where agents solve language-specified tasks in a first-person simulation. It’s a domain-specific agent, but I think what’s interesting is understanding how they choose to ground skills and actions for planning the next action.
Describe, Explain, Plan and Select: Interactive Planning with Large Language Models Enables Open-World Multi-Task Agents: I’ve seen quite a few LLM-based approaches to Minecraft, but this is the first to do zero-shot planning. To add game context, they have a visual-language model map visual observations to language, and they use these models to further decide which LLM-generated goals are more feasible conditioned on the visual state.
Neural Architecture Search
Neural architecture search (NAS) is a class of algorithms that automatically search for model parameters (not just hyperparameters!) to optimize for some metric and has been around for a while. NAS is used a lot in finding model parameters for ultra low-cost machines like in . It’s actually quite complicated how these algorithms work, and I’d recommend reading Lillian Weng’s bloghttps://lilianweng.github.io/posts/2020-08-06-nas/ to get a basic understanding of what people have done. The article is a bit old now, but I also don’t think the field itself has changed that much since.
EvoPrompting: Language Models for Code-Level Neural Architecture Search: Along the themes of can LLMs do everything, this paper looks into whether LLMs can aid in NAS. A lot of algorithms in NAS involve evolutionary search, so they query the LLM to generate the code for network parameters and mutate them over time through a soft-prompt tuning process.
Neural Operators
Most data is inherently discretized, or it lies on some well-defined finite-dimensional Euclidean space. However, there are many problems that involve learning functions (e.g. approximating partial differential equations) where we instead want to learn mappings between functional spaces. I think this paper https://arxiv.org/abs/2108.08481 explains it better than I will (and they write it in a way that’s quite intuitive to follow) but the basic idea is that the architecture and loss functions aren’t going to be any different than your standard neural network problem. The main difference is in framing, as our models are now acting over function spaces, so we treat the linear layers as linear integral operators on function spaces. The key benefit of working over function spaces is we no longer implicitly discretize our data, so varying resolutions of data do not affect our models, and there’s also some extra machinery that we can apply.
Convolutional Neural Operators for robust and accurate learning of PDEs: They prove similar universal approximation theorem guarantees for neural operators, but explicitly using convolutional layers. This is a pretty significant work in expanding neural operator use-cases, and they also show some examples of learning PDEs.
Variational Inference Methods
Bayesian methods are provably good at examining uncertainty in the posterior given your prior information and beliefs, but in practice they require approximating different intractible integrals in the closed for computation. More formally, suppose we want to compute the posterior $P(\theta|X)$, which represents the distribution over the parameters given our data. From Bayes rule,
The idea is that the denominator is intractible, but it’s actually a constant, so we can learn the posterior up to some normalization factor. So we instead will learn a simpler distribution \(Q(\mathbf{\theta})\) to approximate the posterior. The techniques for minimizing the difference between these distributions during optimization are well known and used frequently in applied ML.
Joint Prompt Optimization of Stacked LLMs using Variational Inference: This paper presents a very unique idea. Basically, if we stack langauge models (I had no idea people did this), you can treat the output of the $N-1$th language model as a latent parameterization of the $N$th language model, so we can perform variational inference to get a good estimate of the generative distribution of the $N$th language model. This theme of prompts being parameters is not new, especially if you’ve read earlier parts of this post, but the purpose of this work is to show that stacking language models can, in theory, provide better performance with a bit of extra machinery.
Quantum Information Theory
Quantum computers are notably faster at solving certain classes of problems (e.g. Shor’s algorithm for prime factorization), so if they end up replacing modern processors, we ideally want to ensure machine learning algorithms are efficient on them. While there were barely any papers on this topic, I did think it was interesting to look into.
