⚠️ Work in Progress: These documentation are highly WIP and subject to large changes. It is helpful for minimally getting started, but will be updated as we go.
Recursive Language Models
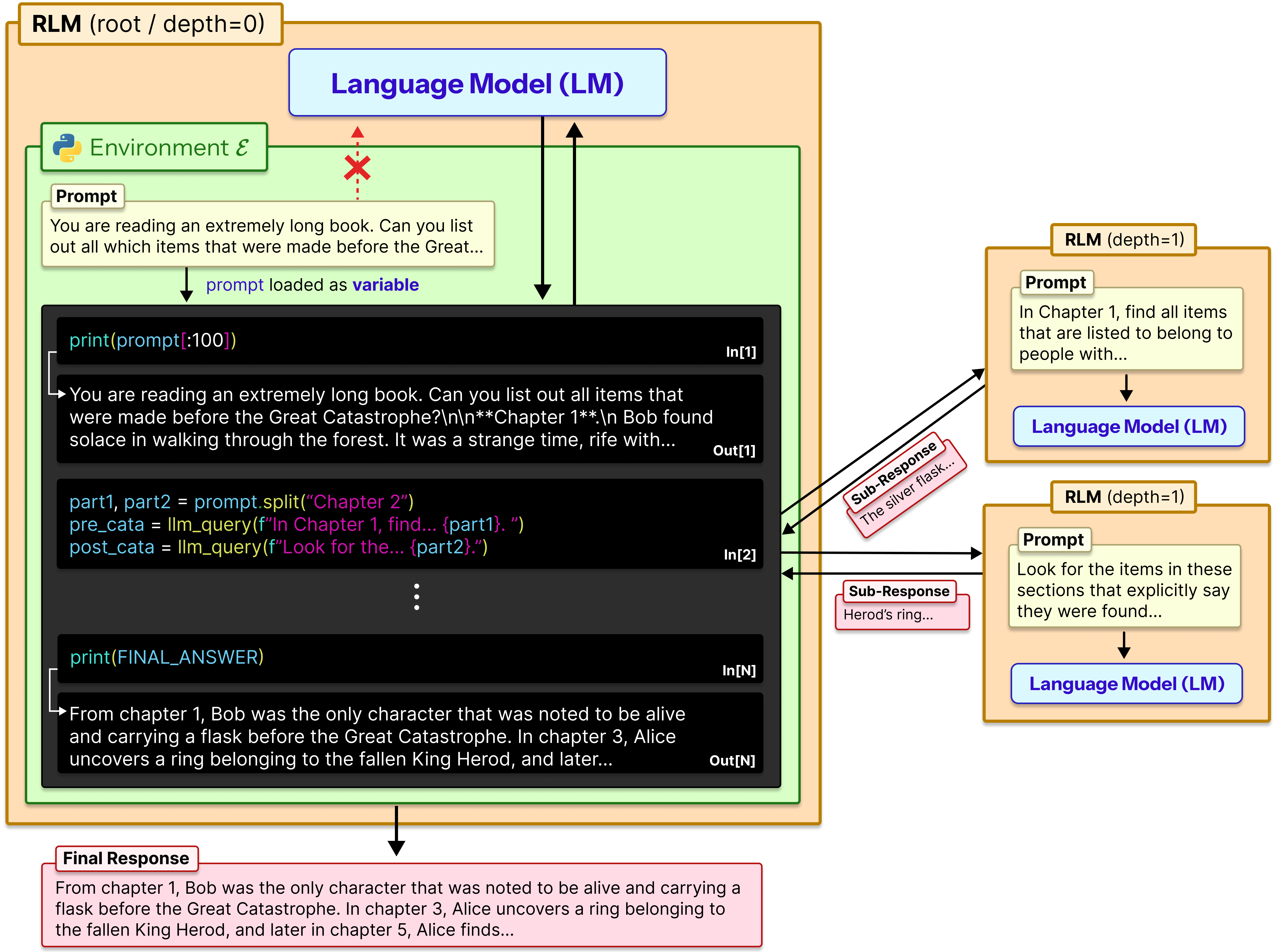
Recursive Language Models (RLMs) are a task-agnostic inference paradigm for language models to handle near-infinite length contexts by enabling the LM to programmatically examine, decompose, and recursively call itself over its input.
RLMs replace the canonical llm.completion(prompt, model) call with a rlm.completion(prompt, model) call. RLMs offload the context as a variable in a REPL environment that the LM can interact with and launch sub-LM calls inside of.
Installation
We use uv, but any virtual environment works.
We use uv for developing RLM. Install it first:
# Install uv (first time)
curl -LsSf https://astral.sh/uv/install.sh | sh
# Setup project
uv init && uv venv --python 3.12
source .venv/bin/activate
# Install RLM in editable mode
uv pip install -e .
# For Modal sandbox support
uv pip install -e . --extra modalOnce installed, you can import and use RLM in your Python code. See the Using the RLM Client section for detailed API documentation and examples.
Quick Start
These examples show how to initialize RLM with different LM providers. The RLM will automatically execute Python code in a REPL environment to solve the task. For more details on configuration options, see the Using the RLM Client documentation.
import os
from rlm import RLM
rlm = RLM(
backend="openai",
backend_kwargs={
"api_key": os.getenv("OPENAI_API_KEY"),
"model_name": "gpt-5-mini",
},
verbose=False, # print to logs
)
result = rlm.completion("Calculate 2^(2^(2^2)) using Python.")
print(result.response)REPL Environments
RLMs execute LM-generated Python code in a sandboxed REPL environment. We support two types of environments: non-isolated and isolated.
Non-isolated environments
Run code on the same machine as the RLM process:
local(default) — Same-process execution with sandboxed builtins. Fast but shares memory with host.docker— Containerized execution in Docker. Better isolation, reproducible environments.
Isolated environments
Run code on completely separate machines, guaranteeing full isolation:
modal— Cloud sandboxes via Modal. Production-ready, fully isolated from host.
rlm = RLM(
backend="openai",
backend_kwargs={"model_name": "gpt-5-mini"},
environment="local",
)See Environments for details on each environment's architecture and configuration.
Core Components
RLMs indirectly handle contexts by storing them in a persistent REPL environment, where an LM can view and run code inside of. It also has the ability to sub-query (R)LMs (i.e. with llm_query calls) and produce a final answer based on this). This design generally requires the following components:
- Set up a REPL environment, where state is persisted across code execution turns.
- Put the prompt (or context) into a programmatic variable.
- Allow the model to write code that peeks into and decomposes the variable, and observes any side effects.
- Encourage the model, in its code, to recurse over shorter, programmatically constructed prompts.
Citation
@misc{zhang2025recursivelanguagemodels,
title={Recursive Language Models},
author={Alex L. Zhang and Tim Kraska and Omar Khattab},
year={2025},
eprint={2512.24601},
archivePrefix={arXiv},
}