On quantum backpropagation, information reuse, and cheating measurement collapse: The backpropagation relies on re-using intermediate computations to achieve a linear runtime, which almost the entirety of deep learning is built on. In quantum mechanics, however, measurements fundamentally change the quantum state describing a system, so storing copies of a quantum state for future use doesn’t really make sense. It’s a really unique and interesting challenge to balance the tradeoffs between quantum computing and classical computing (freshman year me was once interested in pursuing quantum computing, but alas), and this paper provides a unique solution to achieve backpropagation scaling, potentially enabling the development of scalable overparameterized neural networks on quantum computers.
Energy-based Models
Energy based models (EBM) are a different way to view and train probabilistic models based on learning an energy function, but they provably can represent a wide varieties of algorithms such as k-means and maximum likelihood estimationYann Lecun has made lots of talks about energy-based models. I found these slides online: https://cs.nyu.edu/~yann/talks/lecun-20060816-ciar-1-ebm.pdf. The key benefit is that we can ignore the intractible normalization constant computation needed for variational methods. Intuitively, I think it’s easiest to understand them in a contrastive learning framework, where an energy function $F: \mathcal{X} \times \mathcal{X} \rightarrow \mathbb{R}$ describes similarity between pairs of data points. GFlowNets are an exciting recent development of EBMs for generative modeling, and a few papers at this conference studied applications of them.
Energy Transformer: I think EBMs have the potential for a major breakthrough, but it really depends on whether they can reliably crack a really hard or popular problem. This work adapts EBMs for modern deep learning mechanisms like attention, and I’m interested to see if people take this further to things like LMs!
Curriculum Learning
Curriculum learning is the notion of learning simple tasks first before learning complex tasks. This intuitively makes sense in RL, where we want to learn simple skills before learning complex high-level strategies, but it is not limited to RL. I have always been kind of skeptic of curriculum learning because it is not well understood, but at the same time there have been some successful use cases of it.
Curriculum Learning With Infant Egocentric Videos: Funnily enough, this was a research direction I was interested in taking back in 2021, but I just never got access to the data to do it. I’m curious though if curriculum learning is particularly useful for self-supervised learning because it helps form the intermediate representation space in a nicer way or order, i.e. starting from representation space A, it’s a lot easier to move to B through gradient-based learning, so we should learn A first.
Anomaly Detection
Anomaly detection (AD)https://arxiv.org/abs/2007.02500 generally refers to detecting outliers or unexpected behavior in data. These methods are especially important for tasks where we want our models to be risk-averse. I was surprised to see quite a few works focused on this field at this year’s conference, but considering how diverse the applications are, it kind of makes sense. I’m not familiar with the field at all, but a few of them did pique my interest.
Unsupervised Anomaly Detection with Rejection: In my mind anomaly detection makes the most sense in as unsupervised or self-supervised learning problem because they inherently pop up in any domain. Their work deals providing strong theoretical guarantees for a general unsupervised algorithm that to reject low-confidence outputs.
Energy-Based Models for Anomaly Detection: A Manifold Diffusion Recovery Approach: One way of detecting anomalies is to have a general understanding of what your data should look like. In this work, the authors follow this idea by training an energy-based model to approximate the low-dimensional manifold that the training data lies on and use the energy function as a score for identifying anomalies.
Class Imbalance Approaches
For multi-class classification problems, we generally want a uniform distribution of class labels across the dataset so models do not converge to the most frequently occurring label with probability 1. Class imbalance is a long-standing problem in optimization-based methods, and there has been a lot of work to try and combat it (e.g. data augmentation to balance classes, sampling, new loss funcitons).
Simplifying Neural Network Training Under Class Imbalance: This paper makes some pretty strong claims: that just by tuning hyperparameters like batch sizes, label smoothing, optimizers, and data augmentation, we can combat class imbalance. The experiments they run are on fairly simple and old datasets, but this is pretty common for works that study general deep learning phenomena. I’m just not sure how well these observations hold at scale.
Continual Learning
I was interested in continual learning, also known as lifelong learning, when I first discovered machine learning. I think continual learning, like multimodal learning, is another important piece towards artificial general intelligence (AGI), but it is not as popular at the moment. The general idea is a learning framework that continues to adapt and learn over time, but well-known problems like catastrophic forgetting (model learns A then B. model will forget A.) and plasticity (how easily does a model learn something new) make continual learning extremely difficult. It is entirely possible that completely different paradigms are necessary for continual learning, but this is an active field of researchA useful introduction to pre-existing works is: https://wiki.continualai.org/the-continualai-wiki/introduction-to-continual-learning.
A Definition of Continual Reinforcement Learning: Reinforcement learning is explicitly a reward-maximizing algorithm under a fixed environment, which is sort of at odds with continual learning, where we want a policy to continue to adapt. This paper lays some of the groundwork for defining the necessary vocabulary and tools to approach continual learning in a reinforcement learning setting.
RanPAC: Random Projections and Pre-trained Models for Continual Learning: We ideally want to leverage pre-trained foundation models as a base for continual learning, but because we do not have a strong mechanistic understanding of these models, it is unclear how changing these weights over time in a continual learning sense will affect the model performance. This work is a first step into performing parameter updates on pre-trained models without forgetting.
Deep Learning Theory
Deep learning theory is specifically the study of deep neural network models, and generally centers around dense linear layers with activations (at least for now). The most well known result is probably the Neural Tangent Kernel (NTK) , which describes the behavior of networks as you take their layer width to infinity. Deep learning theory is an active area of research that I personally know little about, but at the very least, I’ve observed two common approaches at this conference that were used to study it. That being said, these are definitely not the only two tools used.
Kernel methods. This was formalized in the NTK work, but there is a provable duality between gradient descent in the infinite width limit and kernel gradient descent over the NTK as the kernel. Because of the rich theory present in kernel methods, we can apply these tools to study the behavior of neural networks as well.
Mean-field theory has historically been applied in probability theory and physics settings (thanks to my roommate Evan for explaining the basic idea to me), and is essentially a suite of tools for solving extremely high-dimensional and complex dynamics by approximating their behavior as an “average”. It has been applied extensively to deep learning theory as well for studying the behavior of infinite-width and infinite-depth networks as an alternative to viewing everything as kernels.
There’s a bit too much necessary background information that goes into the machinery required for deep learning theory for me to really understand any of these papers, so unfortunately I do not have anything to list for interesting papers (yet at least!). I can list some examples though: </d-footnote>
Bio-inspired AI
Artificial Intelligence is an extension of our desire to mimic biological intelligence (although I wish it wasn’t), so naturally we have a lot to gain by using ideas we discover from biology. I think over time we will always see a steady number of works on bio-inspired AI, but so far, I haven’t seen too many works of this type that really take off (e.g. spiking neural networks). Part of the problem is that we know very little about our brains and how they function, so potentially once we figure that out, we’ll start implementing those mechanisms in our AI!
Are Vision Transformers More Data Hungry Than Newborn Visual Systems?: I think it’s always sort of assumed that humans are far more data efficient than neural networks. They compare ViT performance on object recognition against newborn chicks with the same visual data and show that ViTs actually solved the same tasks. This paper is interesting, but I think the task is too simple and doesn’t capture the efficiency and task complexity tradeoff that would be more interesting to know.
Domain-specific applications of AI
There were a lot of very cool domain-specific applications of AIML at NeurIPS this year, most of
which was completely beyond me. Applications and datasets for the natural sciences were probably the most popular, especially related to protein modeling or protein functional prediction and molecules . There were also works in chemistry , law , and even circuit prediction!
Circuit As Set of Points: I wanted to highlight this paper because I thought it was zany. They literally treat circuit discovery as a point-cloud prediction problem instead of like a graph as in prior works. The authors say it’s to avoid pre-processing, so they’re literally just feeding in a raw circuit and treating it like a point cloud. Works like these are honestly really exciting, even if doesn’t end up become the standard method.
Reproducibility Studies
So I didn’t know reproducibility experiments were publishable at major AI conferences like NeurIPS, but I’m happy to discover that it is. This year featured quite a few reproducibility experiments for older works, and it seems like they all follow a kind of template of how they should be conducted. I have experience working with repositories that just do not align with the results of described in the papers, so I know how annoying it is to not know if a paper actually works. I saw this paper that attempts to reproduce the results of , but I found it funny because they basically roast their documentation and go into detail about the weaknesses in their experiments. With AI research rapidly growing, I think it’s getting more and more important that we set a bar for reproducibility.
Other Papers I Liked
Task Arithmetic in the Tangent Space: Improved Editing of Pre-Trained Models.: It seems that literally adding the weights of a bunch of fine-tuned experts on distinct downstream tasks can actually lead to a generalized model that solves all of them. From a linear algebra perspective, this only makes sense if the fine-tuning process pushes the weights into their own distinctive regions of the weight space. They motivate this sort of behavior as weight disentanglement and use it to fine-tune models for better weight addition properties.
Language-based Action Concept Spaces for Video Self-Supervised Learning.: I’ve recently been interested in more abstract representations of concepts like actions for building agents that can “think” using these representations. I think a lot of works on thinking in terms of actions and skills has been in terms of LLMs, but this work examines it from an encoder perspective.
The Grand Illusion: The Myth of Software Portability and Implications for ML Progress: I generally take for-granted the libraries that I use, so it was cool to see a study on the performance of popular frameworks across a variety of devices. These kinds of details are the things that I’ve been more and more interested in understanding, so I’m happy to see a paper like this at the conference.
Human-Guided Complexity-Controlled Abstractions: To develop agents that can interact with the environment the way we do, we first have to understand how to integrate our mental abstraction hierarchy into an agent’s. If you look at some of the papers I talked about earlier like , it is clear that people are interested in building action hierarchies for agents. This paper looks into understanding what level of abstraction or complexity is required to understand and execute actions for different types of tasks. I’m hoping to build a mental model of how we would go about building robust systems that can act in this way.
The Tunnel Effect: Building Data Representations in Deep Neural Networks: This paper provides some empirical insight into how data is represented throughout generic overparameterized neural networks. They propose this tunnel effect hypothesis, where the early layers of the network focus on linearly separable representations that focus on learning the actual task, while the later layers are just compression layers that harm generalization performance. They also suggest that regardless of model capacity (as long as it is sufficient), models will allocate the same amount of capacity to a specific task, which may also offer some insight into the implicit bias of models and why they tend not to overfit in the overparameterized regime.
Final Thoughts
This was a really rewarding process for me, not only from a knowledge standpoint. Before doing this little exercise, I was feeling a bit burnt out from school and learning in general. For a while, I had been thinking really hard researching how to inject language information for policy learning, but a lot of directions I had in mind just didn’t seem to make sense in the end. I had spent a lot of time reading in this specific direction, and I was a bit tired of seeing the same flavour of methods being applied. So it was honestly really refreshing to take a step back and reel in what people had been doing. I didn’t get a chance to go to NeurIPS 2023 (or any major conference for that matter) because of my courseload, but at least now I can say I know at least a little bit about what was going on there!
During this process I also compiled a list of open research questions I think are worth pursuing, which I may clean up in the future and put up. If you made it this far, thanks for giving it a read! It took a long time to synthesize these resources and figure out the structure of this article, so regardless of your background or prior knowledge, I hope this was at least somewhat useful for you!
Random Terms
I kept track of a list of terms that I had to Google while going through these abstracts. I probably
also ended up looking into more and forgot to put them in this list, but in case you’re interested,
here they are below. Edit: Ok so, this article ended up being way longer than intended, so instead if you want this list you should email me. My email is on my home page.
Citation
Just as a formality, if you want to cite this for whatever reason, use the BibTeX below.
@article{zhang2024neuripshighlights,
title = "Highlights of NeurIPS 2023 from Abstracts",
author = "Zhang, Alex",
journal = "Alex's Writing",
year = "2024",
month = "Jan",
url = "https://alexzhang13.github.io/blog/2024/neurips2023/"
}